







• 实施新的分区方法
• 采用数据压缩
• 使用Enterprise Manager 创建SQL 访问指导分析会话
• 使用PL/SQL 创建SQL 访问指导分析会话
• 设置SQL 访问指导分析以获取分区建议案
- Oracle 分区
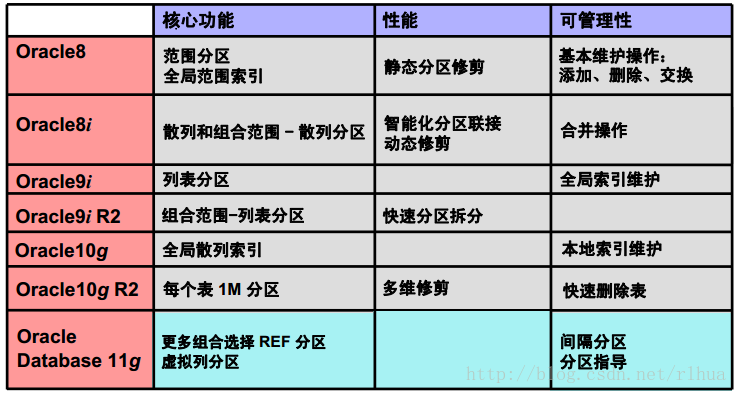
Oracle 分区
此图片概括了Oracle 分区功能的十年发展过程。
注:REF 分区支持对子表进行修剪和智能化分区联接。虽然性能方面的改善似乎是最明显
的,但也不要忽略其它方面的改进。分区必须考虑性能、可管理性和可用性等所有业务相
关领域。
- 分区增强功能
• 间隔分区
• 系统分区
• 组合分区增强功能
• 基于虚拟列的分区
• 引用分区
分区增强功能
分区是一种管理大型数据库的重要工具。分区使DBA可以采用“分而治之”的方法管理
数据库表(尤其是那些不断增长的表)。经过分区的表允许数据库在保持性能一致的同
时,进行扩展以适应超大型的数据集,而不会对管理或硬件资源产生不当的影响。
分区可以加快对Oracle DB 中数据的访问速度。不管数据库有10 GB 还是10 TB 的数据,
分区都可以使数据的访问速度提高几个数量级。
随着Oracle Database 11g的推出,DBA 将会发现一系列有用的分区增强功能。这些增强
功能包括:
• 增加了间隔分区
• 增加了系统分区
• 增强了组合分区
• 增加了基于虚拟列的分区
• 增加了引用分区
- 间隔分区
• 间隔分区是范围分区的一种扩展
• 当插入的数据超过了所有范围分区时,将创建指定间隔
的分区。
• 必须至少创建一个范围分区。
• 间隔分区可以自动创建范围分区。
间隔分区
在引入间隔分区之前,DBA 需要显式定义每个分区的值范围。问题在于,为每个分区显
式定义的界限不会随着分区数量的增长而扩展。
间隔分区是范围分区的一种扩展,它会在插入表中的数据超过了所有范围分区时,指示数
据库自动创建特定间隔的分区。必须至少指定一个范围分区。范围分区的键值可以确定范
围分区的上限值(称为转换点),数据库将为超过该转换点的数据创建间隔分区。
间隔分区可以完全自动地创建范围分区。管理新分区的创建可能是一项重复性很高的繁重
任务。对于可预测性地增加涵盖小范围的分区,如添加新的每日分区,这种情况尤其突
出。间隔分区可以通过按需创建分区来自动完成此类操作。
使用间隔分区时,需要考虑以下限制条件:
• 只能指定一个分区键列,并且该键列必须是NUMBER或DATE类型。
• 索引表不支持间隔分区。
• 不能为间隔分区表创建域索引。
- 间隔分区:示例
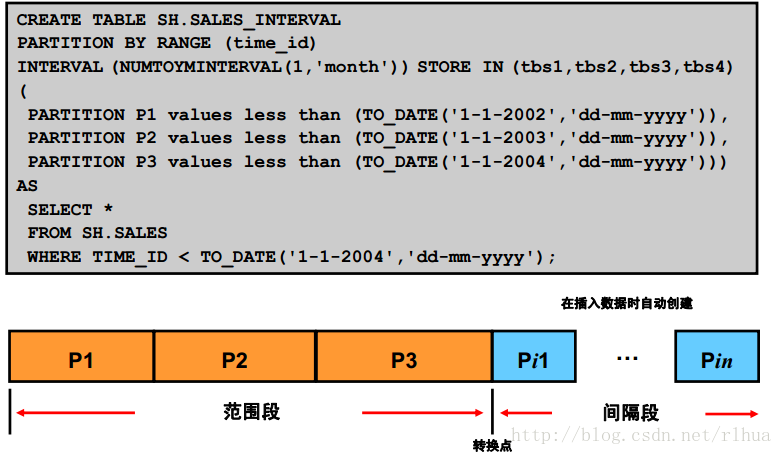
间隔分区:示例
图片中的示例显示了间隔分区表的创建过程。最初的CREATE TABLE语句指定了四个宽
度不同的分区。表的这部分采用的是范围分区。该语句还指定了在晚于转换点“1-1-2004”
时,将创建宽度为一个月的分区。这些分区是间隔分区。在表中插入一个包含与2004 年1
月对应的值的行时,将使用此信息自动创建分区Pi1。分区P3 的上限代表一个转换点。P3
与其之前的所有分区(本例中的P1 和P2)都在范围段中,而P3 之后的所有分区则在间隔
段中。INTERVAL子句的唯一参数是一个间隔类型常量。目前,只能指定一个分区键列,
该键列必须是DATA或NUMBER类型。
可以使用INTERVAL子句的可选子句STORE IN来指定一个或多个表空间,数据库会以
循环方式将间隔分区数据存储到指定的表空间中。
- 移动转换点:示例
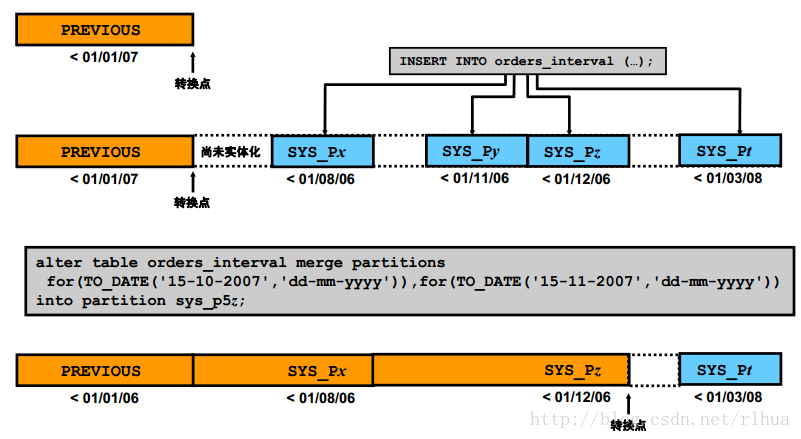
移动转换点:示例
图片中的图形展示了一个典型的信息生命周期管理(ILM) 方案,在该方案中,自动创建
了一年的分区之后,将合并这些已创建的分区(示例中的SYS_Py和SYS_Pz)以移动转
换点。然后,可以将产生的分区移到一个不同的存储中供ILM 使用。
该示例假定您创建了一个表ORDERS_INTERVAL,该表有一个初始范围分区
PREVIOUS,其中存放着2007 年之前的订单。定义的间隔为一个月。然后,在2007 年和
2008 年中插入了一些订单,并且假定创建了四个分区。这些分区如图中所示,它们是根
据一些系统规则自动命名的。
