









文章目录
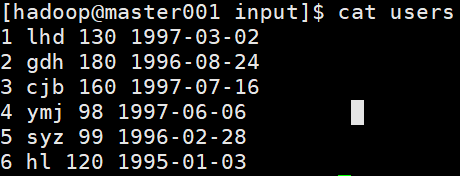
1. 创建测试数据
vi users
1 lhd 130 1997-03-02
2 gdh 180 1996-08-24
3 cjb 160 1997-07-16
4 ymj 98 1997-06-06
5 syz 99 1996-02-28
6 hl 120 1995-01-03
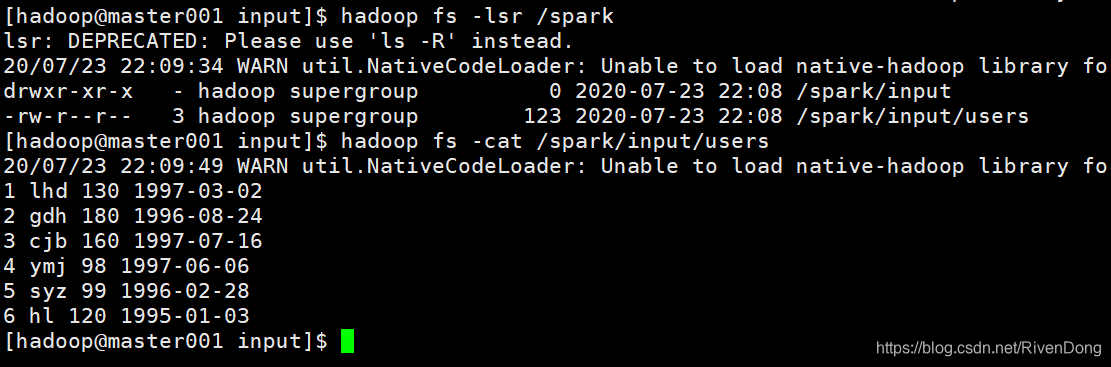
hadoop fs -mkdir -p /spark/input
hadoop fs -put users /spark/input
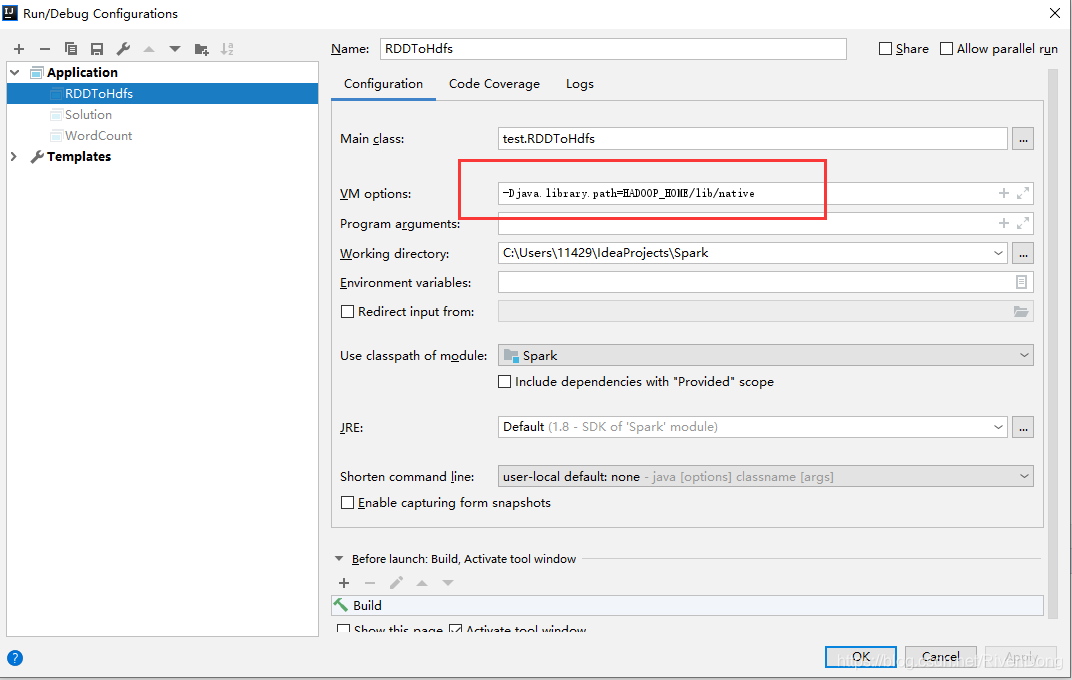
2. IDEA配置
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Spark</groupId>
<artifactId>Spark</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.6.5</hadoop.version>
<spark.version>2.3.3</spark.version>
</properties>
<dependencies>
<!--添加Spark依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!--添加Scala依赖-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--添加Hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
</project>
每个样例都需要添加:
3. 实例代码
3.1 通过反射方式将RDD转换成DataFrame
注意:
- 自定义类需要实现可序列化接口并实现toString()方法
- 自定义类的访问级别是public
User.java
package test;
import java.io.Serializable;
import java.sql.Date;
/**
* @author lhd
*/
public class User implements Serializable {
private Long userId;
private String userName;
private Integer weight;
private Date birthday;
User(Long userId, String userName, Integer weight, Date birthday){
this.userId = userId;
this.userName = userName;
this.weight = weight;
this.birthday = birthday;
}
private void setUserId(Long userId) {
this.userId = userId;
}
public Long getUserId() {
return userId;
}
private void setUserName(String userName) {
this.userName = userName;
}
public String getUserName() {
return userName;
}
private void setWeight(Integer weight) {
this.weight = weight;
}
public Integer getWeight() {
return weight;
}
private void setBirthday(Date birthday) {
this.birthday = birthday;
}
public Date getBirthday() {
return birthday;
}
@Override
public String toString(){
return userId + " " + userName +
" " + weight + " " + birthday;
}
}
RDDToHdfs.java
package test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.SparkSession;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.sql.Date;
/**
* @author lhd
*/
public class RDDToHdfs {
private static FileSystem fs;
private static final String HDFS = "hdfs://master001:9000";
static{
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
try {
fs = FileSystem.get(new URI(HDFS), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("RDD To HDFS Cluster");
conf.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(SparkSession.builder().sparkContext(sc.sc()).getOrCreate());
JavaRDD<String> lineRDD = sc.textFile(HDFS + "//spark//input");
JavaRDD<User> userRDD = lineRDD.map(new Function<String, User>() {
public User call(String line) throws Exception {
String[] fields = line.split(" ");
Long userId = Long.parseLong(fields[0]);
