









一.概述
charCNN不同于TextCNN,不同语言级别(字符级char-level、词级word-level、句子级sentence-level)对应不同的策略,论文Character-Aware Neural Language Models(Yoon Kim)可以看成CRNN(cnn-lstm)结构,论文地址:Character-Aware Neural Language Models
CNN在图像领域的成功,像素真式一个有意思的东西,NLP也不甘落后,charCNN_kim这篇paper的重点在于使用CNN提取字符级特征作为特征,Highway-Networks处理后,可以看成另外一种形式的Embedding,其目的在于解决word级别低频词embedding效果不好问题。因为char级别的,汉字,加上字母、数字、其他语言等,大约就是20000左右,oov问题并不突出。
1. CNN,不同于text-cnn,对于n-gram的提取,CNN卷积采用6-7个卷积核,small为
[[25, 1], [50, 2], [75, 3], [100, 4], [125, 5], [150, 6]]2. Highway-Networks,就是个简单公式,防止梯度爆炸等,实验时候这个老出错,后来发现是输入维度不对。
公式
1. s = sigmoid(Wx + b)
2. z = s * relu(Wx + b) + (1 - s) * x3. LSTM(长短时记忆神经网络),没什么可说的,你可以用Bi-LSTM,也可以用LSTM,或者是GRU等递归神经网络
4. 实现的charCNN模型github地址: https://github.com/yongzhuo/Keras-TextClassification/tree/master/keras_textclassification
5. 论文charCNN网络结构
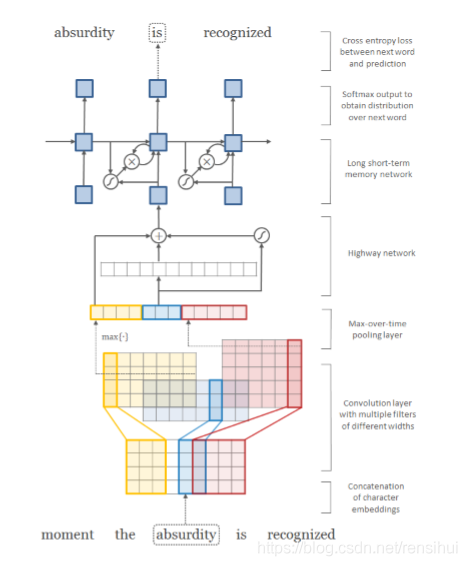
6. paper模型超参

二.代码实现
1. 代码实现也不难,CNN、LSTM很容易,无论keras还是tensorflow,就是Highway-Networks从keras2中删掉了,需要重写,虽然简单,但是超级坑。
2. github上代码地址:https://github.com/yongzhuo/Keras-TextClassification/tree/master/keras_textclassification
3. 主要代码附上:
def create_model(self, hyper_parameters):
"""
构建神经网络
:param hyper_parameters:json, hyper parameters of network
:return: tensor, moedl
"""
super().create_model(hyper_parameters)
embedding_output = self.word_embedding.output
embedding_output = Reshape((self.len_max, self.embed_size, 1))(embedding_output) # (None, 50, 30, 1)
embedding_output = Concatenate()([embedding_output for i in range(self.len_max_word)]) # (None, 50, 30, 21)
embedding_output = Reshape((self.len_max, self.len_max_word, self.embed_size))(embedding_output) # (None, 50, 21, 30)
conv_out = []
for char_cnn_size in self.char_cnn_layers:
conv = Convolution2D(name='Convolution2D_{}_{}'.format(char_cnn_size[0], char_cnn_size[1]),
filters=char_cnn_size[0],
kernel_size= (1, char_cnn_size[1]),
activation='tanh')(embedding_output)
pooled = MaxPooling2D(name='MaxPooling2D_{}_{}'.format(char_cnn_size[0], char_cnn_size[1]),
pool_size=(1, self.len_max_word - char_cnn_size[1] + 1)
)(conv)
conv_out.append(pooled)
x = Concatenate()(conv_out) # (None, 50, 1, 1100)
x = Reshape((self.len_max, K.int_shape(x)[2] * sum(np.array([ccl[0] for ccl in self.char_cnn_layers]))))(x) # (None, 50, 1100)
x = BatchNormalization()(x)
# Highway layers
for hl in range(self.highway_layers):
# 两个都可以,第二个是我自己写的
# x = TimeDistributed(Highway(activation='sigmoid', transform_gate_bias=-2, input_shape=K.int_shape(x)[1:2]))(x)
x = TimeDistributed(Lambda(highway_keras, name="highway_keras"))(x)
# rnn layers
for nrl in range(self.num_rnn_layers):
x = Bidirectional(GRU(units=self.rnn_units, return_sequences=True,
kernel_regularizer=regularizers.l2(0.32 * 0.1),
recurrent_regularizer=regularizers.l2(0.32)
))(x)
# x = GRU(units=self.rnn_units, return_sequences=True,
# kernel_regularizer=regularizers.l2(0.32 * 0.1),
# recurrent_regularizer=regularizers.l2(0.32)
# )(x)
x = Dropout(self.dropout)(x)
x = Flatten()(x)
output = Dense(units=self.label, activation=self.activate_classify)(x)
self.model = Model(inputs=self.word_embedding.input, outputs=output)
self.model.summary(120)三.实现结果
准确率还行,不过也不要报太大希望,RNN还是太慢了呀,140万语料,11G的GPU(RTX2080TI),一个epoch也要1个半小时,双层highway networks, 双层lstm,说多了都是泪呀。
希望对你有所帮助!














 2278
2278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









