







目录
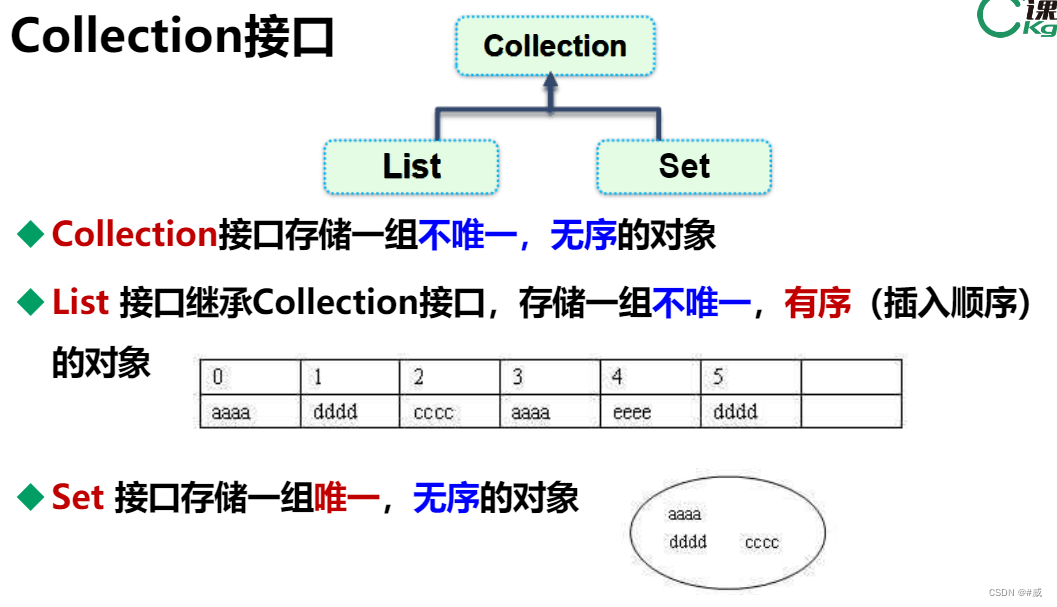
Ccllection是List和Set的父类(标红需要重点掌握)
Ccllection——LinkedList实现类使用和常用方法:
Ccllection——HashSet实现类使用和常用方法:
三,String字符,StrinBuffer字符,date类,使用SDF格式时间
String,StringBuffer和StringBuilder三者的区别在于:
熟练使用Date类和Calendar类操作时间日期并熟练使用SimpleDateFormat类格式化时间
字节流InputStream输入和OutputStream输出
使用二进制进行照片,视频,音频的输入(DataInputStream)和输出(DataOutputStream)
使用方式输入(DataInputStream)和输出(DataOutputStream)(复制和粘贴)
一,集合框架,泛型Collections工具类
java集合框架提供了一套性能优良,使用方便的接口种类,它们都位于java.util包中,其主要关系如下图:
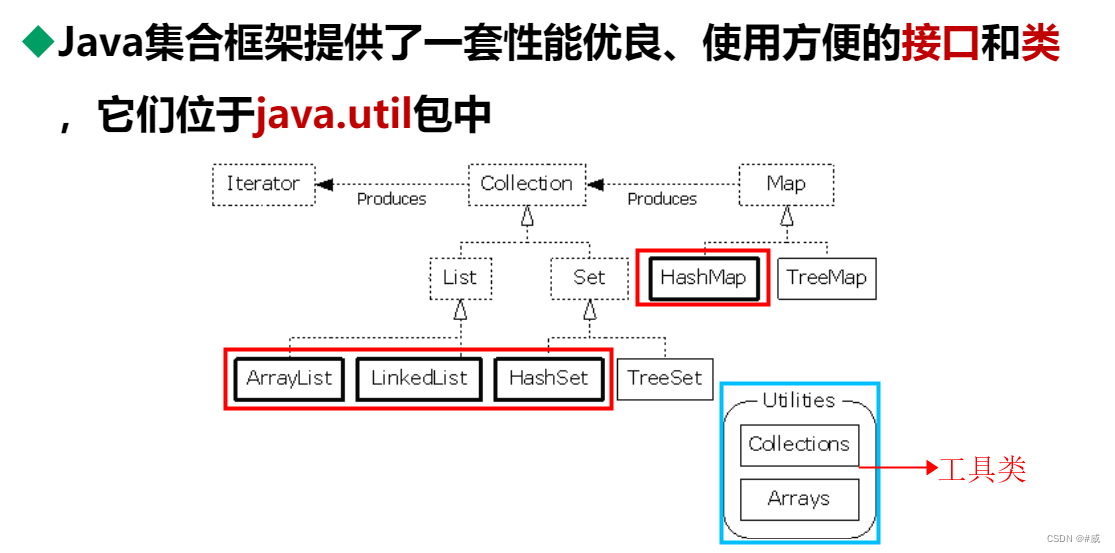
Ccllection是List和Set的父类(标红需要重点掌握)
1,Ccllection是接口,用来储存一组不唯一,且无序的对象
2,List是继承Collection接口,储存一组不唯一,但是有序的对象集合,下面有ArrayList和LinkedList
ArrayList实现类作用是实现了长度可变的数组,在内存中分配连续的空间。遍历元素和随机访问元素的效率比较高,也是最像数组的一个对象集合
LinkedList实现类作用是采用链表存储方式。插入、删除元素时效率比较高
3,Set是继承Collection接口,储存一组唯一,但是无序的对象集合,下面有HashSet和TreeSet,
HashSet实现类的特点:集合内的元素是无序排列且不允许重复,HashSet集合的查找效率高,允许集合元素值为null。
3,Map下面有HashMap和TreeMap
注意:上图红框标注需要重点掌握!!!
迭代器遍历的使用(Iterator):
1,迭代器需要使用Iterator对需要做遍历的集合对象进行声明,需要使用while循环,迭代器针对Set和Map接口
如果Set接口使用迭代遍历:
Iterator 迭代声明名 = 需要遍历的集合接口().iterator();即可
如果Map接口使用迭代遍历需要使用values:
Iterator 迭代声明名 = 需要遍历的集合接口().values.iterator();

