






问题
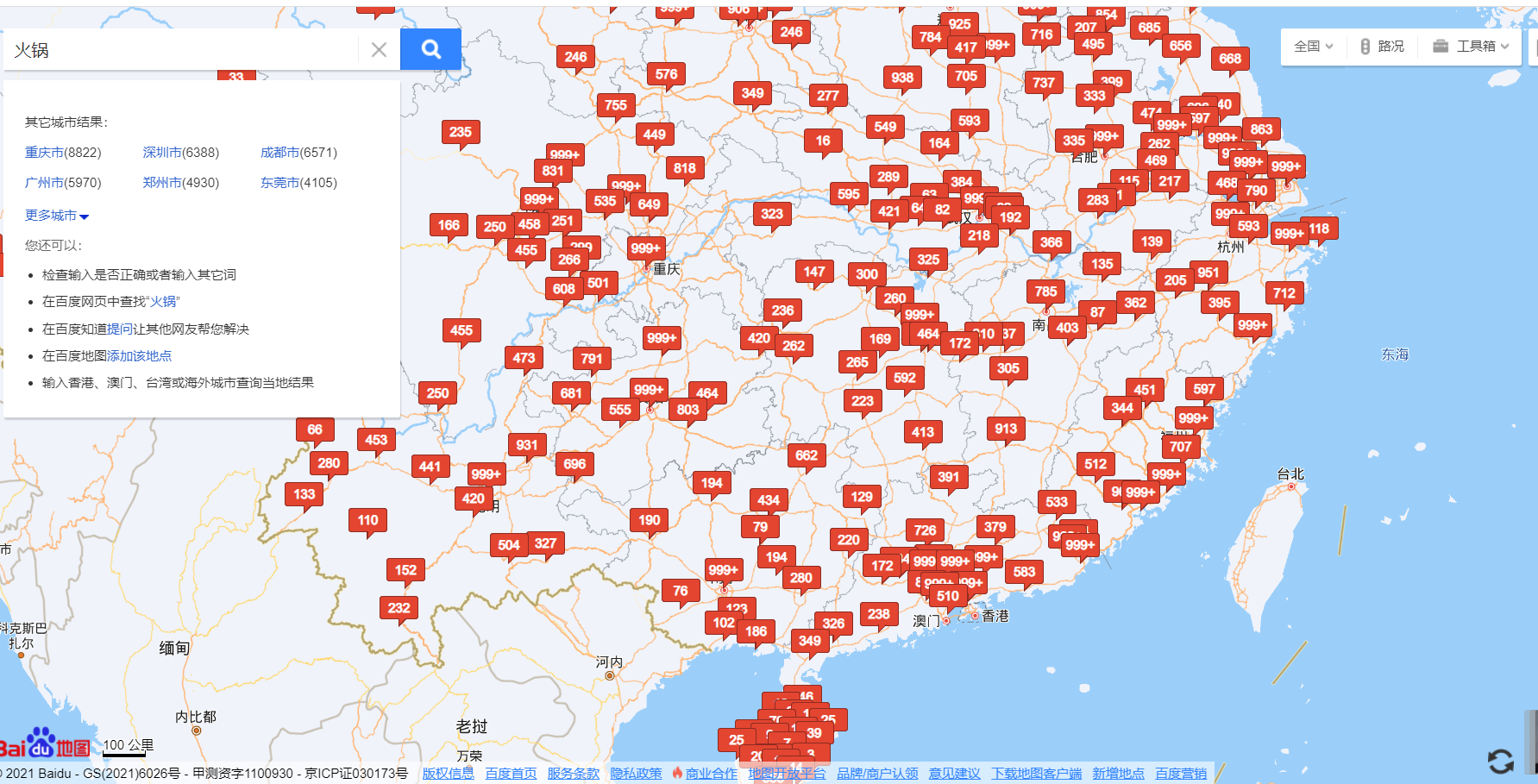

https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=s&c=1&wd=%E7%81%AB%E9%94%85&da_src=pcmappg.map&on_gel=1&l=5&gr=2&b=(9677951.714231128,1730014.8154582584;13993877.97804421,4767148.112215612)&pn=0&auth=W5zNFT6g0%40%40TZT24DwfQCHL0B35%40g6SWuxLBNERBNLHtBalTBnlcAZzvYgP1PcGCgYvjPuVtvYgPMGvgWv%40uVtvYgPPxRYuVtvYgP%40vYZcvWPCuVtvYgP%40ZPcPPuVtvYgPhPPyheuVtvhgMuxVVty1uVtCGYuNtJLmCUZIdbTbNdB9A1cv3uVtGccZcuVtPWv3GuBtR9KxXwPYIUvhgMZSguxzBEHLNRTVtcEWe1GD8zv7u%40ZPuzteL1wWveuBt0iyfixAN152T1N51wquTTGLFfy9GUIsxC2wvaaZyY&seckey=6VKbNl%2BEMipcFlMIHjKIybzZLU9kk4sn5QN4bSBp2q0%3D%2CWG3XhzBOLtVO6h67UdvVmni8%2B3Bln8Ck4hk87v17WepaJJGH6dhpwmT6%2BDFFFxM0PzMMjvdyWI3GVS3KZF3h7VAmP8Uf%2FgHuvAYxhdl%2Bg3tTRJP61I1dKdR8CStOr3FOveukTMBWS1MCb27ID9RcqkXg%2FooVgmwzXbrwkgpjDldMXr3TwWmVV01n8v032nwY&device_ratio=2&tn=B_NORMAL_MAP&nn=0&u_loc=11869559,3030727&ie=utf-8&t=1637483768544&newfrom=zhuzhan_webmap
python爬虫
其实这次的爬虫很简单,长话短说
import requests
import pandas as pd