String userName = fields[1];
Integer weight = Integer.parseInt(fields[2]);
Date birthday = Date.valueOf(fields[3]);
return new User(userId, userName, weight, birthday);
}
});
//遍历获取到的userRDD---------------------------------------------------------
userRDD.foreach(new VoidFunction<User>() {
public void call(User user) throws Exception {
System.out.println(user.getUserId() + " " + user.getUserName() +
" " + user.getWeight() + " " + user.getBirthday());
}
});
//----------------------------------------------------------------------------
Dataset<Row> userDataSet = sqlContext.createDataFrame(userRDD, User.class);
userDataSet.createOrReplaceTempView("user");
Dataset<Row> queryDataSet = sqlContext.sql("select * from user where weight > 100");
JavaRDD<Row> rowRDD = queryDataSet.toJavaRDD();
JavaRDD<User> userRDDResult = rowRDD.map(new Function<Row, User>() {
public User call(Row row) throws Exception {
Long userId = (Long) row.getAs("userId");
String userName = (String) row.getAs("userName");
Integer weight = (Integer) row.getAs("weight");
Date birthday = (Date) row.getAs("birthday");
return new User(userId, userName, weight, birthday);
}
});
Path dist = new Path(HDFS + "//spark//output");
try {
if(fs.exists(dist))
fs.delete(dist, true);
} catch (IOException e) {
e.printStackTrace();
}
userRDDResult.saveAsTextFile(HDFS + "//spark//output");
}
}

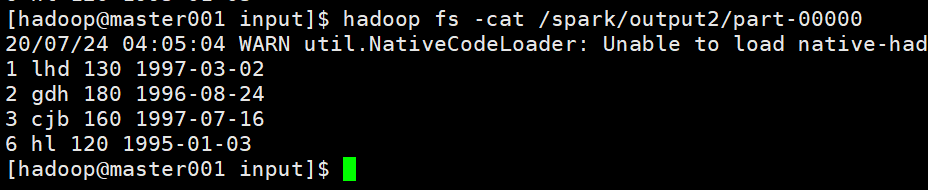
3.2 通过创建Schema自定义格式的方式
RDDToHdfsTwo.java
package test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.io.IOException;
import java.io.Serializable;
import java.net.URI;
import java.net.URISyntaxException;
import java.sql.Date;
import java.util.Arrays;
import java.util.List;
/**
* @author lhd
*/
public class RDDToHdfsTwo implements Serializable{
private Long userId;
private String userName;
private Integer weight;
private Date birthday;
private RDDToHdfsTwo(Long userId, String userName, Integer weight, Date birthday) {
this.userId = userId;
this.userName = userName;
this.weight = weight;
this.birthday = birthday;
}
private static FileSystem fs;
private static final String HDFS = "hdfs://master001:9000";
static{
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
try {
fs = FileSystem.get(new URI(HDFS), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("RDD To HDFS Cluster");
conf.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(SparkSession.builder().sparkContext(sc.sc()).getOrCreate());
JavaRDD<String> lineRDD = sc.textFile(HDFS + "//spark//input");
JavaRDD<Row> rowRDD = lineRDD.map(new Function<String, Row>() {
public Row call(String str) throws Exception {
String[] fields = str.split(" ");
return RowFactory.create(
