









[转自:
http://www.cppblog.com/superKiki/archive/2010/05/15/115421.html]
后缀数组
【后缀数组是处理字符串的有力工具。后缀数组是后缀树的一个非常精巧的替代品,它比后缀树容易编程实现,能够实现后缀树的很多功能而时间复杂度也并不逊色,而且它比后缀树所占用的内存空间小很多。可以说,在信息学竞赛中后缀数组比后缀树要更为实用。】
1.1、基本定义
子串:字符串S的子串r[i..j],i≤j,表示r串中从i到j这一段,也就是顺次排列r[i],r[i+1],…,r[j]形成的字符串。
后缀:后缀是指从某个位置i开始到整个串末尾结束的一个特殊子串。字符串r的从第i个字符开始的后缀表示为Suffix(i),也就是Suffix(i)=r[i..len(r)]。
大小比较:关于字符串的大小比较,是指通常所说的“字典顺序”比较,也就是对于两个字符串u、v,令i从1开始顺次比较u[i]和v[i],如果u[i]=v[i]则令i加1,否则若u[i]
<
<script type="math/tex" id="MathJax-Element-446"><</script>v[i]则认为u
<
<script type="math/tex" id="MathJax-Element-447"><</script>v,u[i]
>
v[i]则认为u
从字符串的大小比较的定义来看,S的两个开头位置不同的后缀 u和v进行比较的结果不可能是相等,因为 u=v的必要条件len(u)=len(v)在这里不可能满足。
后缀数组:后缀数组SA是一个一维数组,它保存1..n的某个排列SA[1],SA[2],……,SA[n],并且保证 Suffix(SA[i]) < <script type="math/tex" id="MathJax-Element-457"><</script>Suffix(SA[i+1]),1≤i < <script type="math/tex" id="MathJax-Element-458"><</script>n。也就是将S的n个后缀从小到大进行排序之后把排好序的后缀的开头位置顺次放入SA中。
名次数组:名次数组Rank[i]保存的是Suffix(i)在所有后缀中从小到大排列的“名次”。
简单的说,后缀数组是“排第几的是谁?”,名次数组是“你排第几?”。容易看出,后缀数组和名次数组为互逆运算。如图1所示。

