









一、存在问题:
1.整个商品详情页直接对数据库操作,没有使用缓存;
2.商品详情页取sql字段和查询内容比较多都写一个方法里;
3.获取详情页sku取数据,单条取是否可以拆分通过attr_id取对应的规则
二、优化方案:
商品详情页优化
商品详情页流程图
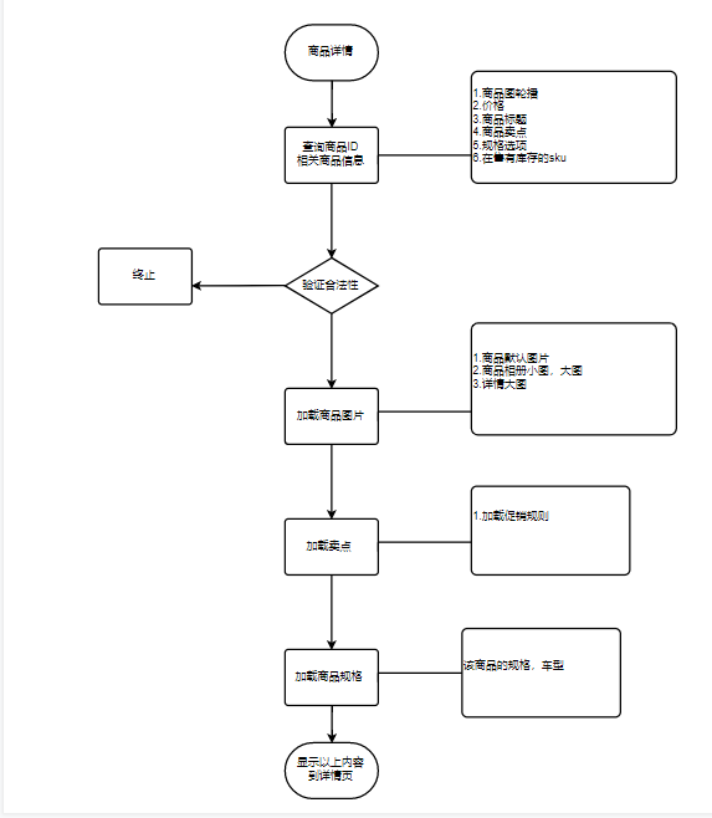
一目前的问题是什么
1.整个商品详情页直接对数据库操作,没有使用缓存;
2.商品详情页取sql字段和查询内容比较多都写一个方法里;
3.获取详情页sku取数据,单条取是否可以拆分通过attr_id取对应的规则
二.如何解决这些问题
详情页架构设计原则
1、数据闭环 :数据闭环即数据的自我管理,或者说是数据都在自己系统里维护,不依赖于任何其他系统.
2、数据维度化 :对于数据应该按照维度和作用进行维度化,这样可以分离存储,进行更有效的存储和使用.
3、异步化+并发化
使用了消息异步化进行系统解耦合,通过消息通知我变更,然后我再调用相应接口获取相关数据;数据更新异步化,更新缓存时,同步调用服务,然后异步更新缓存。
前端服务异步化/聚合,实时价格、实时库存异步化,使用如线程或协程机制将多个可并发的服务聚合。
4、多级缓存化
使用缓存;
增加redis缓存,对商品id范围效验,增加对空值缓存防止频繁对数据库操作
增加前后台共用缓存key,后台修改可以直接修改更新缓存
部分频繁更新的部分字段内容,可以使用消息推送模式更新缓存
优化查询:商品详情页查询sku直接查返回数组
前台页面
页面可以考虑静态化,部分频繁变动内容可以再单调接口
服务器
可以根据需要可以做数据库读写分离和负载均衡
三.解决方案
1.使用hyperf的系统架构,
Hyperf 是基于 Swoole 4.5+ 实现的高性能、高灵活性的 PHP 持久化框架,内置协程服务器及大量常用的组件,性能较传统基于 PHP-FPM 的框架有质的提升,提供超高性能的同时,也保持着极其灵活的可扩展性基于 PSR-11 的依赖注入容器、注解、AOP 面向切面编程、
基于 PSR-15 的中间件、自定义进程、基于 PSR-14 的事件管理器、Redis/RabbitMQ 消息队列。
2.查询商品详情 增加redis查询缓存和对商品id范围效验,增加对空值缓存防止缓存穿透。
缓存穿透,用户想要查询一个数据,发现redis数据库没有,也就是所谓的没有命中缓存,于是向数据库查询,发现也没有,于是查询失败。但当用户请求很多时,直接请求数据库,这会给数据库造成很大的压力,这时候就相当出现了缓存穿透。
3.查询语句优化对字段查询定义到数据组中方便管理,获取车型sku不再循环去取。
四.前后压测数据对比 略
旧地址
maiche-api-test.360che.com/goods_index/get_goods_detail/3
服务器:单台服务器4核8G配置 200-250
新地址
39.106.185.201/goods_index/get_goods_detail/3
服务器:单台服务器1核2G配置 1500
新增地址分开接口
单独查商品信息 http://39.106.185.201/goods/index/3
单独查sku信息 http://39.106.185.201/goods/sku/3
新压测服务器配置
CPU: 1核
内存: 2 GiB
实例类型: I/O优化
操作系统: CentOS 7.7 64位
弹性网卡: eni-2zehx48jsavw00ym8817
公网IP: 39.106.185.201
Ngnix1.18.0 Php7.4 mysql5.5.6 redis6.0.6
三、意见建议:
1.校验取消正则;改用int或者is_number;
2.redis商品发布编辑增加缓存。
3.商品ID校验使用集合,避免ID断层情况;
4.业务性配置不要加env,放config。
















 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