集合和数组的区别

List集合 ——ArrayList实现类使用和常用方法
注意:ArrayList ,LinkedList和HashSet大部分常用方法都是通用,LinkedList的常用方法其它实现类不能用,但是LinkedList可以使用其它实现类的大部分常用方法。
Ccllection——ArrayList使用和常用方法:
1,ArrayList如何new出一个框架:List<泛型> ArrayList对象名 = new ArrayList<>();
2,使用add添加元素:ArrayList对象名.add(集合对象);
3,使用size返回元素数量:ArrayList对象名.size();
4,使用get强转:遍历集合对象时,对象类型是Object类型,需要进行类型转换,转换方法:集合对象的类 对象名 =(集合对象的类) ArrayList对象名.get(遍历内容);
5,使用set更改集合对象内容:ArrayList对象名.set(需要更改的元素位置,更改的内容);
6,使用contains查询元素是否存在:contains输出的结果为布尔值类型,使用方法:ArrayList对象名.contains(集合对象);
7,使用indexOF查询某个集合对象的元素位置:ArrayList对象名.indexOF(集合对象);
8,使用remove删除:remove有两种删除类型:Object和int类
Object的remove是删除集合:ArrayList对象名.remove(集合对象名);
int类型的remove是删除元素所在的集合对象:ArrayList对象名.remove(删除的元素 位置);
9,clear清空所有元素参数:ArrayList对象名.clear();
10,isEnpty()判断ArrayList集合是否为空:返回类型为布尔类型,集合为空返回true。使用方法:ArrayList对象名.isEnpty();

List集合 ——LinkedList实现类使用和常用方法
注意:ArrayList ,LinkedList和HashSet大部分常用方法都是通用,LinkedList的常用方法其它实现类不能用,但是LinkedList可以使用其它实现类的大部分常用方法。
Ccllection——LinkedList实现类使用和常用方法:
1,new一个LinkedList实现类:
LinkedList LinkedList对象名 = new LinkedList<>();
2,addFirst和addList:
addFirst一个集合对象成为第一个元素位置:LinkedList对象名.addFirst(集合对象);
addList一个集合对象成为最后一个元素位置:LinkedList对象名.addList(集合对象);
3,getFirst和getList:
getFirst获取第一个元素:LinkedList对象名.getFirst().get集合类的变量();
getList获取最后一个元素:LinkedList对象名.getList().get集合类的变量();
4,removeFirst和removeList:
removeFirst删除第一个元素:LinkedList对象名.removeFirst();
removeList删除最后一个元素:LinkedList对象名.removeList();

set集合——HashSet实现类的使用和常用方法
注意:ArrayList ,LinkedList和HashSet大部分常用方法都是通用,LinkedList的常用方法其它实现类不能用,但是LinkedList可以使用其它实现类的大部分常用方法。
Ccllection——HashSet实现类使用和常用方法:
1,clear清空所有元素参数:ArrayList对象名.clear();
2,isEnpty()判断ArrayList集合是否为空:返回类型为布尔类型,集合为空返回true。使用方法:ArrayList对象名.isEnpty();
3,使用contains查询元素是否存在:contains输出的结果为布尔值类型,使用方法:ArrayList对象名.contains(集合对象);
4,Object的remove是删除集合:ArrayList对象名.remove(集合对象名);


Map接口
Map接口的特点:Map接口提供key到value的映射,Map接口是无序,且无法重复的
Map集合使用泛型时,根据要存储的key和value是什么类型,进行分别泛型
比如key是String,value是String: Map<String,String>
比如key是String,value是Student类型: Map<String,Student>
比如key是String,value是Object类型: Map<String,Object>
比如key是Integer,value是Object类型: Map<Integer,Object>
遍历map集合,建议使用lamada表达式的方式:这种集合遍历只针对Map接口。
studentMap.forEach(
(k, v) -> {
System.out.println(k + "\t" + v.getStuName());
});
HashMap实现类的使用和常用方法
1,Map接口存储一组键值对象,HashMap实现类继承Map接口,不保证映射的顺序,特别是不保证顺序恒久不变
2,数据添加到HashMap集合后,所有数据的数据类型将转换为Object类型,所以从其中获取数据时需要进行强制类型转换。
注意:可以使用ArrayList 和HashSet大部分常用方法
3,new一个HashMap集合对象:Map HashMap对象名 = new HashMap<>();
比如key是String,value是Student类型: Map
比如key是Integer,value是Object类型: Map
key通常是string类型,value是集合类型
4,使用containsKey查询key元素是否存在:HashMap对象名.containsKey(key集合元素);
5,使用containsvalue查询value集合是否存在:HashMap对象名.containsValue(value集合元素);
6,使用keySet获取所有key的集合:HashMap对象名.keySet();
7,使用values获取所有value的集合:HashMap对象名.values();
8,使用forEach遍历HashMap集合:这种集合遍历只针对Map接口。
HashMap对象名.forEach(
(key ,value)->{ //key,value可以随意命名,输出的时候注意对照进行
System.out.println( key + "\t" + value.get集合变量名);
})
示例:
studentMap.forEach(
(k , v) -> {
System.out.println("英文名字:" + k + "," + "中文名字:" + v.getNames() + ",性别:" + v.getGender());
}
);


Collections集合操作工具类
Collections.sort(list);对list中的对象进行排序,通常是按照对象的某个属性进行排序
使用该方法时,必须保证list中的对象实现了Comparable接口并重写了compareTo的方法,否则无法排序且会报错
lamada表达式排序:
//倒序
Collections.sort(studentList, (first, second) -> second.getStuNo()-first.getStuNo());
//正序
Collections.sort(studentList, (first, second) -> first.getStuNo()-second.getStuNo());
使用普通sort表达式进行排序:
直接使用Collections.sort(集合接口名)进行排序是会进行报错的,需要在集合对象里面使用implements继承Comparadle重写compareTo(父类,指向父类)的接口,然后对其做一个判断排序,类似于冒泡排序如下图:
* 注意重写方法的返回值类型,从而做出改变,面对字符串的对比需要使用Integer.parselnt()


字符类型强转数字类型对比:Integer.parselnt()

常用方法

二,枚举,包装类,Math类,Random类的常用方法
java API常用包

枚举作用和使用方法
修饰词:enum
枚举是一组固定的常量组成的类型,要使用大写做输出
1, 枚举类中不能有方法和成员属性
2,枚举类型中是由一组常量组成,常量为字符串时,不能加双引号,直接写即可
3,枚举类型中的常量不能是基本数据类型,比如数字,小写的true或false
4,枚举类中的多个值使用英文逗号分隔
枚举的使用方法:
枚举的创建

方法调用枚举类

测试类从控制台接收数据和枚举常量进行对比(valueOF)