Long.parseLong(fields[0]),
fields[1],
Integer.parseInt(fields[2]),
Date.valueOf(fields[3])
);
}
});
List<StructField> asList = Arrays.asList(
DataTypes.createStructField("userId", DataTypes.LongType, true),
DataTypes.createStructField("userName", DataTypes.StringType, true),
DataTypes.createStructField("weight", DataTypes.IntegerType, true),
DataTypes.createStructField("birthday", DataTypes.DateType, true)
);
StructType schema = DataTypes.createStructType(asList);
Dataset<Row> userDataSet = sqlContext.createDataFrame(rowRDD, schema);
userDataSet.createOrReplaceTempView("user");
Dataset<Row> queryDataSet = sqlContext.sql("select * from user where weight > 100");
JavaRDD<Row> midRDD = queryDataSet.toJavaRDD();
JavaRDD<RDDToHdfsTwo> resultRDD = midRDD.map(new Function<Row, RDDToHdfsTwo>() {
public RDDToHdfsTwo call(Row row) {
Long userId = (Long) row.getAs("userId");
String userName = (String) row.getAs("userName");
Integer weight = (Integer) row.getAs("weight");
Date birthday = (Date) row.getAs("birthday");
return new RDDToHdfsTwo(userId, userName, weight, birthday);
}
});
Path dist = new Path(HDFS + "//spark//output2");
try {
if(fs.exists(dist))
fs.delete(dist, true);
} catch (IOException e) {
e.printStackTrace();
}
resultRDD.saveAsTextFile(HDFS + "//spark//output2");
}
@Override
public String toString(){
return userId + " " + userName +
" " + weight + " " + birthday;
}
}
3.3 通过读取json文件的方式创建
json文件:
{"userId":1, "userName":"lhd","weight":130,"birthday":"1997-03-02"}
{"userId":2, "userName":"gdh","weight":180,"birthday":"1996-08-24"}
{"userId":3, "userName":"cjb","weight":160,"birthday":"1997-07-16"}
{"userId":4, "userName":"ymj","weight":98,"birthday":"1997-06-06"}
{"userId":5, "userName":"syz","weight":99,"birthday":"1996-02-28"}
{"userId":6, "userName":"hl","weight":120,"birthday":"1995-01-03"}
RDDToHdfsJson.java
package test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.*;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author lhd
*/
public class RDDToHdfsJson {
private static FileSystem fs;
private static final String HDFS = "hdfs://master001:9000";
static{
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
try {
fs = FileSystem.get(new URI(HDFS), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("RDD To HDFS Cluster");
conf.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(SparkSession.builder().sparkContext(sc.sc()).getOrCreate());
Dataset<Row> userDataSet = sqlContext.read().format("json").load(HDFS + "//spark//input2//user.json");
userDataSet.show();
}
}

4. 注意
JavaRDD当中如果使用自定义的泛型类进行数据的转换、传输,必须继承Serializable接口,并实现toString()方法。














 3121
3121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









