






Linux、Hadoop、Java、HBase、Hive和MySQL在大数据处理和存储领域各自扮演着重要的角色,并且它们之间有着一定的关联和依赖关系。以下是它们之间的简要关系描述:
Linux与Hadoop:
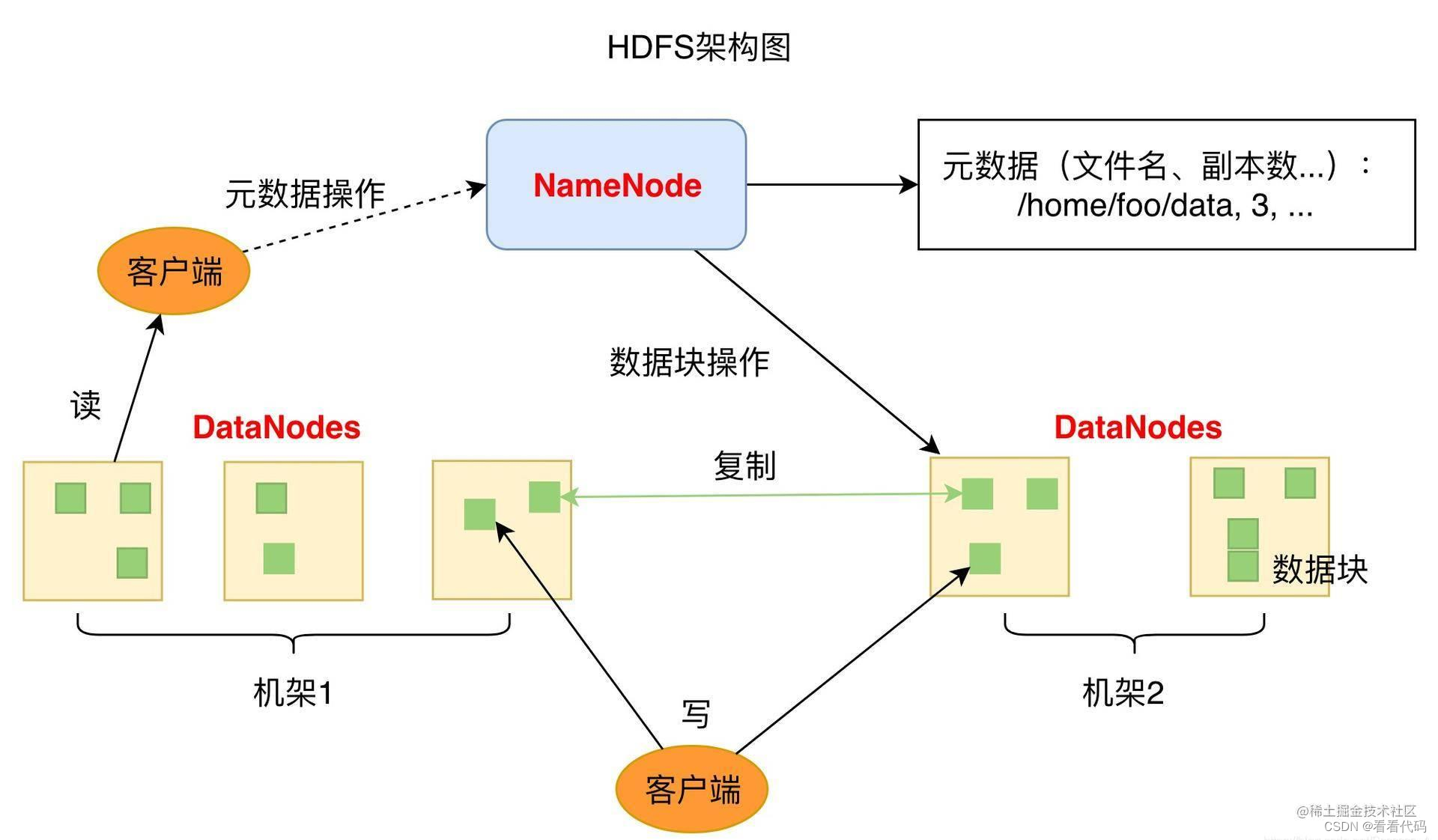
一、准备环境
- 关闭防火墙和SELinux:为了避免在安装和配置过程中遇到网络问题或权限问题,建议暂时关闭防火墙和SELinux。在CentOS系统中,可以使用
systemctl stop firewalld命令关闭防火墙,使用setenforce 0命令临时关闭SELinux。 - 安装JDK:首先确保你的Linux系统上已经安装了JDK。你可以从Oracle官网下载适合你Linux发行版的JDK,然后按照官方文档进行安装。安装完成后,需要设置JAVA_HOME环境变量,并将其添加到PATH中。
二、下载并解压Hadoop安装包
- 下载Hadoop安装包:从Apache Hadoop官网下载适合你Linux发行版的Hadoop安装包。通常,你会下载到一个以
.tar.gz为后缀的压缩包。 - 解压Hadoop安装包:使用
tar命令解压Hadoop安装包到指定目录,例如/opt/hadoop。命令如下:tar -zxvf hadoop-版本号.tar.gz -C /opt/hadoop。
三、配置Hadoop环境变量
core-site.xml:配置Hadoop集群的全局参数,如Hadoop文件系统的默认名称、Hadoop临时目录等。
<configuration> | |
<property> | |
<name>fs.defaultFS</name> | |
<value>hdfs://localhost:9000</value> | |
</property> | |
<property> | |
<name>hadoop.tmp.dir</name> | |
<value>/opt/hadoop/hadoop-版本号/tmp</value> | |
</property> | |
</configuration> |
四、配置Hadoop
-
hdfs-site.xml:配置Hadoop分布式文件系统(HDFS)的相关参数,如数据块的副本数、NameNode和SecondaryNameNode的地址等。
-
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop/hadoop-版本号/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop/hadoop-版本号/data/datanode</value> </property> </configuration> - mapred-site.xml(或
yarn-site.xml):如果你使用的是Hadoop 2.x或更高版本,则可能需要配置MapReduce或YARN的相关参数。这些参数包括作业调度器、内存管理等。 - hadoop-env.sh:这是一个shell脚本文件,用于设置Hadoop运行时的环境变量。你可以根据需要修改该文件中的JAVA_HOME和其他环境变量。
五、格式化HDFS并启动Hadoop
- 格式化HDFS:在Hadoop集群中的主节点上,运行
hdfs namenode -format命令来格式化HDFS。这将创建一个新的文件系统或重置一个现有的文件系统。 - 启动Hadoop:根据你的Hadoop配置,使用适当的命令来启动Hadoop服务。通常,你可以使用
start-dfs.sh和start-yarn.sh脚本来启动HDFS和YARN服务。在启动之前,确保你已经设置了正确的Hadoop配置文件和环境变量。
六、验证Hadoop安装
你可以通过运行一些简单的Hadoop命令来验证Hadoop是否已经成功安装并运行。例如,你可以使用hadoop version命令来查看Hadoop的版本信息。你还可以使用hdfs dfs -mkdir命令在HDFS上创建一个目录,并使用hdfs dfs -ls命令来查看HDFS上的文件和目录列表。