包装类作用和使用方法
包装类的概述
java语音是面向对象的,但是java中的基本数据类型却不是面向对象的,这在实际开发中存在很对不变,所有在设计类时为每个八大基本数据类型设计了一个对应的类,成为包装类。
注意:包装类对象只有在基本数据类型需要用对象表示的时候时才会使用,包装类并不是用来取代基本数据类型的!!!
八大基本数据类型和包装类的对照表

包装类和基本数据类型的相互转换

Math类作用和使用方法
Mash类有多种使用方法,常用来获取最大数,最小数和随机数

使用Mash类获取一个随机数
在方法中获取一个【155~658】之间的随机数,并输出给测试类
判断获取范围的机制:用获取的数值上限658减获取的数值下限155,得到503个数,因为含155,所有503加1得到504,取值范围就是获得504个数值,从155开始获取,就是(Math.random() * 504 + 155)


Random类作用和使用方法
Random类主要用来获取随机数

使用Random获取一个随机数:

三,String字符,StrinBuffer字符,date类,使用SDF格式时间
熟练使用String操作字符串
String类的常见用法,如下图:


根据上图对每个常用方法进行操作:
下列图片中出现s1时,均调用的是:String s1 = "hello I am your daddy";
1.使用charAt() 获取字符串中的一个值:char c1 = s1.charAt(1);
就是char类型获取,在s1字符串中获取第几个字符charAt(int数字);从0开始,空格也是字符

2.使用concat()在字符串后面进行添加字符或字符串:
简写:s1 += "添加的字符串"
使用concat:s1 = s1.concat( "添加的字符串");

3,使用coatains()判断字符串中是否存在查找的字符或字符串:
String变量名.coatains("查找内容");

4,使用epualsIgnoreCase();进行字符或字符串验证,不区分大小写验证,返回布尔值类型
变量1.epualsIgnoreCase(变量2);

5,使用byte[] getBytes把字符串转为ASCII码储存到byte[]数组里面

6,使用indexOF获取第一次出现的字符或字符串和lastlandexOF获取最后一次出现的字符或字符串
indexOF获取第一次:int类型获取 String变量名.indexOF("查找字符串");
lastlandexOF获取最后一次:int类型获取 String变量名.lastiandexOF("查找字符串");

7,正则表达式(重点*)matches.();
正则表达式是对某些程序做一个限制作用,可以是控制台接收的,也可以是程序生成的,当需要对某些做限制或验证,如:电话号码验证,邮箱 验证等,可以去网上进行搜索正则表达式,复制粘贴即可。
需要验证的Syting变量.matches.(正则表达式); 返回布尔值类型

8,使用length();获取字符串长度:
ing类型接收 len = String变量名.langth();

9,使用replace();修改部分字符串内容
String变量1 = String变量1.replace("旧字符串","新字符串");

10,使用split();对字符串进行分割:
String[]数组获取 数组名 = 要分割变量名.split("");分割符可以是空格,逗号,斜杠等,分割后这些符号会消失,如果什么都不加,则会对每一个字符进行分割,分割后会储存String[]数组中。

11,使用substring();做定位分割,生成新的String类型
substring有两种使用方法:
1,使用int类型做定位,获取生成从定位向右的所有字符串
2,直接在substring(int类型开始,int类型结束);从开始位置获取到结束位置,字符串截取从0开始数,
如下图: 字符串的第五个字符开始截取到第七个字符结束(不含第七个字符)

12,使用toCharArray(); 将一个字符串类型转成字符类型,储存到char[]数组里面

13,使用使用toLowerCase();小写转大写和toUpperCase();大写转小写

14,使用trim(); 省略字符串前后空白

注:以上图片截取位置:D:\YANG\KD42\javasenior\src\senior\day4\Test
熟练使用StringBuffer操作字符串
StringBuffer是可以理解为String的加强版,还有一个StringBuilder也是String类的加强版。
String,StringBuffer和StringBuilder三者的区别在于:
String类:String类是不可被改变的,每一次对String类型做改变,就会生成一个新的String类型,创造一个新的地址储存,过多的操作同一个 String类型,会严重影响系统性能。当一个String类会被多次改变时建议对String类进行增强!
StringBuffer类:StringBuffer是可以被改变的,每次改变StringBuffer类只会对本体进行改变,不会生成新的类型。
StringBuilder类:StringBuilder类就是StringBuff翻版,都是对String做加强,使用方法和StringBuffer一样。
StringBuff类和StringBuilder类的区别:StringBuffer类是线程安全,StringBuilder类单线程,不提供同步,理论上效率更高。
StringBuffer的使用:
注意:强化后的类型无法再被赋值,如下图S1无法再被赋值,但num可以!
下面是StringBuffer类的创建方法,StringBuilder类的一模一样的,如何使用根据上面String字符的部分操作方法即可,
1,创建一个StringBuffer对象,有两种方法
第一种:创建一个String类型,new一个强化版对其进行赋值

第二种:new一个强化对象,直接赋值即可

2,使用insert();对字符串中添加字符
一,倒着添加字符,无法使用正序

熟练使用Date类和Calendar类操作时间日期并熟练使用SimpleDateFormat类格式化时间
Date类型操作:是获取一个时间,可以获取完整的年月日时分秒,也可以只获取年月日或时分秒
Calendar类型操作:也是获取一个时间,但是不能完整获取年月日时分秒,只能分开获取单独的年,月,日,时,分,秒,周几,毫秒等,如果一定要用Calendar类型获取一个完整的时间,则需要借助Date类型来完成
SimpleDateFormat类型操作:用于格式化时间,Date类型输出一个完整的时间时,但这个时候的输出结果不是正常看到的类型,所有要对输出的结果使用SimpleDateFormat类型转换成为平常看到的类型,SDF格式类型的操作都需要基于上面两个时间类型
使用建议:如果想要获得一个系统时间,使用Date时间类比较方便,如果想要从控制台获取一个生日,先获取年,然后月,最后日,使用calendar时间类获取自定义时间比较方便!
获取当前时间只需要new一个Date类,new好Date对象可以直接输出,但这个时候的输出结果不是正常看到的类型,所有要对输出的结果转换成为平常看到的类型
new一个Date类,并输出时间

输出结果

1,使用SimpleDateFormat把Date类的时间转换为我们平常看到的时间,并且获得当前时间
需要new一个SimpleDateFormat类,后缀附上需要要的时间格式,年月日的链接符可以是下划线_,斜杠/,年月日,时分秒则必须使用:字符链接,现在获取的时间会根据系统时间所变化
转换时间用:SimpleDateFormat类对象名.format(Date类对象名);

