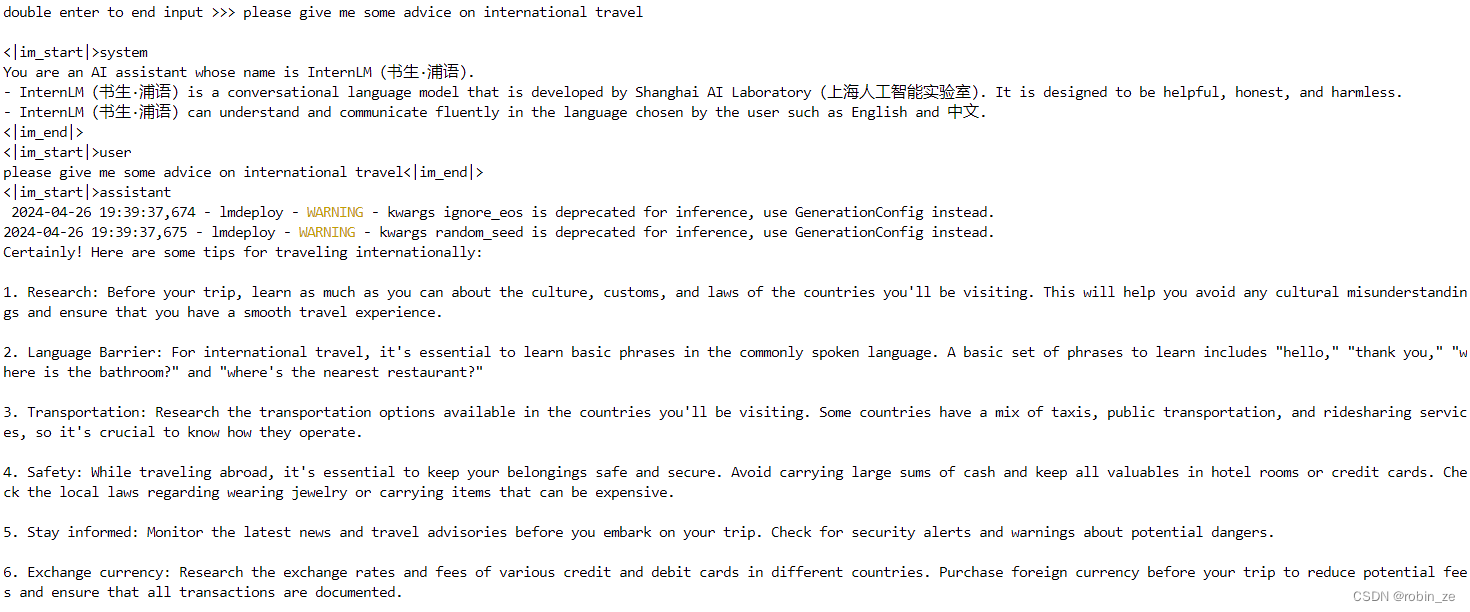
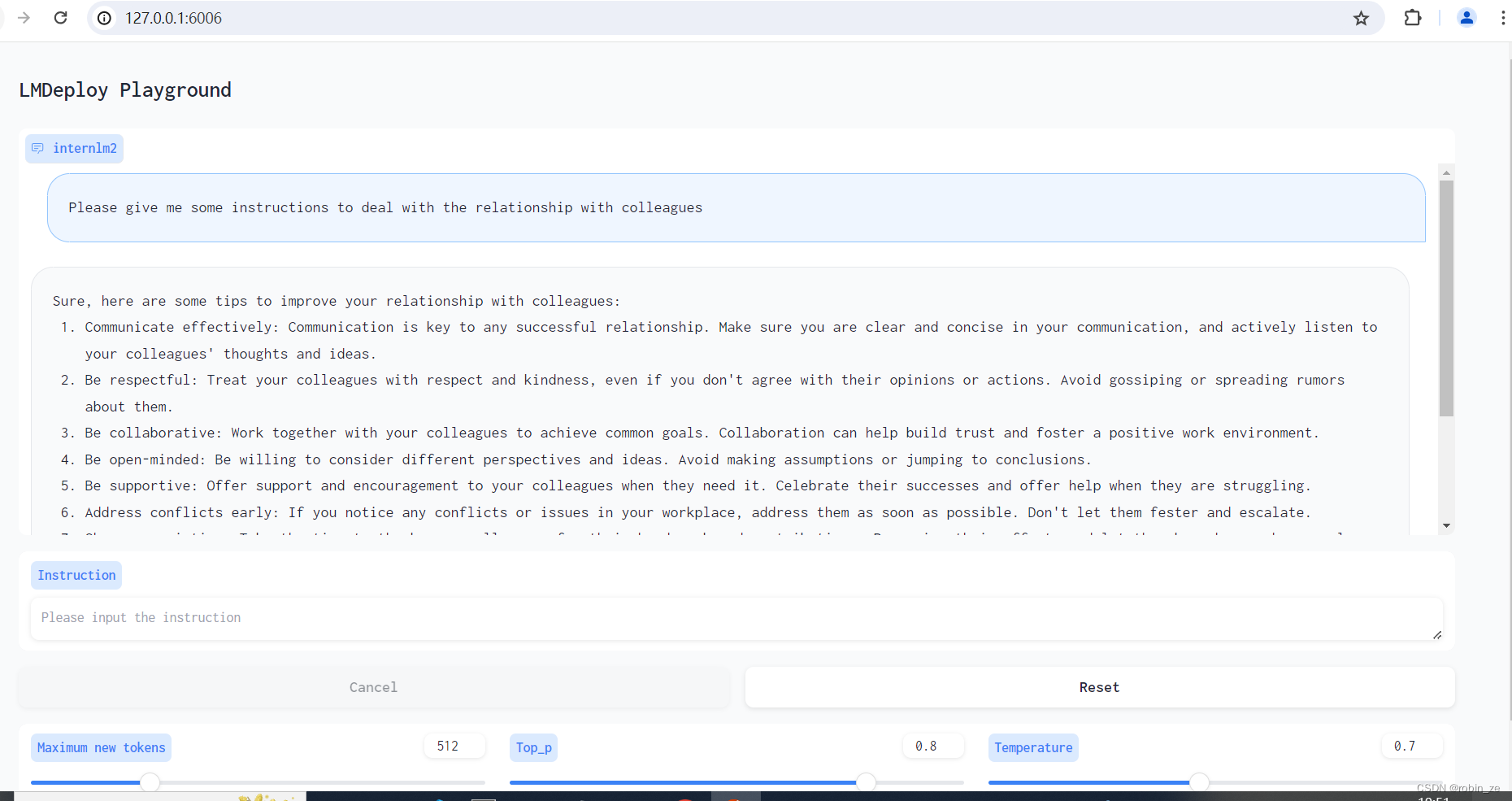