请注意,以上步骤是一个基本的指南,并且可能需要根据你的具体环境和需求进行调整。在安装和配置Hadoop时,请务必参考官方文档和社区资源以获取最新和最准确的信息。
Linux与Java:

- Java是一种跨平台的编程语言,其“一次编写,到处运行”的特性使得它非常受欢迎。
- Linux系统上可以安装和运行Java虚拟机(JVM),从而支持Java程序的执行。
- 许多大数据工具和框架,包括Hadoop、HBase、Hive等,都是用Java编写的,因此它们可以在Linux上运行。
1. 安装Java
首先,确保你的Linux系统上已经安装了Java。你可以通过运行
java -version来检查是否已经安装了Java以及安装的版本。如果你还没有安装Java,你可以使用Linux的包管理器(如apt、yum等)来安装。例如,在Ubuntu上,你可以使用以下命令来安装OpenJDK:
sudo apt updatesudo apt install openjdk-11-jdk2. 编写Java程序
接下来,我们编写一个简单的Java程序。假设我们要编写一个程序,该程序会输出"Hello, World!"。
打开一个文本编辑器(如vi、nano、gedit等)。
创建一个新的文件,名为
HelloWorld.java。在文件中输入以下代码:
public class HelloWorld { public static void main(String[] args) { System.out.println("Hello, World!"); } }- 保存并关闭文件。
3. 编译Java程序
在Linux中,你可以使用
javac命令来编译Java程序。打开终端,导航到包含HelloWorld.java文件的目录,并运行以下命令
javac HelloWorld.java如果编译成功,你会在同一个目录下看到一个名为
HelloWorld.class的文件,这是编译后的Java字节码文件。4. 运行Java程序
使用
java命令来运行编译后的Java程序。在终端中,运行以下命令:
java HelloWorld你应该会在终端中看到输出"Hello, World!"。
5. 示例题目
以下是一些常见的Java编程示例题目,你可以在Linux环境中使用Java来实现它们:
- 编写一个程序,计算从1到100的整数和。
- 编写一个程序,从用户那里接收两个数字作为输入,并输出它们的和、差、积和商。
- 编写一个程序,使用Java的数组来存储一组数字,并计算这组数字的平均值。
- 编写一个程序,使用Java的
Scanner类从用户那里接收一个字符串,并检查该字符串是否是一个回文字符串(正读和反读都一样的字符串)。- 编写一个程序,模拟一个简单的猜数字游戏。程序随机生成一个1到100之间的整数,让用户来猜。如果用户猜对了,程序输出"恭喜你,猜对了!";如果用户猜错了,程序输出"很遗憾,你猜错了。再试一次!"并告诉用户他们猜的数字是太大还是太小。
Linux与HBase:
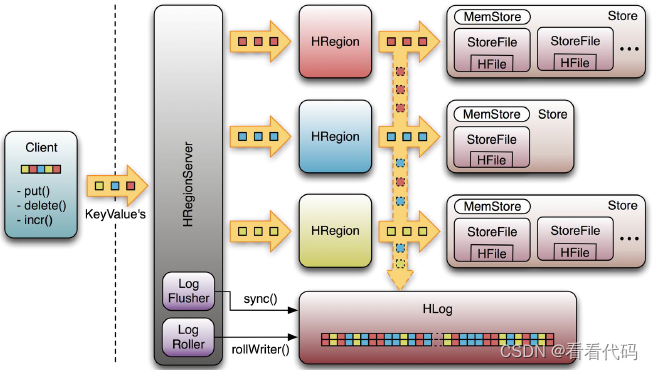
-
一、HBase在Linux上的安装与配置
-
环境准备:
- 确保Linux系统上已经安装了Java,并设置了JAVA_HOME环境变量。
- 安装并配置Hadoop,因为HBase是Hadoop的一个子项目,依赖于Hadoop的HDFS和YARN等组件。
- 安装ZooKeeper,因为HBase使用ZooKeeper进行集群管理。
-
下载并解压HBase:
- 从HBase官网下载适合你Linux发行版的HBase安装包。
- 使用tar命令解压HBase安装包到指定目录,例如
/usr/local/hbase -
export HBASE_HOME=/usr/local/hbaseexport PATH=$PATH:$HBASE_HOME/bin - 保存并退出后,运行