2,将一个String类型的字符串时间,转为Date类型的时间,
注意点:
1,String类型的年月日链接符要和SinpleDateFormat格式化示例的连接符一致
2,让一个Date类型直接等于格式化的时间,系统会提示错误,用一个try catch对其进行异常抛出,异常就会自动消失。
3,这个时候直接打印这个Date类型时间,输出的是我们看不明白的时间,所以SDF格式化Date类型输出即可

3,获得一个时间戳,获得一个时间戳两种形式
获取时间戳需要用:long time + System.currentTimeMillis();
第一种:获取当前系统时间的时间戳

第二种:获取一个想要时间的时间戳,比如要一个1999年11月14日的时间戳,需要使用一个String类型接收这个时间,将String类型转为Date时间类,然后使用Date时间类.getTime();输出这个时间

4,将一个时间戳转换为Date时间类
创建一个long 类型,获取一个时间戳,将这个long类型传给Date类即可

5,使用Calendar类型操作获取每个时间
创建一个Calendar时间类

使用Calendar进行获取需要的时间

如何使用Calendar时间类获取一个完整的时间
注意:下面两种获取时间的方法,尽量不要同时出现,如何既需要系统时间,又要自定义时间,可以配合Date时间类
第一种:获取当前时间
获取当前时间直接调用calendar时间类隐藏的get方法即可

第二种:获取自定义时间
获取自定义时间需要对calendar时间类隐藏的set方法进行传参,

四,I/O流
在计算机中会使用各种各样的文件来保存数据,java.io包就提供了一些这种接口,对文件进行基本操作,包括对文件进行和目录进行基本操作。
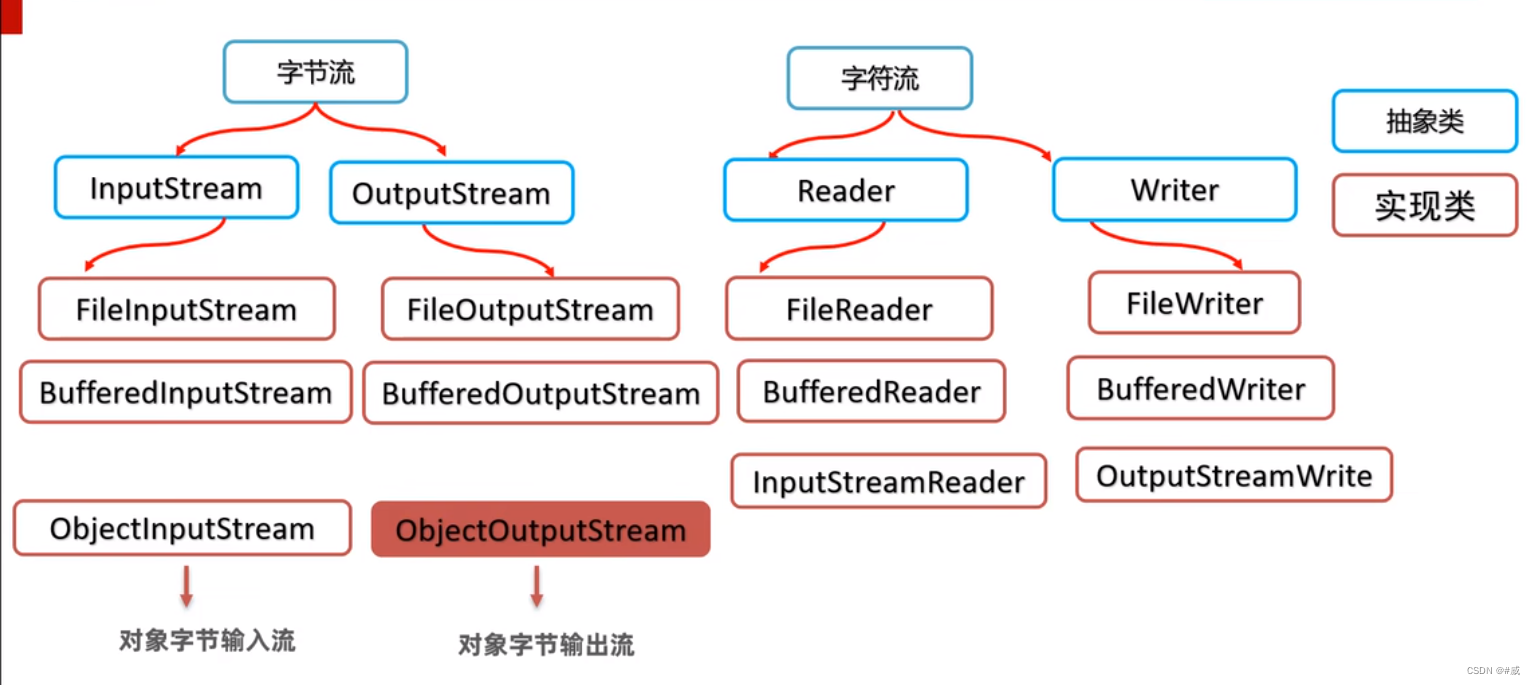
java中I/O流分类,分为两种,按照流向分类和按照数据单元格分类
流向分类:
第一种:输出流 以OutputStream和Writer为基类
第二种:出入流 以InputStream和Reader为基类
数据单元格分类:
第一种:字节流 ——输出 OutputStream ,输入 InputStream为基类
第二种:字符流 ——输出 Writer ,输入 Reader为基类
File作用和使用方法
对一个文件进行目录,属性,文件的读写等操作,首先要学会使用File类进行操作
常用方法:

1,创建File类,创建文件或文件夹,判断文件是否存在,删除文件或文件夹,查看文件或文件夹字节大小

2,相对路径和绝对路径的返回

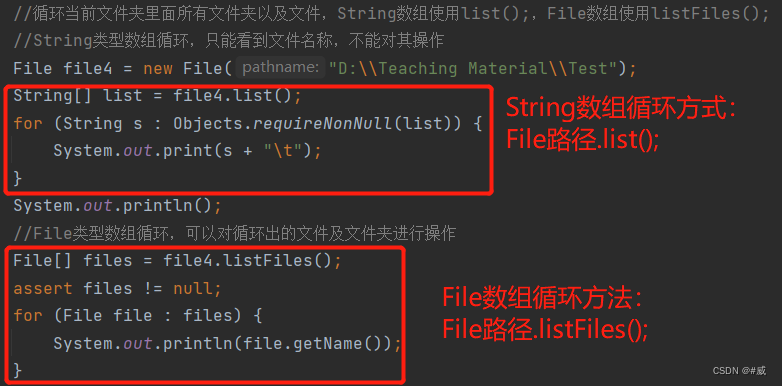
3,使用String数组和File数组循环当前文件下的文件和文件夹名称
注意:String[]循环只能查看当前文件夹名称,不能进行操作,File[]循环可以对循环出的文件或文件夹进行操作
字节流InputStream输入和OutputStream输出
字节流InputStream输入需要使用子类FileInputStream进行声明 ,
注意事项:
1,指向输入流文本时,会有异常报错,所有要进行try异常抛出,子类FileInputStream要在try异常外面进行声明,在try里面进行指向,方便try外面对子类FileInputStream进行操作。
2,字节流读取会将文本转为ASCII码,需要创建int类接收ASCII码,使用while循环遍历ASCII码,输出时需要强转为(char)类型,将文本的每一个字节遍历出来!
3,一定要将关闭流close();写入finally异常里面

