







我们的需求是利用python爬虫爬取豆瓣电影排行榜数据,并将数据通过pandas保存到Excel文件当中(步骤详细)
我们用到的第三方库如下所示:
import requests
import pandas as pd
import json
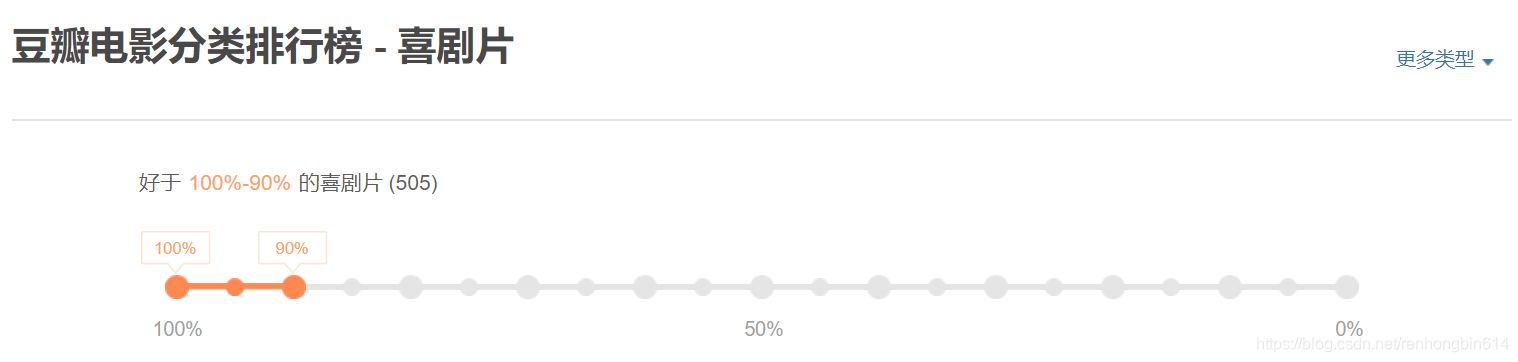
下面我们看一下豆瓣电影排行榜的信息(以喜剧电影排行榜为例)
思路步骤:
注意:之前我们写过爬取链家房源数据的爬虫(见下方),通过观察我们发现,链家网址进行翻页是在url地址上更改页数数字即可,所以当时用的xpath。那么由于豆瓣电影排行榜翻页的时候只能通过下拉的方式,而不能通过更改url地址页数,所以这里我们就通过另外一种简单的方式进行爬取。
xpath爬取链家房源数据
1、



分析url地址,我们发现,其中圈红的start值一直在变化,通过观察我们发现每组20个数据,一共有505个数据,所以可以通过format()方法获得一个url列表。
start_url = 'https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start={}&limit=20'
url_lists = [start_url.format(i) for i in range(0,505,20)]
2、
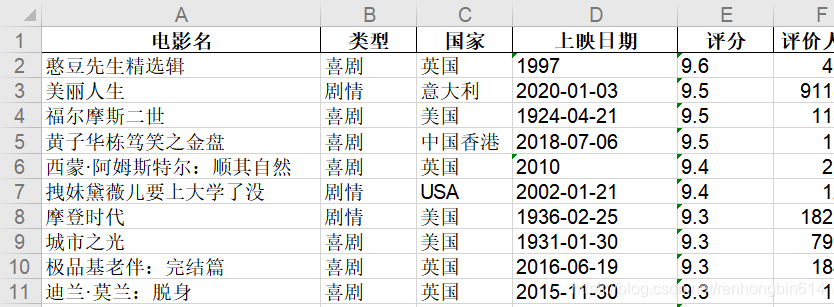
确定我们要提取的电影信息如下:电影名,类型,国家,上映日期,评分,评价人数,创建一个空的DataFrame对象data。
data = pd.DataFrame(columns=['电影名', '类型', '国家', '上映日期', '评分', '评价人数'])
3、
获取请求头headers。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}
4、
遍历之前获取到的url列表,发送请求获取响应字符串,并转换成json格式得到新的对象det_dicts,再遍历det_dicts,创建一个空字典,将所需信息以键值对形式全都保存到空字典中,创建一个新的DataFrame对象df,将字典传入df中,并通过append方法将df添加到之前的空DataFrame对象data中。
for url in url_lists:
response = requests.get(url,headers=headers)
html_str = response.content.decode()
det_dicts = json.loads(html_str)
for det in det_dicts:
new_info = {}
new_info['电影名'] = det['title']
new_info['类型'] = det['types'][0]
new_info['国家'] = det['regions'][0]
new_info['上映日期'] = det['release_date']
new_info['评分'] = det['score']
new_info['评价人数'] = det['vote_count']
df = pd.DataFrame(new_info,index=[0])
data = data.append(df)
5、
将data通过to_excel()方法写入到Excel文件中。
data.to_excel('./爬取豆瓣喜剧电影排行.xls',index=False)
得到的结果部分如下所示
详细代码如下所示
import requests
import pandas as pd
import json
start_url = 'https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start={}&limit=20'
url_lists = [start_url.format(i) for i in range(0,505,20)]
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}
data = pd.DataFrame(columns=['电影名', '类型', '国家', '上映日期', '评分', '评价人数'])
for url in url_lists:
response = requests.get(url,headers=headers)
html_str = response.content.decode()
det_dicts = json.loads(html_str)
for det in det_dicts:
new_info = {}
new_info['电影名'] = det['title']
new_info['类型'] = det['types'][0]
new_info['国家'] = det['regions'][0]
new_info['上映日期'] = det['release_date']
new_info['评分'] = det['score']
new_info['评价人数'] = det['vote_count']
df = pd.DataFrame(new_info,index=[0])
data = data.append(df)
data.to_excel('./爬取豆瓣喜剧电影排行.xls',index=False)















 5124
5124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