source ~/.bashrc使环境变量生效。
-
配置HBase:
- 进入HBase的
conf目录,编辑hbase-env.sh文件,设置JAVA_HOME。 - 编辑
hbase-site.xml文件,配置HBase的相关参数,如HDFS的数据目录、ZooKeeper的地址等。
- 进入HBase的
-
启动HBase:
- 先启动Hadoop和ZooKeeper。
- 运行
start-hbase.sh脚本启动HBase。
-
创建表:
create 'test_table', 'cf1', 'cf2'Configuration config = HBaseConfiguration.create(); // 配置ZooKeeper地址等参数... Connection connection = ConnectionFactory.createConnection(config); Admin admin = connection.getAdmin(); HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("test_table")); tableDescriptor.addFamily(new HColumnDescriptor("cf1")); tableDescriptor.addFamily(new HColumnDescriptor("cf2")); admin.createTable(tableDescriptor);- 使用HBase Shell或Java API创建一个名为
test_table的表,包含cf1和cf2两个列族。 - HBase Shell示例:
- Java API示例(需要导入HBase的Java库和Hadoop的配置文件):
- 使用HBase Shell或Java API创建一个名为
-
插入数据:
put 'test_table', 'row1', 'cf1:col1', 'value1' Table table = connection.getTable(TableName.valueOf("test_table")); Put put = new Put(Bytes.toBytes("row1")); put.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value1")); table.put(put);- 向
test_table表的cf1列族中的row1行插入数据,列名为col1,值为value1。 - HBase Shell示例:
- Java API示例:
- 向
-
查询数据:
get 'test_table', 'row1', 'cf1:col1'Get get = new Get(Bytes.toBytes("row1"));get.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("col1"));Result result = table.get(get);byte[] value = result.getValue(Bytes.toBytes("cf1"), Bytes.toBytes("col1"));String stringValue = Bytes.toString(value);System.out.println(stringValue); // 输出 "value1"- 查询
test_table表的row1行cf1列族中的col1列的值。 - HBase Shell示例:
- Java API示例:
- 查询
Linux与Hive:

-
Linux与Hive的结合主要体现在Hive在Linux系统上的部署和使用。Hive是一个基于Hadoop的数据仓库工具,它允许用户使用SQL语言来查询和管理存储在Hadoop分布式文件系统(HDFS)中的数据。以下是一个简化的流程,并附带一些基本的例题讲解。