url = "https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=s&c=1&wd=%E7%81%AB%E9%94%85&da_src=pcmappg.map&on_gel=1&l=3&gr=1&b=(1174135.838217428,-5261081.159856323;14879172.105572648,10545685.908882445)&pn=0&auth=RLVSxNUz96XX1SYEcDCQSa4cR9aNvG96uxLBNExRNBTtA%3Dk6Amkbz8yvYgP1PcGCgYvjPuVtvYgPMGvgWv%40uxtw8055yS8v7uvYgP%40vYZcvWPCuVtvYgP%40ZPcPPuVtvYgPhPPyheuVtvhgMuxVVty1uVtCGYuxtE20w5V198P8J9v7u1cv3uztexZFTHrwzDv5ooioGdFPWv3GuVtPYIuVtPYIUvhgMZSguxzBEHLNRTVtcEWe1aDYyuVt%40ZPuzteL1wWveuztghxehwz4DPGz6DB4vjnOOAGzu%3D%3D8xC&seckey=7W5%2BIhO%2B9UrQ2WX2V%2BE0KmrfRnfNjQ0Xg0YEc5Iu%2Fz8%3D%2CszNX4bkys1gfYd65mAyKk1JSwTAQrk4A7iOGDLHckvKsmeFsawFeIWwGdwoAZuFMnHE%2BuWYgg3T%2FtZUz1hiMdKD0LrtR1TZBjQm%2Fyt5c7mduGqYLkdWpXM0c%2FJ%2FgiJFFtmSDOxvMAiCeWh%2BUqQNFnJfZBvzsRINMb8JuZYiO%2Fiq3KhhPoNAWt%2BYfDFOJdd3u&device_ratio=2&tn=B_NORMAL_MAP&nn=0&u_loc=11871969,3028287&ie=utf-8&t=1637418793652&newfrom=zhuzhan_webmap"
payload={}
headers = {
'Cookie': 'BAIDUID=C715F06E5DE06ABAF85A3CE841D57766:FG=1'
}
response = requests.request("GET", url, headers=headers, data=payload)
# print(response.json())
data = response.json()['more_city']
df = pd.DataFrame(data)
print(df)
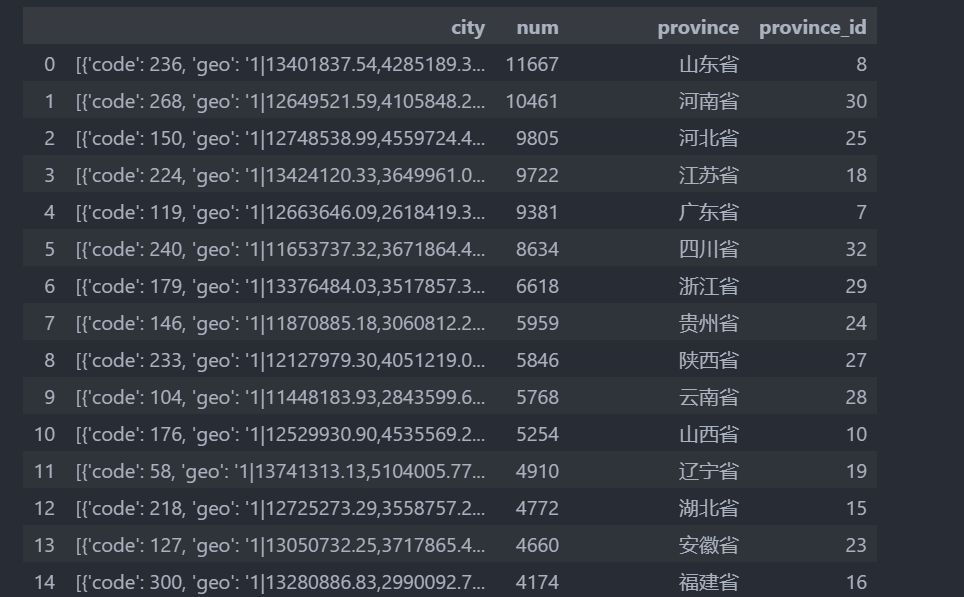
pandas处理数据
我们需要对city列处理