字节流OutputStream输入需要使用子类FileOutputStream进行声明
注意事项:
1,指向输出流文本路径时,会有异常报错,所有要进行try异常抛出,子类FileOutputStream要在try异常外面进行声明,在try里面进行指向,方便try外面子类FileOutputStream进行操作。
2,向路径文本里面输出时,需要将输出内容传给String类,String类型.getBytes()方法;转为char类型存入byte数组,子类FileOutputStream . write(可以直接输出byte数组); 也可以子类FileOutputStream . write(从数组[]0号位,到数组最后一位length()获取数组长度);
3,可以子类FileOutputStream . write(String类型.getBytes()方法;转为char类型);
4,一定要将关闭流close();写入finally异常里面

字符流Reader输入和Writer输出
使用字符流Writer进行文本输出
注意事项:
1,Writer输出使用FileWriter这个子类进行输出,但是效率偏低,所以使用BufferedWriter这个FileWriter的子类
2,BufferedWriter不能直接指向地址,需要在里面new一个FileWriter这个父类,在FileWriter里面做路径指向
3,记得关闭输出流!!!

使用字符流Reader进行文本输入
注意事项:
1,字符流输入Reader类用子类FileReader,但是子类FileReader效率偏低,所以使用BufferedReader,这个是FileReader的子类
2,字符流不是接收ASCII,而是接收字符,所以不能使用int类型,要使用String类型,
3,while循环条件,因为判断的是String类。所以是不等于null,这里也是为什么用BufferedReader类输入,而不是使用FileReader,因为FileReader.resd();只能每次循环一个字符,而BufferedReader.resdLine()每次可以循环一个行字符,效率更高,
4,输入方法有两种
方法一:使用String接收字符时,直接在循环内遍历出来即可
方法二:使用String接收字符时,new一个StringBuffer对象,遍历StringBuffer对象.append(String字符);再循环外进行打印输入
5,谨记关闭输入流!!!

使用二进制进行照片,视频,音频的输入(DataInputStream)和输出(DataOutputStream)
使用方式输入(DataInputStream)和输出(DataOutputStream)(复制和粘贴)
注意事项:
二进制有单一图片,视频及文本的写入读取,还有多个文本,视频及文本的写入和读取方式
示例:二进制有单一图片,视频及文本的写入读取
1,读取时除了具体路径,也需要写清楚图片的名称及格式,写入时同样需要具体的写入路径,和需要写入的图片,视频的名称.格式
2,while循环条件则是int类型等于读取的二进制码,不等于-1,循环体则对int类型的二进制进行写入
3,谨记关闭I/O流

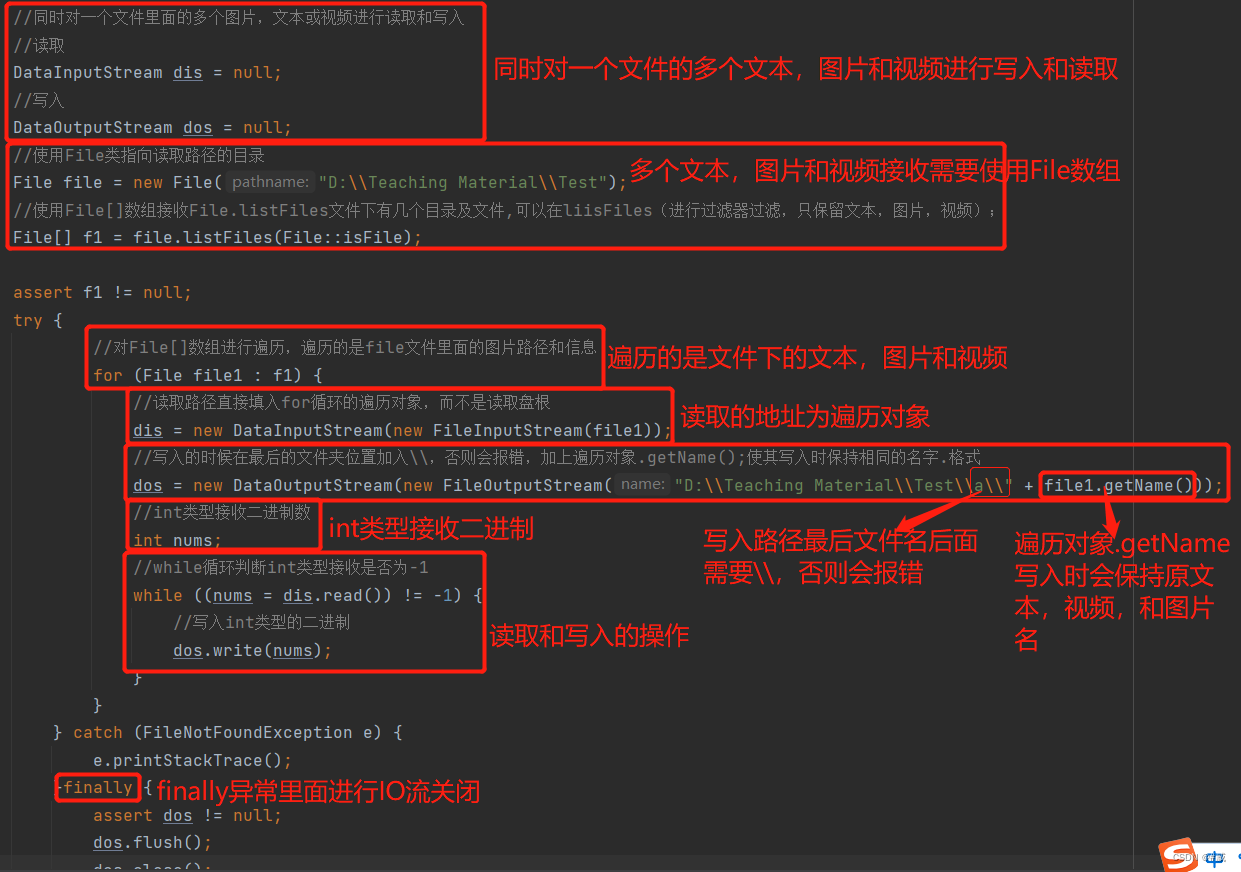
示例:同一个文件夹进行多个文本,视频及图片的写入和读取(复制和粘贴)
1,同一个文件夹进行多个文本,视频及图片的写入和读取需要使用File类指向读取的文件夹,将文件里面的文本,视频,照片从0开始存入到File[] f =File类 . listFiles();数组里面,并用过滤器进行筛选,只保留文本,图片,视频,不保留目录(就是文件夹)
2,读取地址不是文件存在的地址,而是读取遍历的对象,每遍历一次,便会更换一次读取路径
3,写入路径的最后一个地址后面加上双斜杠,后面加遍历对象.getName();这样写入时会和原文本,图片,视频保持名字.格式一致
4,谨记关闭IO流!
对象的序列化和反序列化
序列化和反序列化是对对象(Object)进行操作,所以使用ObjectOutputStream(序列化)和ObjectInputStream(反序列化)。
重点注意:如果对一个对象进行序列化,这个对象类要继承一个接口:Serializable接口,如果没有继承,程序运行将报错