接下来,您决定使用图片中所示的ALTER TABLE语句合并2007 年的最后两个分区。
您必须合并两个相邻的分区。请注意新的扩展分区语法,使用该语法可以在不知道分区名
称的情况下指定分区。该语法使用的表达式必须表示相关分区的可能值。此语法适用于必
须引用分区的所有情况,而不管引用的是范围分区、列表分区、间隔分区还是散列分区。
它支持所有操作,如删除、合并、拆分等。
执行了MERGE操作后,就可以看到转换点发生了移动了。图形的底部显示了现在包含三
个分区的新范围段。
注:可以更改间隔分区表的间隔,现有的间隔不受影响。
- 系统分区
系统分区:
• 为选定的表启用应用程序控制的分区
• 具有分区的优点,但分区和数据的放置由应用程序控制
• 不像其它分区方法那样采用分区键
• 不支持传统意义上的分区修剪
系统分区
使用系统分区可以对任意表进行应用程序控制的分区。在开发自己的分区域索引时,这种
方法很有用。数据库提供的功能只是将表细分为无意义的分区。分区的其它所有方面都由
应用程序控制。系统分区具备分区的常见优势(可扩展性、可用性和可管理性),但分区
和实际数据的放置由应用程序控制。
系统分区与其它方法之间最基本的差别是系统分区
没有任何分区键。因此,不能将行隐式
分配或映射到特定的分区。相反,用户要在插入行时使用扩展分区语法来指定行要映射到
的分区。
因为系统分区表没有分区键,所以系统分区表没有分区表通常所具备的性能优势。具体地
说,就是不支持传统的分区修剪、智能化分区联接等功能。分区修剪是通过访问与在基表
中访问的分区相同的系统分区表中的分区完成的。
系统分区表具有均匀分区的可管理性优势。例如,可创建一个嵌套表作为系统分区表,该
表与基表有相同的分区数。域索引的备份可以由与基表有相同分区数的系统分区表来进
行。
- 系统分区:示例
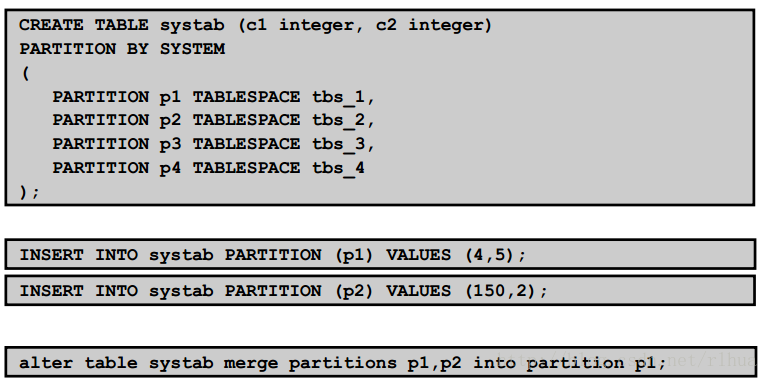
系统分区:示例
图片示例中的语法将创建一个包含四个分区的表。每个分区可以有不同的物理属性。
INSERT和MERGE语句必须使用扩展分区语法来确定行应插入的特定分区。例如,可以
将值(4,5) 插入到示例中指定的四个分区中的任何一个分区。
删除和更新不需要使用扩展分区语法。但是,由于没有分区修剪功能,所以,如果省略扩
展分区语法,则将扫描整个表以执行操作。此示例也突出了不存在行到任何分区的隐式映
射这一事实。
- 系统分区:准则
系统分区表支持以下操作:
• 分区维护操作和其它DDL 操作
• 创建本地索引
• 创建本地位图化索引
• 创建全局索引
• 所有DML 操作
• 使用扩展分区语法的INSERT SELECT:
INSERT INTO <table_name> PARTITION(<partition-name>) <subquery>
系统分区:准则
系统分区表支持以下操作:
• 分区维护操作和其它DDL(请参见下面的例外)
• 创建本地索引
• 创建本地位图化索引
• 创建全局索引
• 所有DML 操作
• 使用扩展分区语法的INSERT SELECT
由于系统分区的特殊要求,它不支持以下操作:
• 不支持需要分区键的唯一本地索引
• 不支持没有分区方法的CREATE TABLE AS SELECT。无法将行分配到分区,而应
先创建表,然后将行插入到各个分区。
• SPLIT PARTITION操作
- 基于虚拟列的分区
• 虚拟列值是通过计算函数或表达式得到的。
• 可以在CREATE或ALTER表操作中定义虚拟列。
CREATE TABLE employees
(employee_id number(6) not null,
…
total_compensation as (salary *( 1+commission_pct))
• 虚拟列值实际上并未存储在磁盘上的表行中,而是根据
需要进行计算。
• 像其它表列类型一样,可以对虚拟列进行索引,可以在
查询、DML 和DDL 语句中使用它们。
• 可在虚拟列上对表和索引进行分区,甚至可以收集它们
的统计信息。
基于虚拟列的分区
如果某个表的列值是通过
计算函数或表达式得到的,则这些列就称为虚拟列。可以在
CREATE或ALTER表操作过程中指定这些列。虚拟列与其它实际表列共享相同的SQL 名
称空间,并与对其进行描述的基础表达式的数据类型相一致。可像其它表列一样在查询中
