







本文转自Fun言网:https://funyan.cn/p/6363.html
第一步
在https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.8.12中查找和自己es版本相关的分词器版本
第二步
将分词器解压到es的安装目录下的plugins/ik目录下,如果没有ik目录就新建ik目录
第三步
重启es,此时分词器已经安装成功,此时进行测试
POST 索引名/_analyze
{
"analyzer":"ik_max_word",
"text":"如何学习java"
}
结果
{
"tokens": [
{
"token": "如何",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
}
,
{
"token": "学习",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
,
{
"token": "java",
"start_offset": 4,
"end_offset": 8,
"type": "ENGLISH",
"position": 2
}
]
}
第四步
在Java实体类中的需要分词的字段上添加下面注解
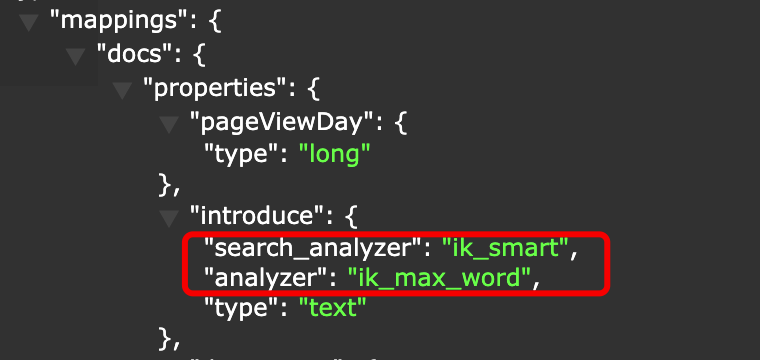
@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer="ik_smart")
index:是否对该字段分词,默认true。
analyzer:指定插入时的分词模式,一般为ik_max_words。
type:字段类型。
store:是否存储该字段,默认值为false。
searchAnalyzer:指定查询时的分词模式,一般为ik_smart。
第五步
删除之前创建的索引,然后重新调用es创建新的索引,此时发现新的mapping里面已经有分词器信息
本文转自Fun言网:https://funyan.cn/p/6363.html















 1874
1874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