一、Hive在Linux上的部署
-
环境准备:
- 确保Linux系统上已经安装了Java,并设置了JAVA_HOME环境变量。
- 安装并配置Hadoop集群,因为Hive需要Hadoop的HDFS和YARN等组件作为底层支持。
-
下载并解压Hive:
- 从Hive官网下载适合你Linux发行版的Hive安装包。
- 使用tar命令解压Hive安装包到指定目录,例如
/usr/local/hive。
-
配置Hive:
- 进入Hive的
conf目录,编辑hive-site.xml文件,配置Hive的相关参数,如Hadoop的配置文件路径、Hive的数据仓库位置等。 - 在
hive-env.sh文件中设置HADOOP_HOME和HIVE_CONF_DIR等环境变量。
- 进入Hive的
-
初始化Hive的元数据库:
- Hive使用元数据来存储数据库、表等结构信息,默认情况下,Hive支持使用MySQL、Derby等数据库来存储元数据。这里以MySQL为例,需要先在MySQL中创建相应的数据库和用户,并赋予相应的权限。
- 在Hive的
hive-site.xml文件中配置MySQL的连接信息。 - 运行Hive的初始化脚本(如
schematool -dbType mysql -initSchema)来初始化Hive的元数据库。
-
启动Hive:
- 确保Hadoop集群已经启动。
- 在Hive的bin目录下运行
hive命令来启动Hive的CLI(命令行界面)。
-
创建数据库:
CREATE DATABASE mydb;USE mydb; -
创建表:
假设我们有一个HDFS上的文本文件
/user/hive/warehouse/mydb.db/mytable/data.txt,内容如下:1,John,Doe,302,Jane,Doe,25我们可以使用Hive来创建一个表来映射这个文件:
CREATE TABLE mytable (id INT, first_name STRING, last_name STRING, age INT)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','STORED AS TEXTFILE;-- 加载数据到Hive表中LOAD DATA LOCAL INPATH '/path/to/local/data.txt' INTO TABLE mytable;-- 或者如果数据已经在HDFS上LOAD DATA INPATH '/user/hive/warehouse/mydb.db/mytable/data.txt' INTO TABLE mytable; -
查询数据:
SELECT * FROM mytable;SELECT first_name, last_name FROM mytable WHERE age > 28; -
插入数据:
Hive主要支持批处理操作,所以通常不使用INSERT语句来插入单条记录。但是,你可以使用LOAD DATA命令来加载数据,或者使用Hive的外部表来映射HDFS上的数据。
-
创建分区表:
分区表可以提高查询性能,因为Hive可以只扫描包含所需数据的分区。
CREATE TABLE partitioned_table (id INT, name STRING)PARTITIONED BY (year INT, month INT)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ',';-- 加载数据到指定分区LOAD DATA LOCAL INPATH '/path/to/local/data_2023_01.txt' INTO TABLE partitioned_table PARTITION (year=2023, month=1); -
其他操作:
- 删除表:
