







 本文总结了普林斯顿大学算法课程中第一周的编程作业——渗透模型的实现,包括模型描述、数据结构设计、Java与C语言的实现对比,以及在使用Quick-Find算法时遇到的问题和解决方案。文中提到,Quick-Find在大N值时效率低下,而Weighted-Quick-Union则表现更优。最后,讨论了模型中存在的backwash问题及其两种改进方案。
本文总结了普林斯顿大学算法课程中第一周的编程作业——渗透模型的实现,包括模型描述、数据结构设计、Java与C语言的实现对比,以及在使用Quick-Find算法时遇到的问题和解决方案。文中提到,Quick-Find在大N值时效率低下,而Weighted-Quick-Union则表现更优。最后,讨论了模型中存在的backwash问题及其两种改进方案。
第一周的编程作业是实现一个Percolation渗透模型。
模型描述:
有一个四方的模型,由 N*N 个区域(site)组成,每个区域有两个状态,开启(open)或关闭(blocked),相邻的开启区域能构成一条通路,当最上层区域能够通过开启区域连成的通路,和最下层互通的时候,则整个模型为渗透状态(percolated)。
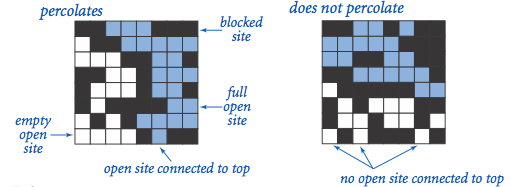
如上图所示,白色和蓝色的区域为开启状态,黑色的为关闭状态,当开启的白色区域和顶层互通的时候,称为区域满(full),左侧顶层和底层能够互通,则整个模型已渗透,右侧则是非渗透的情况。
这种模型应用在实际中可类比渗水、导电等。
编程作业的要求则是实现这么一种模型,并计算出每次模型渗透时,开启区域占总区域个数的百分比,这个百分比近似于某一常数,通过多次模拟采样计算该常数。
模型分析:
(1)数据结构:给定 N 的个数,可以得到一个 N * N 个区域的模型,如果将此模型的每个区域从0进行编号,可以得到 0 ~ N^2-1 的数据,将此模型平坦成一维模型,就是一个数组的形式。
(2)数据操作:
a. 如何模拟区域的开启:开启某一个区域,将其状态标记为开启,然后四周如果有开启的区域,应该将它们连在一起。
b. 如何模拟模型的渗透:当顶层的任一区域和底层的任一区域连接在一起时,则模型渗透。实际操作时,这是一个双重for循环,可以虚拟两个区域,一个和顶层所有开启的区域互连,一个和底层所有开启的区域互连,当这两个区域连接在一起时,则模型为渗透状态,避免了双重for,N * N的数组访问操作。
作业只能用 Java 语言提交,除了此要求以外,还有其他诸如变量命名等程序风格规范、内存使用限制、运行时间限制等。完成作业以后,我将整个模型用 C 又实现了一次,并用 C 重写了算法的实现(参见个人总结1)。这篇算是个人的心得体会。
从 C 转向
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