我们头脑一定要清晰,我以前做了蛮久,但是现在一些就这次来了,我们的思路,分列,行列转换,然后提取数据。
导入模块
import numpy as np
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.globals import ChartType,SymbolType
%matplotlib inline
读取数据
data = pd.read_excel('2021-11-20-23-44-7-79835853400-火锅数据.xlsx')
df = pd.DataFrame(data['city'])
df.head()

数据分列
df = df['city'].str.split(',', expand=True)
df.shape
行列转换
表格转一列
df_stack = df.stack()
df_stack = pd.DataFrame(df_stack)
print(df_stack.head(10))
print(df_stack.shape)
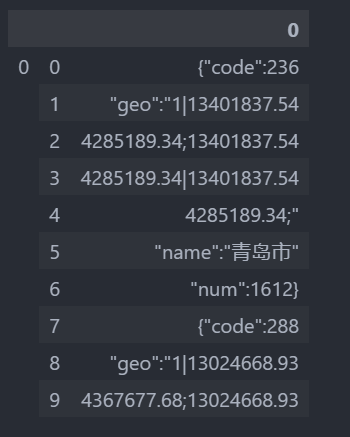
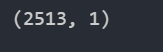
行列转换
我们这里解释一下,2513×1,我们要转换成359×7。
df_temp =pd.DataFrame(np.reshape(df_stack.to_numpy(), (359,7)))
df_course = df_temp[[0,5,6]]
正则表达式提取
df_effect = df_course[5].str.extract('([\u4e00-\u9fa5]+)', expand=True)
df_effect['Name'] = df_effect[0]
df_effect.drop(0, axis=1, inplace=True)
df_effect['Code'] = df_course[0].str.extract('([0-9]*$)', expand=True)
df_effect['Num'] = df_course[6].str.extract('(\d+.*\d+)', expand=True)
df_effect.head()
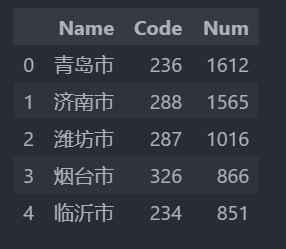
导出数据
df_effect.to_excel('2021-11-20-23-44-7-79835853400-火锅数据-效果.xlsx')
省份数据可视化
省份数据提取
data.head()
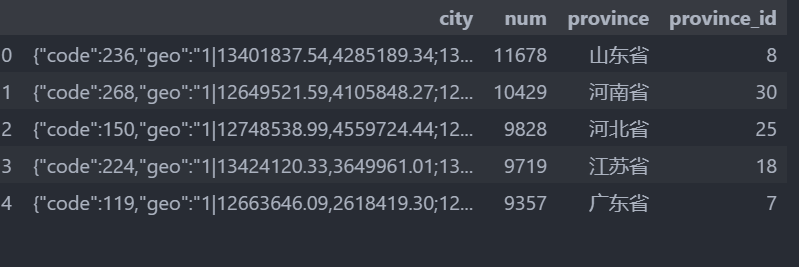
df_province = data[['province','province_id','num']]
df_province.head()
df_province.to_excel('火锅_省份数据.xlsx')
pyecharts数据可视化
我们这次选择pyecharts来数据可视化,注意Pyecharts里面省份要一样,比如上海市不能识别,只有上海才可以识别。
df_province['province'] = df_province['province'].str.replace('省','')
df_province['province'] = df_province['province'].str.replace('市','')
df_province['province'].replace({'内蒙古自治区':'内蒙古','广西壮族自治区':'广西','新疆维吾尔自治区':'新疆',
'宁夏回族自治区':'宁夏','西藏自治区':'西藏'},inplace=True)
还有Pyecharts只识别列表数据,所以我们需要数据类型改变。
province = df_province['province'].tolist()
num = df_province.num.tolist()
print('地区',province)
print('数量',num)

我们需要一一对应
geo_test_data = list(zip(province,num))
print(geo_test_data)
绘制地图
from pyecharts import options as opts
from pyecharts.charts import Map
map=Map()
map.add('频数',geo_test_data,'china')
map.set_global_opts(
title_opts=opts.TitleOpts(title='全国火锅省份分布图'),
visualmap_opts=opts.VisualMapOpts(min_=100,max_=15000,split_number=5,is_piecewise=True)) #图例是否分段
map.render_notebook()
map.render("全国火锅分布图.html")
我们来看看效果。

Tableau数据可视化
其实python来数据可视化比较痛苦的,所以我们在tableau里面数据可视化一样,好痛苦。

总结
太痛苦,要不是为了钱,钱到了,当然要记录一下,不记录的话,以后又忘记了,那怎么办,而且还可以传播出去。还有数据有缺失,不一定准确,数据来源于百度。强烈抗议osm把湾湾划出我国,这个不代表本人观点,祖国万岁。















 2244
2244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