DROP TABLE mytable; - 修改表结构(注意:Hive不支持像传统数据库那样直接修改表结构,但可以通过其他方式如ALTER TABLE命令来添加列或分区等)
- 执行HiveQL的其他语句,如JOIN、GROUP BY、ORDER BY等。
- 删除表:
Linux与MySQL:
Linux与MySQL的结合主要体现在Linux系统上MySQL数据库的部署、连接、操作以及基于MySQL的SQL查询和数据管理。下面我将简要介绍Linux与MySQL的实现,并给出一些基本的例题讲解。
一、MySQL在Linux上的部署
-
环境准备:
- 确保Linux系统上已经安装了Java(虽然MySQL本身并不需要Java,但很多与MySQL相关的应用和服务可能需要)。
- 根据你的Linux发行版,可能需要安装一些额外的库和依赖。
-
下载并解压MySQL:
- 从MySQL官网下载适合你Linux发行版的MySQL安装包。
- 使用tar命令或其他工具解压安装包到指定目录,例如
/usr/local/mysql。
-
配置MySQL:
- 创建一个MySQL用户和用户组(如果还没有的话)。
- 进入MySQL的
support-files目录,使用mysql_install_db脚本来初始化数据库。 - 复制MySQL的配置文件(如
my.cnf或my.ini)到适当的目录,并根据需要进行修改。
-
启动MySQL:
- 使用
mysqld_safe命令或你Linux发行版提供的MySQL服务管理工具来启动MySQL服务。
- 使用
-
连接MySQL:
在Linux命令行中,你可以使用
mysql客户端工具来连接MySQL数据库。基本语法如下:mysql -h 主机名 -u 用户名 -p例如,连接到本地MySQL服务器并使用root用户:
mysql -u root -p然后系统会提示你输入root用户的密码。
-
创建数据库:
CREATE DATABASE mydatabase;USE mydatabase; -
创建表:
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50) NOT NULL, email VARCHAR(100) NOT NULL UNIQUE ); -
插入数据:
INSERT INTO users (name, email) VALUES ('Alice', 'alice@example.com');INSERT INTO users (name, email) VALUES ('Bob', 'bob@example.com'); -
查询数据:
SELECT * FROM users;SELECT name, email FROM users WHERE id = 1; -
更新数据:
UPDATE users SET email = 'newemail@example.com' WHERE id = 1; -
删除数据:
DELETE FROM users WHERE id = 2; -
删除表:
DROP TABLE users; -
DROP DATABASE mydatabase; - 安全性:在生产环境中,你应该使用强密码,并限制对MySQL服务的访问权限。
- 备份与恢复:定期备份你的MySQL数据库,以防止数据丢失。你可以使用
mysqldump命令来备份数据库。 - 性能优化:根据你的应用需求和数据量,你可能需要调整MySQL的配置参数,如缓存大小、连接数等。
- 错误处理:当遇到错误时,查看MySQL的错误日志可以帮助你诊断问题。错误日志的位置和名称取决于你的MySQL配置。
总的来说,Linux作为一个稳定和灵活的操作系统平台,为大数据处理和存储提供了坚实的基础。Hadoop、Java、HBase、Hive和MySQL等工具和框架在Linux上协同工作,共同支持大规模数据处理和分析的需求。















 8021
8021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