使用这些列,因此可在SQL 语句中提供简单、优美且一致的访问表达式机制。
虚拟列的值实际上并未存储在磁盘上的表行中,而是根据需要进行计算。描述虚拟列的函
数或表达式应是明确且无掺杂的,即相同的输入值集应返回相同的输出值。
可以像使用任何其它表列一样使用虚拟列。可对虚拟列进行索引,可在查询、DML 和
DDL 语句中使用它们。可在虚拟列上对表和索引进行分区,甚至可以收集它们的统计信
息。
可使用虚拟列分区对表的虚拟列上定义的键列进行分区。对逻辑分区对象的业务要求经常
与现有列不一一对应。随着Oracle Database 11g的推出,分区功能得到了增强,可以在虚
拟列上定义分区策略,因而可以更加全面地匹配业务要求。
- 基于虚拟列的分区:示例
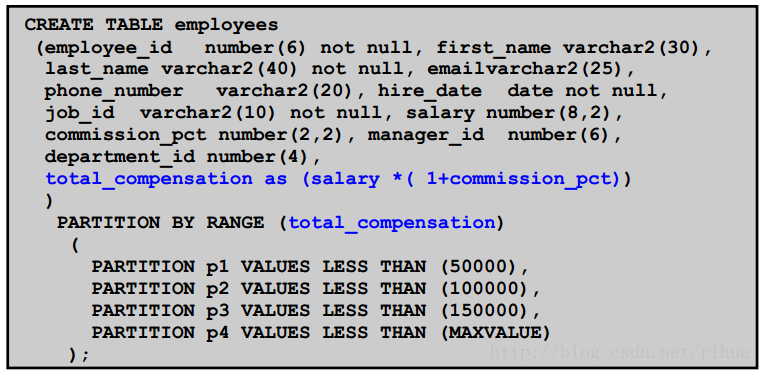
基于虚拟列的分区:示例
请考虑该图片中的示例。EMPLOYEES表是使用标准的CREATE TABLE语法创建的。
total_compensation列是一个虚拟列,其值的计算方式为:将salary的值与
commission_pct加1之后的值相乘。下一个语句将total_compensation(虚拟
列)声明为EMPLOYEES表的分区键。
如果分区键上的谓词属于以下类型之一,则将对虚拟列分区键执行
分区修剪:
• 等式或Like
• 列表
• 范围
• 扩展分区名称
如果两个表之间存在联接操作,则优化程序将确定智能化分区联接(完全或部分)的适用
时间,决定是否使用智能化分区联接,并在决定使用时正确注释该联接。这既适用于串行
情况也适用于并行情况。
为了确定完全智能化分区联接,优化程序将依赖于对两个对象的均匀分区的定义;此定义
包括表据以分区的虚拟表达式的等同性。
- 引用分区
• 现在,可以根据表的引用约束条件中引用的此表的分区
方法对表进行分区。
• 分区键是通过现有的父/子关系解析的。
• 分区键是由活动的主键和外键约束条件强制实施的。
• 包含父/子关系的表可以通过从父表继承分区键进行均匀
分区,而无需复制键列。
• 分区是自动维护的。
引用分区
通过引用分区,可以根据表的引用约束条件中引用的此表的分区方案,对表进行分区。
分区键是通过现有的父/子关系解析的,并由活动的主键和外键约束条件强制实施。这种
方式的优势在于:包含父/子关系的表可以通过从父表继承分区键来进行逻辑均匀分区,
而无需复制键列。逻辑相关性也会自动级联分区维护操作,从而使应用程序的开发变得更
简单、更不容易出错。
- 引用分区:优点
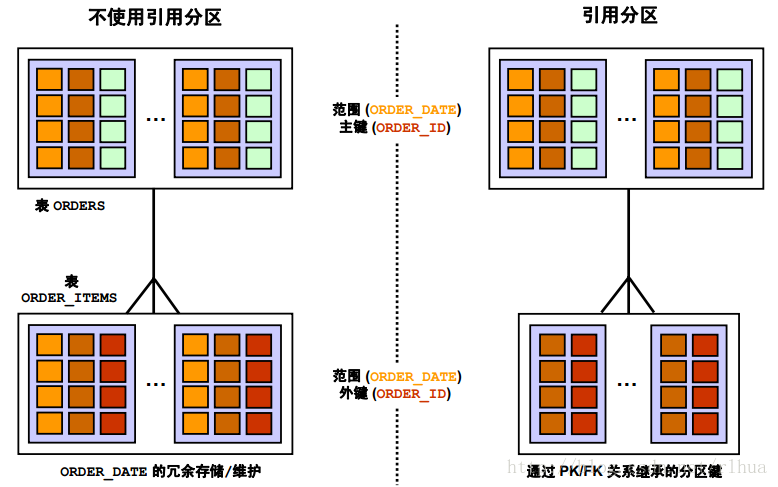
引用分区:优点
如图片中所示,您可以看到使用引用分区的优点。左侧的图形显示了有两个表ORDERS
和ORDER_ITEMS时的情况,它们按ORDER_DATE列进行均匀分区。在这种情况下,两
个表都需要定义ORDER_DATE列。但是,在ORDER_ITEMS表中定义ORDER_DATE是
多余的,因为在两个表之间存在主键/外键关系。
右侧的图形显示了使用引用分区时的情况。在这种情况下,不再需要在ORDER_ITEMS
表中定义ORDER_DATE列。ORDER_ITEMS表的分区键会从现有的主键/外键关系中进行
自动继承。
在用于修剪和智能化分区联接时,引用分区具有以下优势:可以使用不同的查询谓词,
智能化分区联接仍然有效,例如,按ORDER_DATE进行分区,并对ORDER_ID进行搜
索。在以前的版本中,只有分区和谓词相同时智能化联接才有效。
注:这种分区方法对嵌套表分区很有用。
- 引用分区:示例
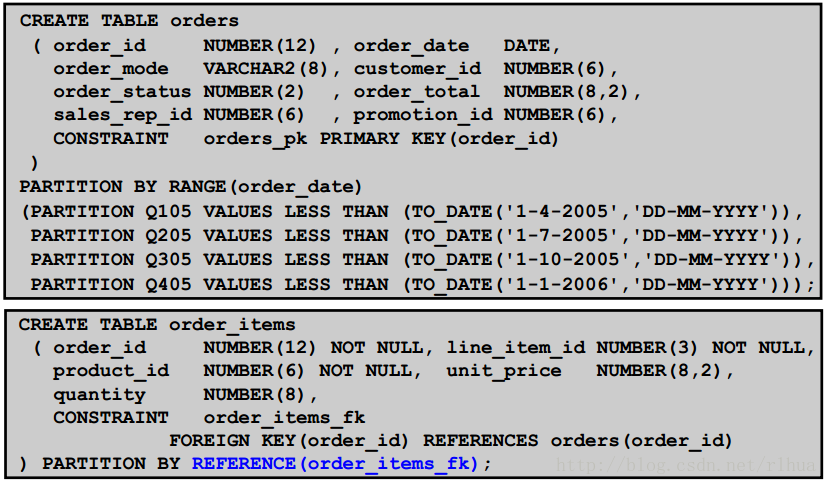
引用分区:示例
图片中的示例创建了两个表:
• ORDERS:按order_date分区的范围分区表。该表在创建时包含四个分区Q105、
Q205、Q305和Q405。
• ORDER_ITEMS:引用分区子表:
- 该表在创建时包含四个分区Q105、Q205、Q305和Q405,每个分区均包含与
各自父分区中的ORDERS对应的行。
- 如果提供了分区描述符,则描述的分区数量必须与引用表中的分区或子分区的数
量完全相同。
- 如果父表是组合分区表,则对于父表的每个子分区该表都有一个分区。
- 不能为引用分区表的分区指定分区界限。除非与继承的名称存在冲突,否则可以