一,对一个对象进行序列化和反序列化
序列化注意事项:
1,写入路径分两部分,声明写在try外面,方便finally进行关闭写入流
2,使用WriteObject方法(序列化对象);

反序列化注意事项:
1,反序列化使用ObjectInputStream声明.readObject();使用序列化类声明接收,也可以直接进行打印,如下图方法1和方法2
2,使用方法1会抛出一个异常,而且需要进行强转
3,读取路径同样需要分为两部分进行,读取声明写在try外面,方便finally进行关闭读取流

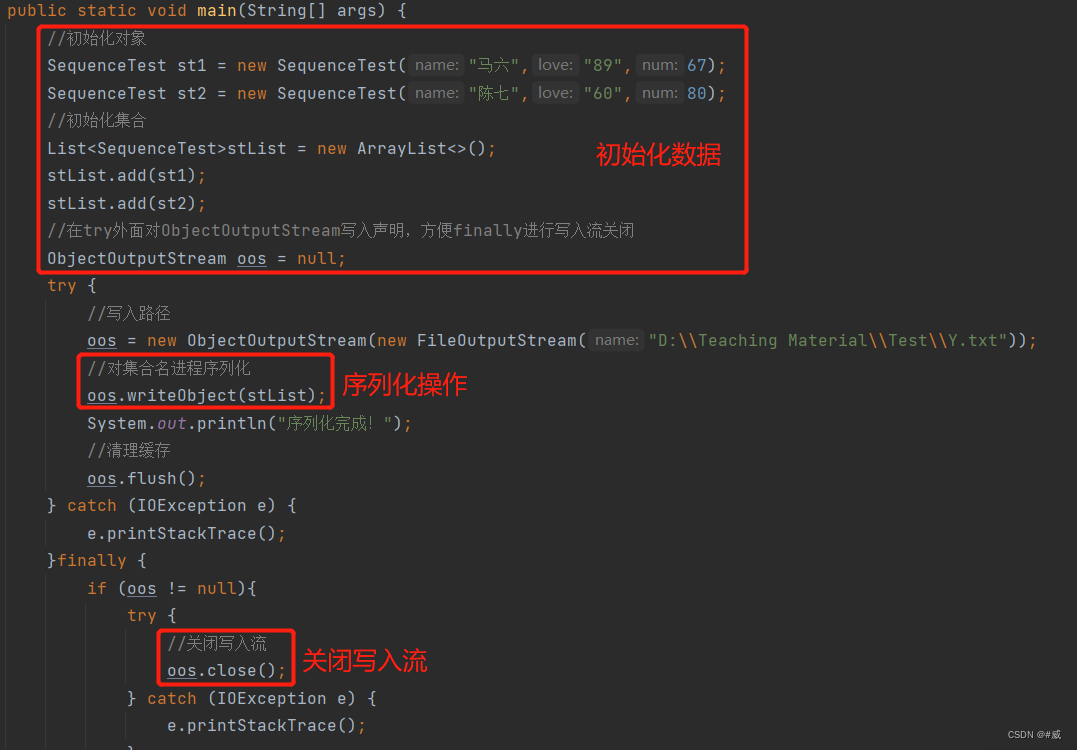
二,对一个对象集合进行序列化和反序列化
序列化集合对象注意事项:
1,序列化集合需要对集合名进行序列化,写入路径.writeObject(序列化集合对象);
2,写入路径分两部分,声明写在try外面,方便finally进行关闭写入流
反序列化集合对象注意事项:
1,需要使用集合对象进行接收,所有对集合进行声明
2,可以使用Object类型接收读取路径的字符串,再使用集合声明 = 强转为集合类型的Object类,泛型是序列化的类名
3,也可以直接使用集合声明 = 强转为集合类型的Object类,泛型是序列化的类名
4,打印方法1可以进行集合之间的换行,打印方法2则无法进行换行

五,多线程(Thread)
多线程类型:Thread
在一个进程中同时运行多个线程,来完成不同的工作,称之为 “多线程”,多线程是交替占用CPU资源,而不是并行占用,例:同时在微信给一个好友发送多张图片,每一个图片可以理解为一个线程,每个图片谁先加载完成,谁先加载完成具有不确定性。多线程也是一样,交替占用CPU资源,谁先运行具有不确定性
多线程的好处是可以充分利用CPU资源,简化编程模本,增加效率,提高用户体验感
如果创建多个线程,每个线程都会呈现出下面五个状态,除去创建状态和死亡状态。就绪状态,运行状态和堵塞状态会呈现出一个三者循环的情况,多个线程会随机一个线程占用CPU资源进行运行,如果这个线程执行完毕,就会进入死亡状态,运行的线程也可以被其他线程抢占CPU资源,这时候运行的线程就会重新进入就绪状态,等待CPU抢占再次运行,直到线程执行完毕或外部干涉终止线程。当一个线程执行中需要从控制台接收一个数据时,输入过程中的等待时间就是堵塞状态,也可以控制线程每隔多少时间运行一次,这个时间叫睡眠时间,也可以是堵塞状态