设字符串的长度为n。为了方便比较大小,可以在字符串后面添加一个字符,这个字符没有在前面的字符中出现过,而且比前面的字符都要小。在求出名次数组后,可以仅用O(1)的时间比较任意两个后缀的大小。在求出后缀数组或名次数组中的其中一个以后,便可以用O(n)的时间求出另外一个。任意两个后缀如果直接比较大小,最多需要比较字符n次,也就是说最迟在比较第n个字符时一定能分出“胜负”。
1.2、倍增算法
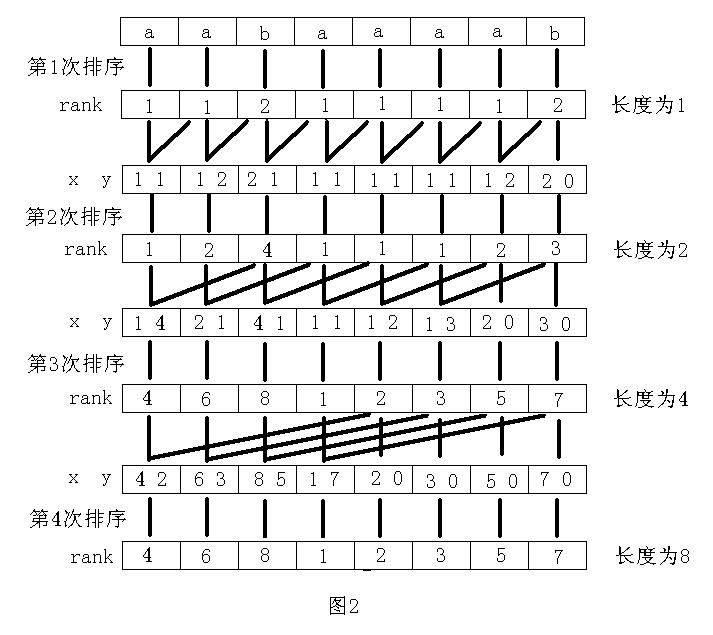
倍增算法的主要思路是:用倍增的方法对每个字符开始的长度为2k的子字符串进行排序,求出排名,即rank值。k从0开始,每次加1,当2k大于n以后,每个字符开始的长度为2k的子字符串便相当于所有的后缀。并且这些子字符串都一定已经比较出大小,即rank值中没有相同的值,那么此时的rank值就是最后的结果。每一次排序都利用上次长度为2k-1的字符串的rank值,那么长度为2k的字符串就可以用两个长度为2k-1的字符串的排名作为关键字表示,然后进行基数排序,便得出了长度为2k的字符串的rank值。以字符串“aabaaaab”为例,整个过程如图2所示。其中x、y是表示长度为2k的字符串的两个关键字。
具体实现:
int wa[maxn],wb[maxn],wv[maxn],ws[maxn];
int cmp(int *r,int a,int b,int l)
{return r[a]==r[b]&&r[a+l]==r[b+l];}
void da(int *r,int *sa,int n,int m)
{
int i,j,p,*x=wa,*y=wb,*t;
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[x[i]=r[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[x[i]]]=i;
for(j=1,p=1;p<n;j*=2,m=p)
{
for(p=0,i=n-j;i<n;i++) y[p++]=i;
for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j;
for(i=0;i<n;i++) wv[i]=x[y[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[wv[i]]]=y[i];
for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;
}
return;
}
待排序的字符串放在r数组中,从r[0]到r[n-1],长度为n,且最大值小于m。为了函数操作的方便,约定除r[n-1]外所有的r[i]都大于0,r[n-1]=0。函数结束后,结果放在sa数组中,从sa[0]到sa[n-1]。
函数的第一步,要对长度为1的字符串进行排序。一般来说,在字符串的题目中,r的最大值不会很大,所以这里使用了基数排序。如果r的最大值很大,那么把这段代码改成快速排序。代码:
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[x[i]=r[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[x[i]]]=i;
这里x数组保存的值相当于是rank值。下面的操作只是用x数组来比较字符的大小,所以没有必要求出当前真实的rank值。
接下来进行若干次基数排序,在实现的时候,这里有一个小优化。基数排序要分两次,第一次是对第二关键字排序,第二次是对第一关键字排序。对第二关键字排序的结果实际上可以利用上一次求得的sa直接算出,没有必要再算一次。代码:
for(p=0,i=n-j;i<n;i++) y[p++]=i;
for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j;
其中变量j是当前字符串的长度,数组y保存的是对第二关键字排序的结果。然后要对第一关键字进行排序,代码:
for(i=0;i<n;i++) wv[i]=x[y[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[wv[i]]]=y[i];
这样便求出了新的sa值。在求出sa后,下一步是计算rank值。这里要注意的是,可能有多个字符串的rank值是相同的,所以必须比较两个字符串是否完全相同,y数组的值已经没有必要保存,为了节省空间,这里用y数组保存rank值。这里又有一个小优化,将x和y定义为指针类型,复制整个数组的操作可以用交换指针的值代替,不必将数组中值一个一个的复制。代码:
for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;
其中cmp函数的代码是:
int cmp(int *r,int a,int b,int l)
{return r[a]==r[b]&&r[a+l]==r[b+l];}
这里可以看到规定r[n-1]=0的好处,如果r[a]=r[b],说明以r[a]或r[b]开头的长度为l的字符串肯定不包括字符r[n-1],所以调用变量r[a+l]和r[b+l]不会导致数组下标越界,这样就不需要做特殊判断。执行完上面的代码后,rank值保存在x数组中,而变量p的结果实际上就是不同的字符串的个数。这里可以加一个小优化,如果p等于n,那么函数可以结束。因为在当前长度的字符串中,已经没有相同的字符串,接下来的排序不会改变rank值。例如图1中的第四次排序,实际上是没有必要的。对上面的两段代码,循环的初始赋值和终止条件可以这样写:
for(j=1,p=1;p<n;j*=2,m=p) {…………}
在第一次排序以后,rank数组中的最大值小于p,所以让m=p。
整个倍增算法基本写好,代码大约25行。
算法分析:倍增算法的时间复杂度比较容易分析。每次基数排序的时间复杂度为O(n),排序的次数决定于最长公共子串的长度,最坏情况下,排序次数为logn次,所以总的时间复杂度为O(nlogn)。















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