命名引用分区表的分区。在这种情况下,系统将为分区生成一个名称。
- 如果未显式指定表空间,则引用分区表的分区将与父表的对应分区并列排列。与
其它分区表一样,可以指定对象级的默认属性和覆盖对象级默认值的分区描述
符。
- 不能禁用引用分区表的外键约束条件。
- 不允许添加或删除引用分区表的分区。但是,在父表上执行分区维护操作将自动
级联到子表。
- 组合分区增强功能

组合分区增强功能
Oracle Database 11g之前的版本仅支持范围-列表和范围-散列组合分区方法。在此新版本
中,列表分区可以是组合分区表的顶级分区方法,为用户提供列表-列表、列表-散列、
列表-范围和范围-范围组合方法。随着间隔分区功能的推出,现在还支持间隔-范围、
间隔-列表和间隔-散列组合分区方法。
范围-范围分区
范围-范围组合分区可以在两个维上进行逻辑范围分区,例如,按order_date的范围
分区和按shipping_date的范围子分区。
列表-范围分区
列表-范围组合分区可以按指定的列表分区策略进行逻辑范围子分区,例如,
按country_id的列表分区和按order_date的范围子分区。
列表-散列分区
列表-散列组合分区可以对列表分区对象进行散列子分区,例如,启用智能化分区联接。
列表-列表分区
列表-列表组合分区可以在两个维上进行逻辑列表分区,例如,按country_id的列表
分区和按sales_channel的列表子分区。
- 范围-范围分区:示例

范围-范围组合分区:示例
范围-范围组合分区可以在两个维上进行逻辑范围分区。图片中的示例创建了SALES
表,并按time_id进行了范围分区。使用子分区模板对SALES表按范围进行了子分
区,并使用cust_id作为子分区键。
由于使用了模板,所有分区都有相同的子分区数,并且具有模板所定义的相同界限。如果
未指定模板,则将以MAXVALUE值(范围)或DEFAULT值(列表)创建一个默认分区
界限。
虽然该示例显示的是范围-范围方法,但其它新的组合分区方法也使用相似的语法和语句
结构。所有组合分区方法都完全支持对涉及子分区键谓词的查询使用现有的分区修剪方
法。
- 表压缩:概览
• Oracle Database 11g扩展了OLTP 数据的压缩。
– 支持常规的DML 操作
(INSERT、UPDATE、DELETE)
• 新算法显著降低了写入开销。
– 批量压缩可确保大多数OLTP 事务处理不会受到影响。
• 对读取无影响
– 由于减少了I/O 次数并提高了内存效率,因此读取性能可
能会有实际上的提高。
表压缩:概览
Oracle DB 是数据库压缩技术方面的先行者,在Oracle9i中就引入了针对批量装载操作的
表压缩功能。使用此功能可以在使用直接装载或Create Table As Select (CTAS) 等操作执
行批量装载时压缩数据。但在以前,一些常规数据操纵操作(如INSERT、UPDATE和
DELETE)却不能使用压缩功能。Oracle Database 11g对压缩技术进行了扩展,也可以支
持这些操作。因此,Oracle Database 11g中的压缩功能可用于各种工作量,不管是联机事
务处理(OLTP) 还是数据仓库。
必须指出的是,Oracle database 11g中引入的表压缩功能的增强并不只是增量更改。为了
确保新的压缩技术对更新只造成微乎其微的影响,已经进行了大量的工作,因为在OLTP
环境中压缩导致的任何明显的写入时间增加都是不可接受的。因此,Oracle Database 11g
中的压缩技术非常高效,可以使空间消耗减少50-75%。执行压缩操作时,不但写入性能
不会降低,而且读取性能或查询速度都会有提高。这是因为,与必须等待解压缩数据的桌
面压缩技术不同,Oracle 技术直接读取压缩的数据(减少了所需的提取次数),不需要执
行任何解压缩操作。
注:压缩技术对应用程序是完全透明的。也就是说,可以将此技术用于任何自有的或打包
的应用程序(如SAP、Siebel、EBS 等)。
- 表压缩的概念
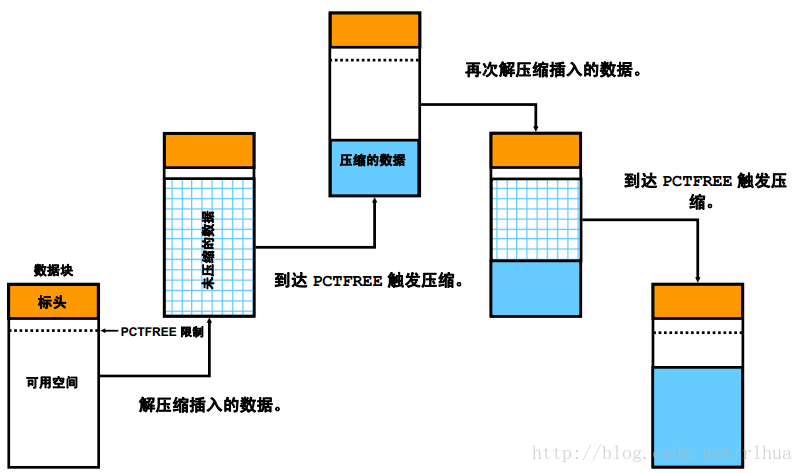
表压缩的概念
该图片显示了压缩表中的数据块的演化过程,应按从左到右的顺序阅读。开始的时候,
该数据块是空的,可以插入数据。开始在此块中插入数据时,数据以未压缩的格式存储