多线程创建方法有两种:
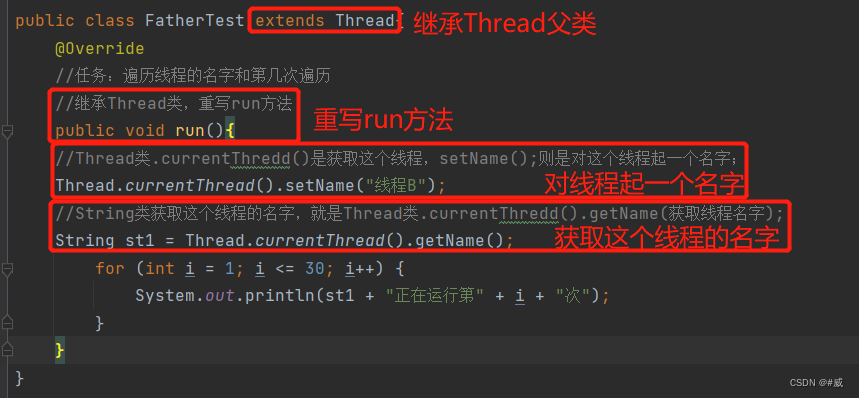
第一种:继承Thread多线程,重写run方法,在mine方法测试类中,直接new出Thread类,Thread类调用start();方法,而不是run方法,这点要切记!!
方法调用不能调用方法名run(); 而是调用start(); 如果调用run方法就不是多线程了
第二种:使用Thread父类下的子类接口,Runnable接口类,使用方法同继承Thread类一样,调用方法有所不同,主要建议使用第二种,不影响这个类去继承父类

调用方法区别于第一种的是测试类中new的继承Runnable这个类的对象无法调用start()方法,所有要在下面new出Thread这个父类,将这个接口继承类的对象传给Thread()即可,如下图:

重点注意事项:为什么调用线程类方法时,用start()方法, 而不是使用run()方法?
如果主线程直接调用run()方法,相当于走的还是主线程的路径,而调用start();方法则是直接去子线程执行run();方法,这个时候这是主线程和子线程交替执行,增加效率

结合二进制IO流将数张图片通过多线程的方法,进行读取和写入(复制粘贴)
注意事项:
1,多线程读取多个文本或图片时,File类和File[]数组写在mine方法测试类,try异常里面的二进制IO读取写入方式不变。
2,读写的路径是mine方法中传回的路径,所有要做一个File类变量,做一个有参构造进行接收

mine方法测试中做File类和File[]数组,作用就是把指定文件夹里面的文本,照片和视频存入File[]数组里,
对每个File[]数组中的文本,照片等创建对应的线程。

多线程常用方法
1,void setPriority() 只增加使用线程抢占CPU资源的概率,并不能改变优先级
2,sleep() 对使用线程进行休眠,1000=1秒,每隔多少时间抢占一次CPU资源。
3,join() 等使用线程结束,例: 线程1和线程2,在线程1中使用join() ,使用方法是线程2.join(); 运行结果是,线程1进入堵塞状态,等待线程2结束运行后,线程1恢复就绪状态,抢占CPU资源(作用于停止主线程,等待子线程运行完毕)
4,isAlive(); 判断该线程是否运行结束,这个方法和start()同级,会优先判断是否活跃,需要借助计时器进行延迟判断,或循环判断!!


使用synchronized修饰符控制线程的有序性
synchronized可以修饰方法体,也可以作用创建一个作用域
示例一:当多线程同时对一个数据进行操作时,但每次只需一个线程操作数据时,为了防止出现一个数据多个线程抢夺,这时候就需要使用synchronixed修饰符控制线程的有序性
题(多线程抢票):三个线程,抢20张票,控制两个线程抢票的数量,不能出现一张票出现多抢,漏抢和超抢情况
注意事项:
1,继承Runnable接口和对初始创建的把控
2,重写的run方法中while循环用来控制线程抢票,每一个线程抢到一张票,while循环就会重新循环,直到票卖完返回false,结束循环(下图没有做boolean值判断,while使用的死循环,初始一个boolean类型为true的变量,放入while循环条件,在票卖完的时候返回一个false结束循环即可)
3,使用synchronize修饰符创建一个boolean类型的方法,从方法体中接收数值,控制什么时候跳出while循环,重新开始
4,方法体最后返回的值和 if()选择结构保持一致
5,不能有构造方法,对线程命名可以在测试main方法中对线程命名,也不能在synchronize修饰的方法或作用域中对线程命名


