







 本文介绍了如何运用Naive Bayes分类器构建垃圾邮件过滤器。首先阐述了该方法的总体思想,包括训练过程和预测机制。接着详细讲解了过滤器的实现步骤,并分享了测试结果,展示其在识别垃圾邮件方面的效能。
本文介绍了如何运用Naive Bayes分类器构建垃圾邮件过滤器。首先阐述了该方法的总体思想,包括训练过程和预测机制。接着详细讲解了过滤器的实现步骤,并分享了测试结果,展示其在识别垃圾邮件方面的效能。
原理分析
总体思想
利用Naive Bayes(后验概率)计算特征所属空间的概率,取其最大者为判定结果。
如下,其中P表示概率,w表示所属类别。

对于Prior,可用如下公式进行计算:

对于Likelihood中独立同分布的各项概率,可用如下公式计算:
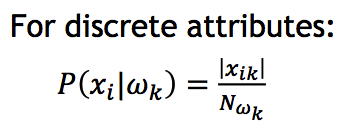
训练
输入为上万封电子邮件内容,包含垃圾邮件/非垃圾邮件。提取邮件内单词,改写为小写单词输入字典,过滤出现1次的单词,过滤长度只有1的单词,过滤出现总次数超过1万次的单词,最后形成我们的统计词典以及垃圾/非垃圾邮件词典。
预测
定义probSPAM = probHAM = 1
输入一封邮件,抽取其单词,对上述词典中的每一个单词进行处理:
1)在垃圾邮件词典中,若单词A
出现在当前邮件中,那么probSPAM *= (垃圾邮件中该单词出现次数)/(垃圾邮件数量);
2)在垃圾邮件词典中,若单词A
没有出现在当前邮件中,那么probSPAM *= [1-(垃圾邮件中该单词出现次数)/(垃圾邮件数量)];
3)在非垃圾邮件词典中,若单词A
出现在当前邮件中,那么probHAM *= (正常邮件中该单词出现次数)/(正常邮件数量);
4)在非垃圾邮件词典中,若单词A
没有出现在当前邮件中,那么probHAM *= [1-(正常邮件中该单词出现次数)/(正常邮件数量)];
完成统计后,两个prob变量分别乘以(对应类别的邮件数)/(所有邮件总数),即 Prior。
比较probSPAM以及probHAM,哪个相对较大就判定为对应空间。
实现
数据以及代码下载地址:
用Python代码实现
其中,计算概率使用了log函数简化乘除法,
计算单个特征点概率时使用了smoothing:
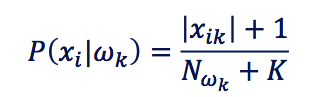
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sun May 19 18:54:36 2013
@author: rk
"""
import nltk
import os
import math
train_data = "./hw1_data/train/"
test_data = "./hw1_data/test/"
ham = "ham/"
spam = "spam/"
MAX_NUM = 10000
K = 2
def sort_by_value(d):
return sorted(d.items(), lambda x, y: cmp(x[1], y[1]), reverse = True)
def word_process( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