(就像在未压缩的表中一样)。但是,只要到达了该块的PCTFREE,数据将被自动压
缩,以减少其原来占据的空间。这样一来,可以在相同的块中插入新的未压缩数据,直到
再一次到达PCTFREE。此时会再一次触发压缩以减少块中的占用空间。
注:压缩可以消除删除操作造成的空隙,最大化块中的连续空闲空间。
- 使用表压缩
• 数据库兼容级别需要在11.1 或更高
• 新的语法扩展了COMPRESS关键字:
– COMPRESS [FOR{ALL| DIRECT_LOAD} OPERATIONS]
– FOR DIRECT_LOAD是默认值:引用以前版本中的批量装载操作
– FOR ALL OPERATIONS:OLTP + 直接装载
• 对新表启用压缩:
CREATE TABLE t1 COMPRESS FOR ALL OPERATIONS;
• 对现有的表启用压缩:
ALTER TABLE t2 COMPRESS FOR ALL OPERATIONS;
– 对现有的行不触发压缩
使用表压缩
要使用新的压缩算法,必须使用COMPRESS FOR ALL OPERATIONS子句标记表。可以
在创建表时或在创建表之后执行此操作。幻灯片中的示例演示了此操作。
如果使用COMPRESS子句但没有指定任何FOR选项,或者使用COMPRESS FOR
DIRECT_LOAD OPERATIONS子句,则将退回到以前版本中提供的旧压缩机制。
也可以在分区级别或表空间级别启用压缩。例如,可以使用CREATE TABLESPACE命令
的DEFAULT存储子句,根据需要指定COMPRESS FOR子句。
注:可以使用DBA_TABLES和DBA_TAB_PARTITIONS等视图中的COMPRESS列和
COMPRESS_FOR列查看表的压缩标志。
- SQL 访问指导:概览
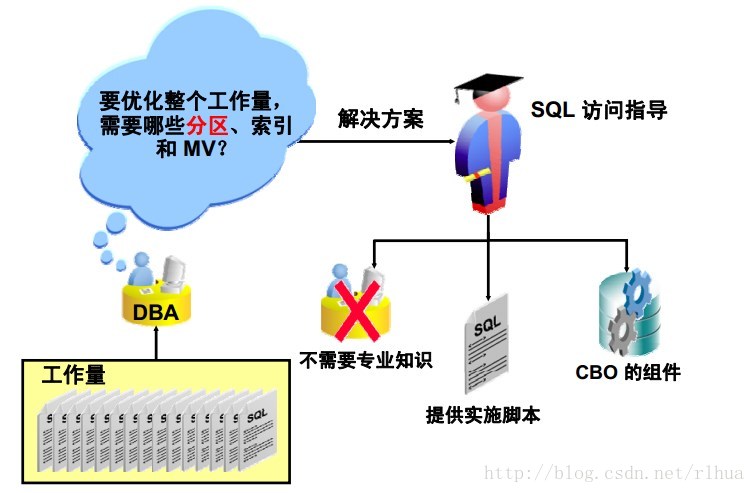
SQL 访问指导:概览
如何定义适当的访问结构以优化SQL 查询一直是Oracle DBA 关心的问题。因此,为了解
决该问题,相关人员已经写了大量的论文和脚本,还开发了一些高端工具。此外,随着分
区和实体化视图技术的发展,确定访问结构也变得更加复杂。
作为Oracle Database 10g 和11g中的可管理性增强功能,引入了SQL 访问指导来解决这
个非常关键的需求。
SQL 访问指导可以推荐要创建、删除或保留的索引、实体化视图、实体化视图日志或分
区,从而确定并帮助解决与执行SQL 语句相关的性能问题。可以从Database Control 或者
从命令行使用PL/SQL 过程来运行SQL 访问指导。
SQL 访问指导将输入实际工作量,或者根据方案导出一个假想工作量。然后,它会推荐
速度较快的执行路径的访问结构。SQL 访问指导具有以下优点:
• 不需要拥有专业知识
• 根据基于成本的优化程序中实际存在的规则做决定
• 与优化程序以及Oracle DB 增强功能同步
• 是涵盖SQl 访问方法所有方面的单个指导
• 提供用户友好的简单GUI 向导
• 生成可用于实施建议案的脚本
- SQL 访问指导:使用模型
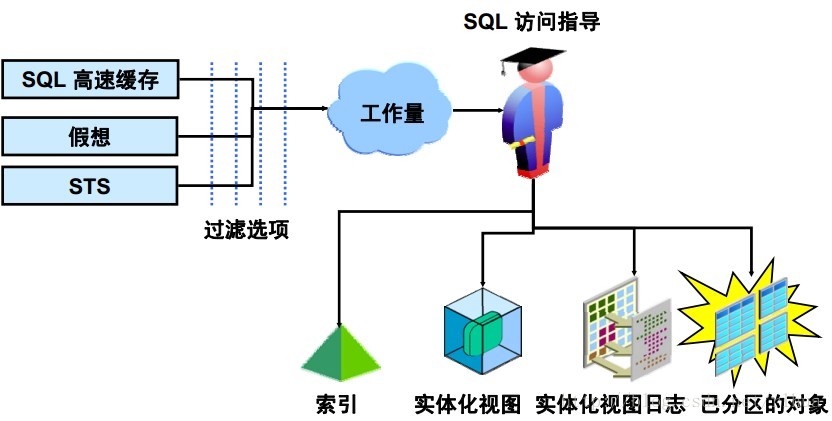
SQL 访问指导:使用模型
SQL 访问指导将输入一个从多个来源派生出来的工作量:
•SQL 高速缓存,采用V$SQL的当前内容
• 假想工作量,根据维模型生成一个可能工作量。在初次设计系统时,这个选项比较有用
•SQL 优化集,来自工作量资料档案库
SQL 访问指导还提供强大的工作量过滤功能,可用于确定优化目标。例如,用户可以指定
SQL 访问指导只观察工作量中30 个资源最密集的语句(根据优化程序开销确定)。对于指定
的工作量,SQL 访问指导随后会执行以下操作:
• 同时考虑索引解决方案、实体化视图解决方案、分区解决方案或者全部三个解决方案的
组合
• 考虑存储的创建和维护成本
• 不为部分工作量生成删除建议案
• 优化实体化视图以最大化查询重写使用率和快速刷新
• 建议用于快速刷新的实体化视图日志
• 建议对表、索引和实体化视图进行分区
• 将类似的索引组合为单个索引
• 生成支持多个工作量查询的建议案
- 可能的建议案
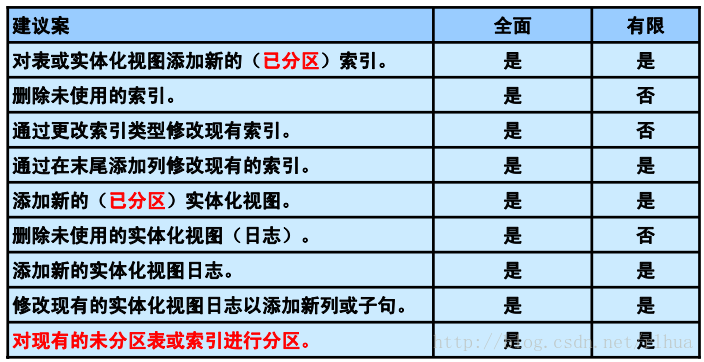