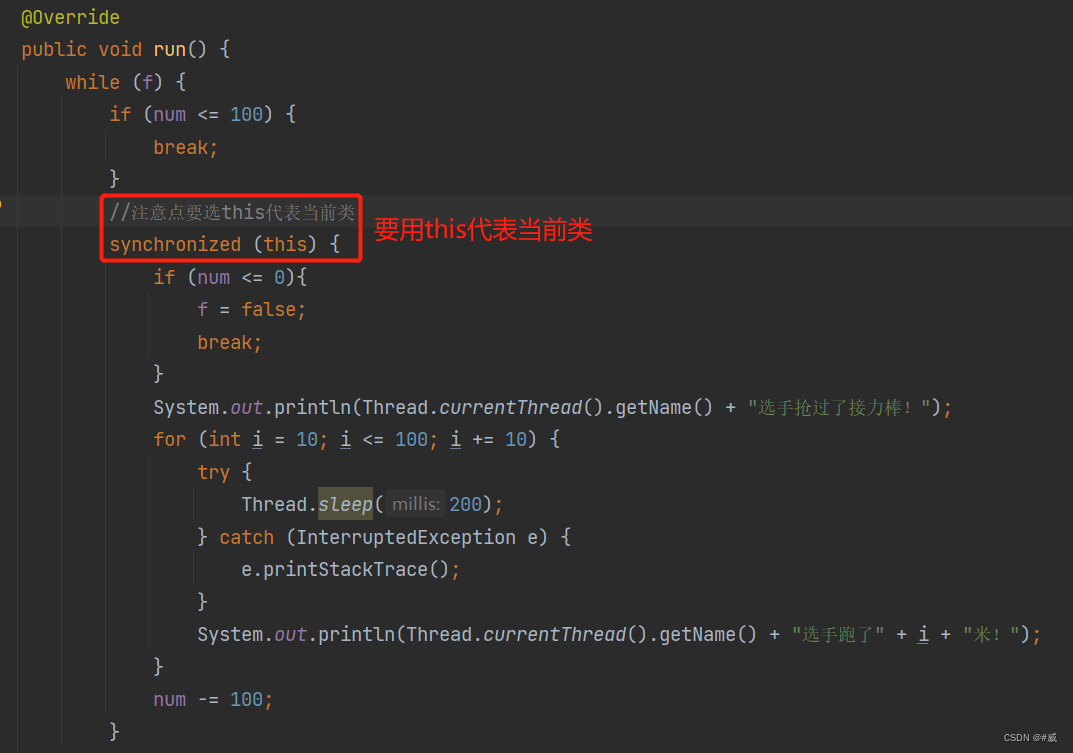
示例一:当一个线程需要多次处理
题:800米接力,一个队友跑100,然后交给下一个,每跑10米做一个提示
注意事项:
1,注意对synchronize修饰符的使用
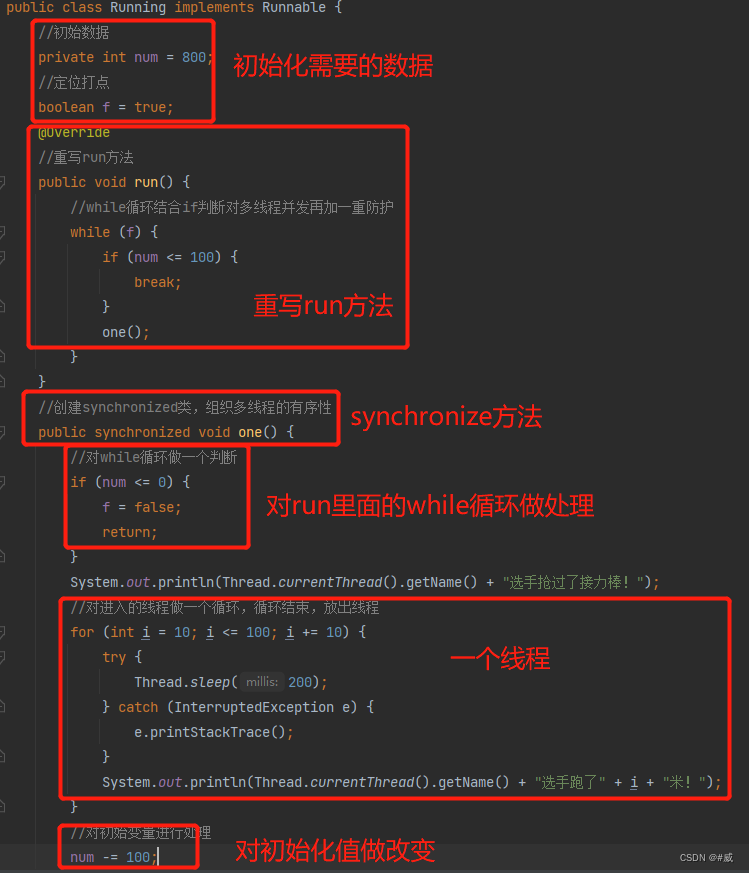
调用线程
注意事项:
1,循环命名时,有使用限制,命名只能使用String类型,而且要是数字,要将 i 使用String.valueOF进行强转,可以直接对其输出即可

在run方法里面使用synchronize创建作用域控制多线程并发异常
注意点:synchronize作用域要使用this代表当前类,其余和synchronize方法使用一样
六,网络编程
实现网络编程关键三要素
IP地址:设备在网络中的地址,是唯一的标识。
端口:应用程序在设备中唯一的标识
协议:数据在网络中传输的规则,常见的协议有UDP协议和TCP协议




七,XML文档
XML简介:
1,XML是一种很像HTML的标记语言。
2,XML的设计宗旨是用来传输数据,而不是显示数据。
3,XML的标签没有被被预定义,需要自行定义标签
4,XML是W3C的推荐标准
XML和HTML之间的差异
1,XML是用来传输和储存数据,其焦点是数据的内容
2,HTML被设计用来显示数据,其焦点是数据的外观
XML的特点:
1,XML与操作系统,编程语言的开发平台无关
2,规范统一
XML文档的结构:
1,XML声明,这是固定格式,version是版本号,encoding是文本格式
2,根元素,根元素一般是成对出现,一个在声明下第一行,另一个是在最后一行,内容都被根元素所包裹
3,开始标签,成对出现,开始标签里面的VIP是属性的一种,一个元素可以有多个属性,多个属性之间用空格隔开,属性值用双引号
4,也可以理解为标签,像编程里面变量属性
5,文本,也可以理解为属性
注意:除了XML声明,其余元素和标签都是成对出现,元素名,标签名和属性名都可以自己随意起名,没有被定义,

格式良好的XML文档
1,必须有XML声明语句
2,必须只有一个根元素
3,XML标签对大小写很敏感
4,XML标签成对出现
5,XML元素正确嵌套
6,元素名可以包含字母,数字和其他字符
7,元素不能以数字或标点符号开始
8,元素名中不能含空格
解析XML常见的四种技术
1,DOM:基于XML树结构,比较消耗资源,适用于多次访问XML
2,DOM4J:非常优秀的java,XML,API,性能优异,功能强大,开发源代码
3,SAX:基于事件,消耗资源小,适用于数据量较大的XML
4,JDOM:比DOM更快,JDOM仅使用具体类而不是使用接口
常用的两种解析方法是DOM和DOM4J两种
DOM和DOM4J解析的方法和使用
1,甲骨文公司提供了JAXP(Java API for XML Processing)来解析XML。
2,JAXP会把XML文档转换成一个DOM树。
3,JAXP包含3个包,这3个包都在JDK中:
4,org.w3c.dom:W3C推荐的用于使用DOM解析XML文档的接口。
5,org.xml.sax:用于使用SAX解析XML文档的接口。
6,javax.xml.parsers:解析器工厂工具,程序员获得并配置特殊的解析器。
注意点:org.W3c.dom是常用包,包含四个接口如下:
1,Document接口使用方法

2,Node接口

3,NodeList接口

4,Element接口


DTD文档的约束
文档约束不需要自己写,公司会提供自己的约束文档,只需要去调用文档即可,如下图:

使用字节流定位文件的好处

DOM解析方法
DOM4J解析方法
使用类有:
1,SAXReader类代表XML文档转换
2,Document接口(继承于Node)代表整个XML文档,也是XML文档的开始,
3,Element接口(同样继承于Node)代表整个XML文档的标签,也包含属性
注意事项:
1,要对xml文档的元素属性和标签做一个初始类,也就是创建有参无参构造方法,set和get方法和toString方法,作用是对xml做映射
2,正确使用接口















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









