







 本文探讨了现有文本到音频生成模型的局限,提出通过构建偏好数据集和使用Diffusion-DPO进行微调,以优化音频概念匹配和时间顺序。这种方法在数据有限情况下提高了音频生成质量,预示着技术的未来发展潜力。
本文探讨了现有文本到音频生成模型的局限,提出通过构建偏好数据集和使用Diffusion-DPO进行微调,以优化音频概念匹配和时间顺序。这种方法在数据有限情况下提高了音频生成质量,预示着技术的未来发展潜力。
基于扩散模型的文本到音频生成:突破数据局限,优化音频概念与时间顺序
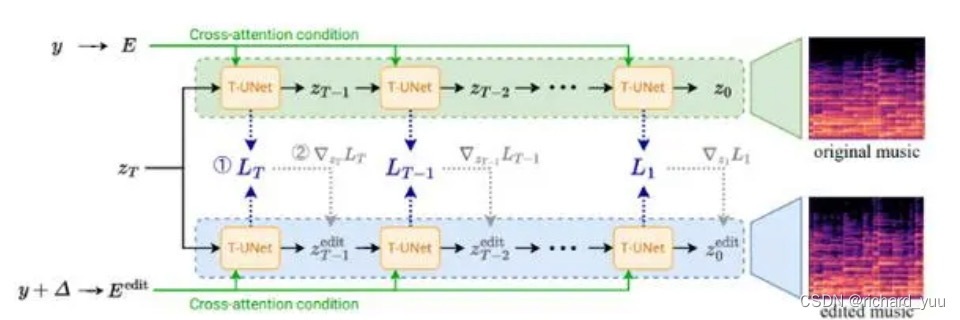
随着数字化技术的迅猛发展,音乐和电影行业对音频生成技术的需求日益旺盛。其中,从文本提示生成音频的技术正成为研究的热点。然而,现有的基于扩散模型的文本到音频生成方法,往往受限于数据集的大小和复杂性,难以准确捕捉并反映输入提示中的概念与事件的时间顺序。近日,一篇新的论文提出了一种在数据有限的情况下提升音频生成性能的方法,引发了业界的广泛关注。
一、现有模型的局限与挑战
当前,许多基于扩散模型的文本到音频方法主要依赖于大量的提示音频对进行训练。虽然这些模型在音频生成方面取得了一定的进展,但它们并没有显式地关注输出音频与输入提示之间的概念匹配和事件顺序。这导致了生成的音频中可能出现概念缺失、顺序混乱等问题,无法满足高质量音频生成的需求。
二、偏好数据集的构建与利用
为了克服上述局限,研究团队提出了一种新的方法。他们首先利用现有的文本到音频模型Tango,合成创建了一个偏好数据集。在这个数据集中,每个文本提示都对应着一组音频输出,其中包括一个与提示高度匹配的“好”音频输出和若干个与提示不匹配或匹配度较低的“不合适”音频输出。这些不合适的音频输出中,往往包含了概念缺失或顺序错误的问题,为模型提供了宝贵的学习机会。
三、Diffusion-DPO损失的应用与模型微调
接下来,研究团队利用扩散-DPO
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