可能的建议案
SQL 访问指导会仔细考虑建议案的整体影响,并仅使用已知的工作量和提供的信息生成
建议案。可以使用两种工作量分析方法:
• 全面:SQL 访问指导通过这种方法解决优化分区、实体化视图、索引和实体化视图日
志的所有方面。SQL 访问指导假定工作量包含一个完整的有代表性的应用程序SQL
语句集。
• 有限:与全面的工作量方法不同,有限的工作量方法假定工作量仅包含有问题的SQL
语句。因此,将寻求提高一部分应用程序环境性能的建议。
如果选择了全面的工作量分析,则SQL 访问指导将生成一个较好的全局优化调整集,但
所需分析时间会比较长。如表中所示,选择的工作量方法可决定SQL 访问指导生成的建
议案类型。
注:分区建议案仅对至少包含10,000行的表以及在NUMBER或DATE类型的列上有一些
谓词或联接的工作量有效。只能针对这些类型的列生成分区建议。此外,只能为单列间隔
分区和散列分区生成分区建议。间隔分区建议案可作为范围语法输出,但间隔是默认值。
执行散列分区只是为了利用智能化分区联接。
- SQL 访问指导会话:初始选项
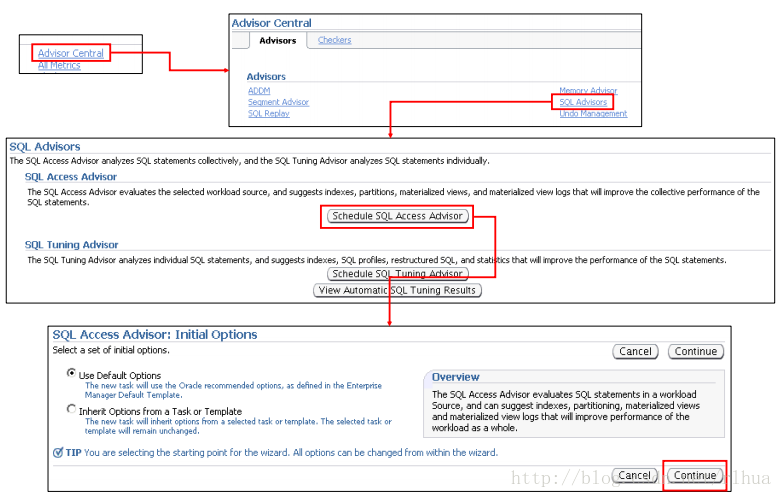
SQL 访问指导会话:初始选项
接下来的几张幻灯片将介绍一个典型的SQL 访问指导会话。可以通过数据库主页上的
“Advisor Central(指导中心)”链接访问SQL 访问指导向导,也可以通过单个预警页或
性能页进行访问,这些页可能包含用于简化性能问题解决过程的链接。SQL 访问指导向
导包括多个步骤,可在执行这些步骤的过程中提供要优化的SQL 语句,以及要使用的访
问方法类型。
使用“SQL Access Advisor: Initial Options(SQL 访问指导:初始选项)”页可以选择在启
动向导前用来植入默认选项的模板或任务。可以单击“Continue(继续)”启动向导,或
者单击“Cancel(取消)”返回到“Advisor Central(指导中心)”页。
注:在生成建议案的过程中,SQL 访问向导可能会中断,从而允许您复查结果。
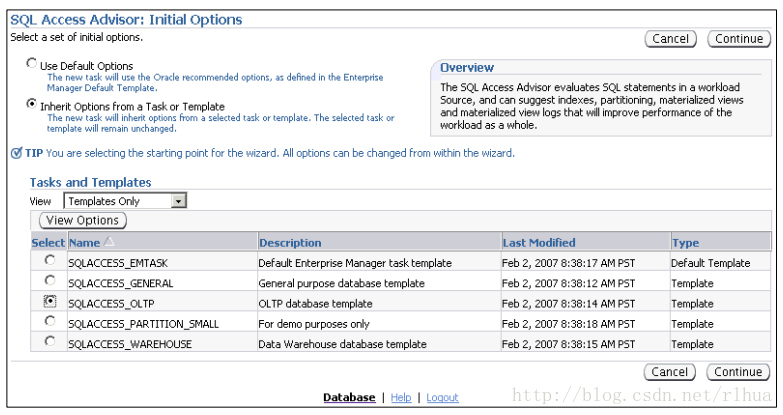
如果在“Initial Options(初始选项)”页上选择了“Inherit Options from a Task or
Template(从任务或模板继承选项)”选项,则可以选择一个现有的任务或模板以继承
SQL 访问指导的选项。默认情况下,将使用SQLACCESS_EMTASK模板。
通过选择相应的对象并单击“View Options(查看选项)”,可以查看任务或模板定义的
各种选项。
- SQL 访问指导:工作量来源
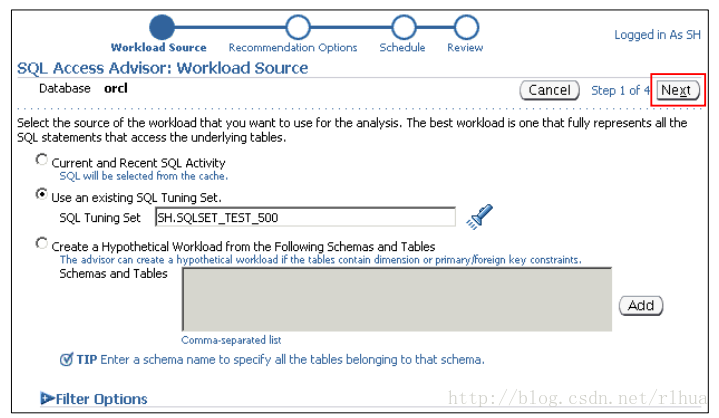
SQL 访问指导:工作量来源
可以从三个不同的来源中选择工作量来源:
• Current and Recent SQL Activity(当前和最近的SQL活动):此来源对应于仍高速
缓存在SGA 中的SQL 语句。
• Use an existing SQL Tuning Set(使用现有的SQL 优化集):也可以创建并使用存放
语句的SQL 优化集。
• Hypothetical Workload(假想的工作量):此选项将提供允许指导搜索维表并生成工
作量的方案。此来源在初始设计方案时很有用。
使用“Filter Options(过滤选项)”部分可以进一步过滤工作量来源。过滤选项有:
• Resource Consumption(资源消耗):按优化程序成本、缓冲区获取数、CPU 时间、
磁盘读取数、占用时间、执行数排序的语句数量。
•Users(用户)
•Tables(表)
• SQL Text(SQL 文本)
• Module IDs(模块ID)
• Actions(操作)
- SQL 访问指导:建议案选项

SQL 访问指导:建议案选项
使用“Recommendations Options(建议案选项)”页可以选择是否限制SQL 访问指导基
于单个访问方法提出建议案。可以选择SQL 访问指导要推荐的结构的类型。如果没有选
择三个可能值中的任何一个,则SQL 访问指导将评估现有的结构,而不尝试推荐新结
构。
可以使用“Advisor Mode(指导模式)”部分,以两种模式之一运行指导。这些模式会
影响建议案的质量和处理所需的时间。在“Comprehensive Mode(综合模式)”中,SQL
访问指导将搜索候选的大型池,以便得到最高质量的建议案。在“Limited Mode(限制模
式)”中,SQL 访问指导将快速执行,通过仅处理最高成本的语句来限制候选建议案。
- SQL 访问指导:建议案选项
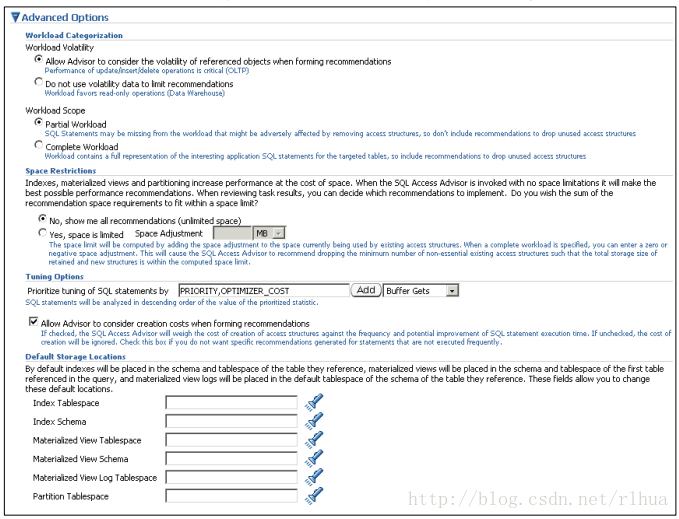
SQL 访问指导:建议案选项(续)
可以选择“Advanced Options(高级选项)”以显示或隐藏选项,这些选项可用于设置空
间限制、优化选项和默认存储位置。使用“Workload Categorization(工作量类别)”部
分可以设置“Workload Volatility(工作量不稳定性)”和“Workload Scope(工作量范
围)”选项。对于工作量不稳定性,可以选择关注只读操作,也可以考虑生成建议案时被
引用对象的不稳定性。对于工作量范围,可以选择“Partial Workload(部分工作量)”,
其中不包括要删除未使用访问结构的建议案;或者选择“Complete Workload(全部工
作量)”,其中包括要删除未使用访问结构的建议案。
使用“Space Restrictions(空间限制)”部分可指定硬性空间限制,强制指导仅使用不超
过指定限制的总空间要求生成建议案。使用“Tuning Options(优化选项)”部分可指定
用于定制指导生成的建议案的选项。使用“Prioritize Tuning of SQL Statements by(确定优
化SQL 语句优先级的依据)”下拉列表,可以按“Optimizer Cost(优化程序成本)”、
“Buffer Gets(缓冲区获取数)”、“CPU Time(CPU 时间)”、“Disk Reads(磁盘读
取数)”、“Elapsed Time(占用时间)”和“Execution Count(执行计数)”划分优
先级。使用“Default Storage Locations(默认存储位置)”部分可以覆盖为方案和表空间
位置定义的默认值。默认情况下,索引放置在所引用表的方案和表空间中。实体化视图放
置在相应用户的方案和表空间中,该用户将执行为实体化视图建议案提供信息的一个查
询。
注:Oracle 强烈建议您为实体化视图指定默认方案和表空间。
- SQL 访问指导:调度和复查
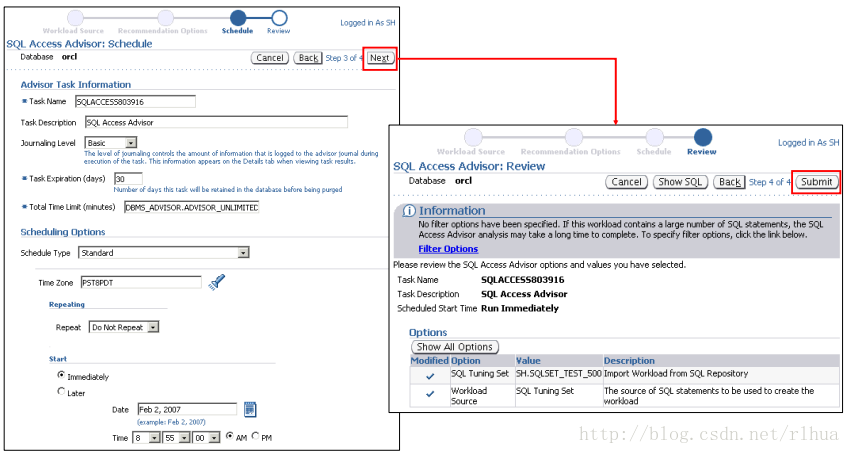
SQL 访问指导:调度和复查
您随后可以通过指定调度程序的各种参数,调度并提交新的分析。本幻灯片的屏幕快照中
显示了可能的选项。
- SQL 访问指导:结果
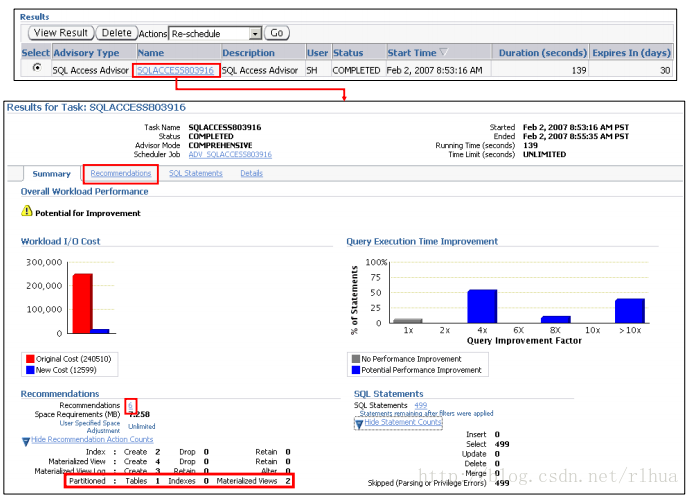
SQL 访问指导:结果
通过“Advisor Central(指导中心)”页,可以检索用于分析的任务详细资料。通过选择
“Advisor Central(指导中心)”页上“Results(结果)”部分中的任务名称,可以访问
“Results for Task(任务结果)”的“Summary(概要)”页;可在此页上看到SQL 访问
指导查找结果的概览。该页中显示了图表和统计信息,为建议案提供了整体工作量性能和
改善查询执行时间方面的可能性。使用该页可以显示语句计数和建议案操作计数。
- SQL 访问指导:结果
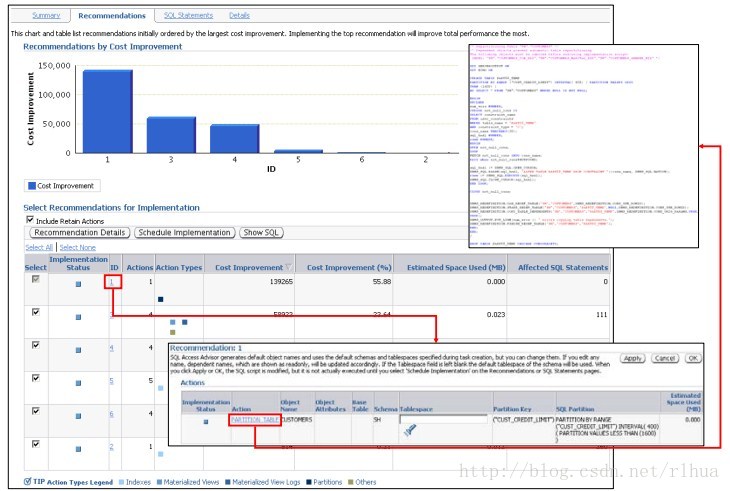
SQL 访问指导:结果(续)
要查看SQL 访问指导任务结果的其它方面,可选择该页上其它三个选项卡之一:
“Recommendations(建议案)”、“SQL Statements(SQL 语句)”或“Details(详细
资料)”。
在“Recommendation(建议案)”页上,可以细化到各个建议案。对于其中的每个建议
案,可以查看“Select Recommendations for Implementation(选择要实施的建议案)”表
中的重要信息。然后,可以选择一个或多个建议案,并安排实施。
如果单击特定建议案的ID,则将进入“Recommendation(建议案)”页,该页显示了指
定建议案的所有操作,可以根据需要修改语句的表空间名称。完成了任何更改后,单击
“OK(确定)”将应用更改。通过该页可以查看一个操作的完整文本,方法是选择指定
操作的“Action(操作)”字段中的链接。单击“Show SQL(显示SQL)”可以查看建
议案中所有操作的SQL。
- SQL 访问指导:结果
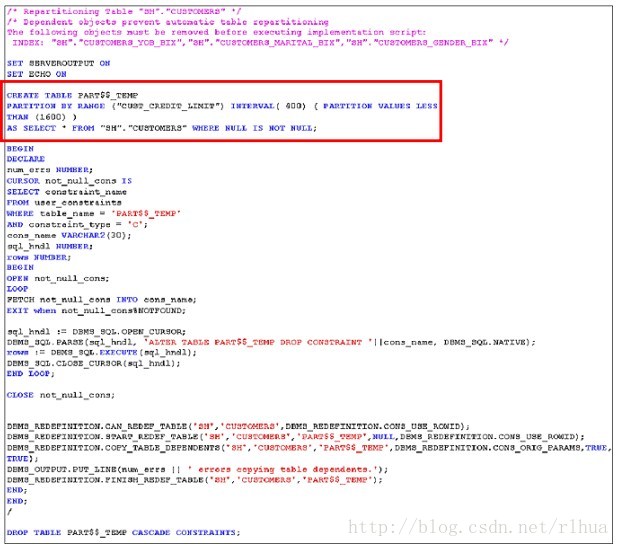
SQL 访问指导:建议案实施
可以使用简单的SQL DDL 语句在生产系统中执行大多数建议案。在这些情况下,SQL 指
导会生成可执行的SQL 语句。在有些情况下(例如,重新分区现有的已分区表或现有的
从属索引),简单的SQL 是不够的。此时,SQL 指导将生成调用外部程序包的脚本
(如DBMS_REDEFINITION),使用户可以实施建议的更改。
在幻灯片的示例中,SQL 访问指导建议按CUST_CREDIT_LIMIT列对SH.CUSTOMERS
表进行分区。该建议案使用INTERVAL分区方案,并将第一个值范围定义为小于1600。
间隔分区是基于数值范围或日期时间间隔的分区。间隔分区是范围分区的一种扩展,它会
在插入表中的数据超过了所有范围分区时,指示数据库自动创建特定间隔的分区。
- SQL 访问指导:结果
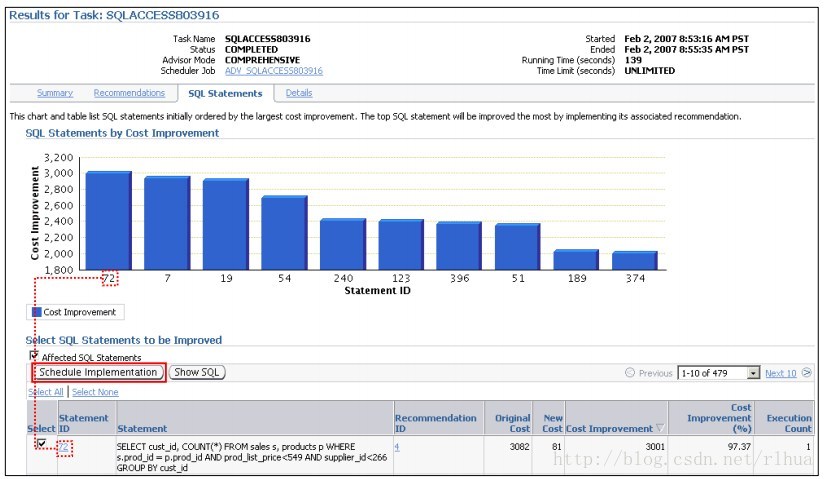
SQL 访问指导:结果
“SQL Statements(SQL 语句)”页显示了一个图表和一个对应的表,其中列出了按成本
改善程度由高到低初始排序的SQL 语句。最上面的SQL 语句通过实施关联建议案得到了
最大程度的改善。
- SQL 访问指导:结果
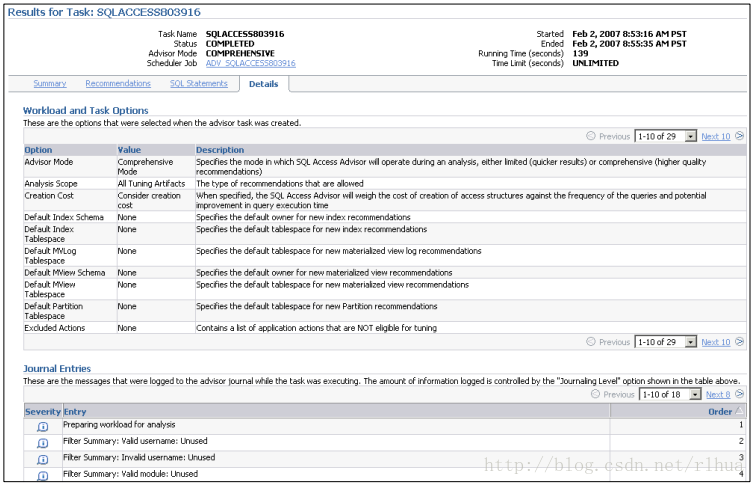
SQL 访问指导:结果(续)
“Details(详细资料)”页显示了创建任务时所用的工作量和任务选项。此页还提供了在
任务执行过程中记录的所有日记条目。
- SQL 访问指导:PL/SQL 过程流程
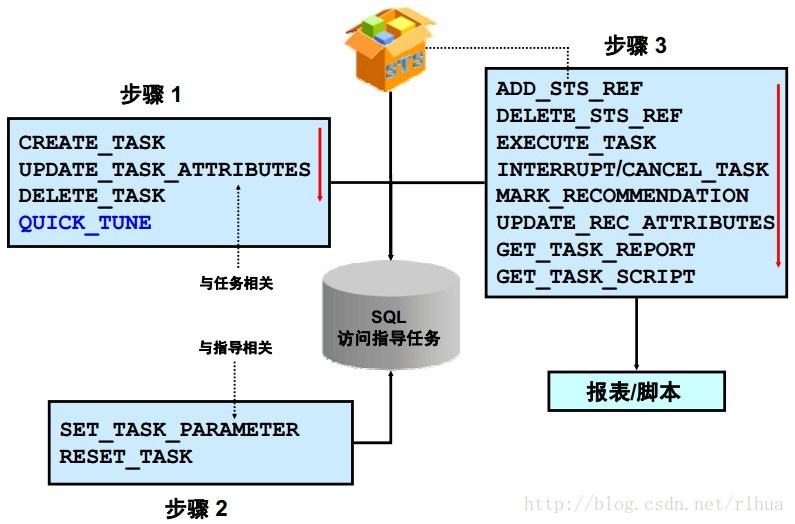
SQL 访问指导:PL/SQL 过程流程
图形显示了DBMS_ADVISOR程序包中SQL访问指导过程的典型操作流程。
• 步骤1:创建并管理任务和数据。此步骤将使用一个SQL访问指导任务。
• 步骤2:准备任务以进行各种操作。此步骤将使用SQL 访问指导参数。
• 步骤3:准备并分析数据。此步骤将使用SQL 优化集和SQL 访问指导任务。使用
Oracle Database 11gR1,除了文本之外,GET_TASK_REPORT还可以使用HTML 或
XML 返回报告。
注:DBMS_ADVISOR.QUICK_TUNE过程是一种快捷方式,可以执行分析单个SQL 语句
所必需的所有操作。该操作将创建一个所有参数都为默认值的任务,工作量仅由指定的语
句组成。最后将执行任务,并将结果保存到资料档案库中。也可以指示该过程实施最终建
议案。
SQL 访问指导:PL/SQL 示例
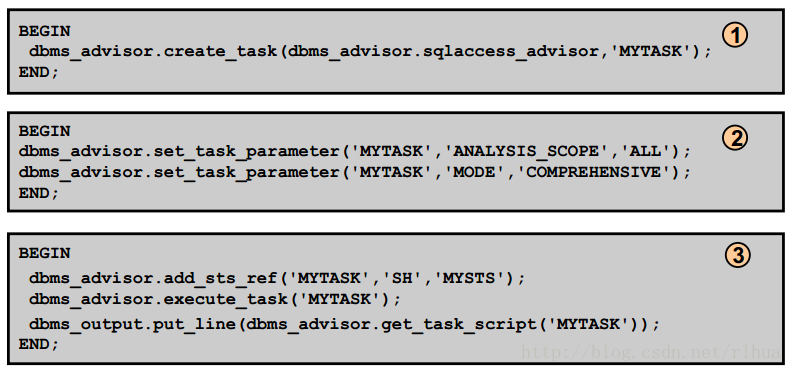
SQL 访问指导:PL/SQL 示例
与前一张幻灯片中所示的顺序相配合,此幻灯片中的示例显示了使用PL/SQL 代码的一个
可能的SQL 访问指导优化会话。
第一个PL/SQL 块创建了一个新的优化任务MYTASK。此任务使用SQL 访问指导。
第二个PL/SQL 块设置了MYTASK任务的SQL 访问指导参数。在该示例中您将
ANALYSIS_SCOPE设置为ALL,表示将为索引、实体化视图和分区生成建议案。然后,
将MODE设置为COMPREHENSIVE,以包括与将来任务关联的SQL优化集中的所有SQL
语句。
第三个PL/SQL 块将一个工作量与MYTASK任务关联起来。此处使用了一个现有的SQL
优化集MYSTS。现在,可以执行优化任务了。此任务执行完成后,可以生成对应的建议
案脚本,如幻灯片中第三个示例所示。
- 小结
• 实施新的分区方法
• 采用数据压缩
• 使用Enterprise Manager 创建SQL 访问指导分析会话
• 使用PL/SQL 创建SQL 访问指导分析会话
• 设置SQL 访问指导分析以获取分区建议案















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