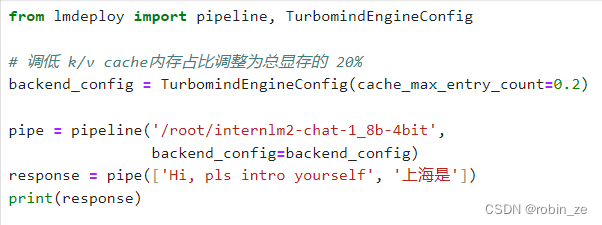
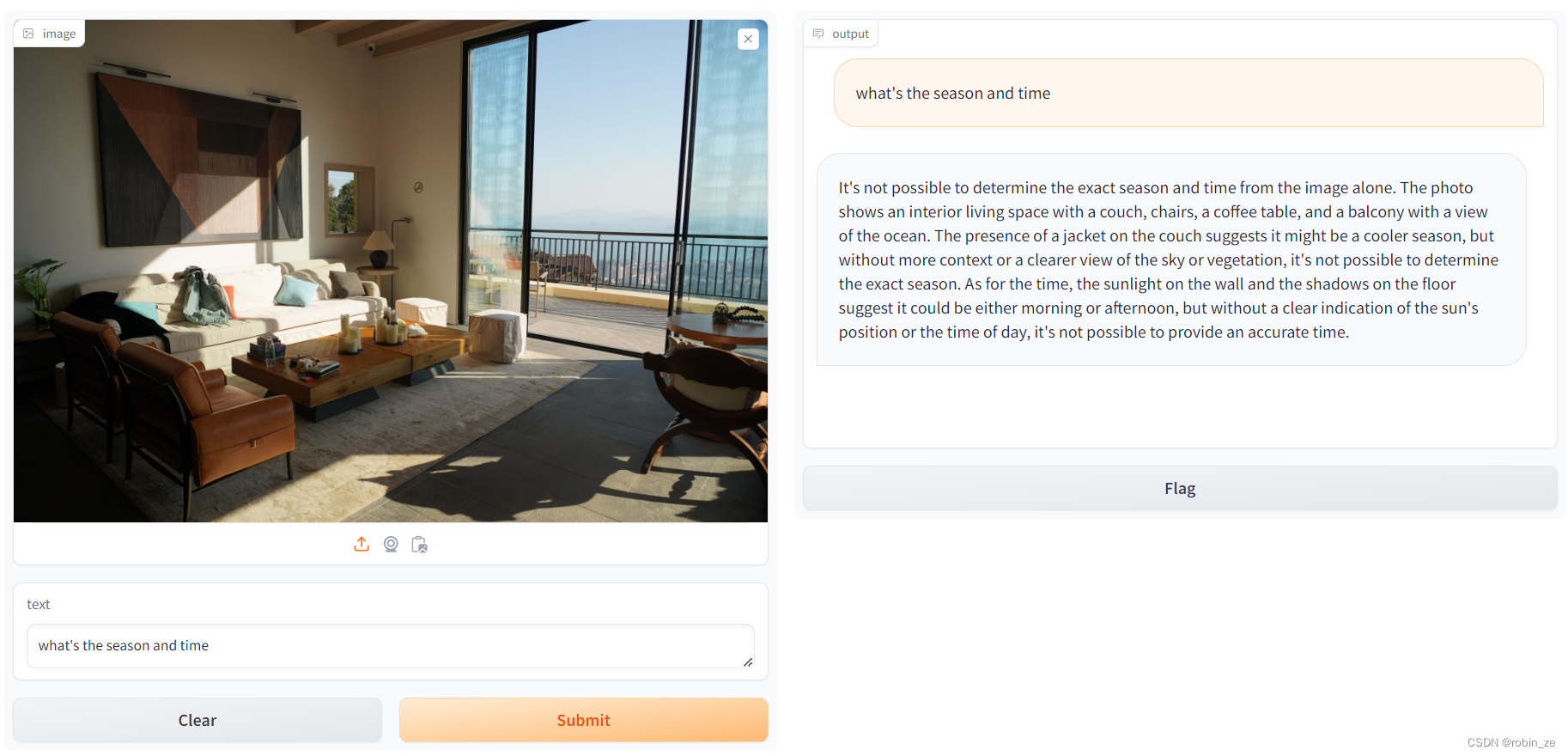
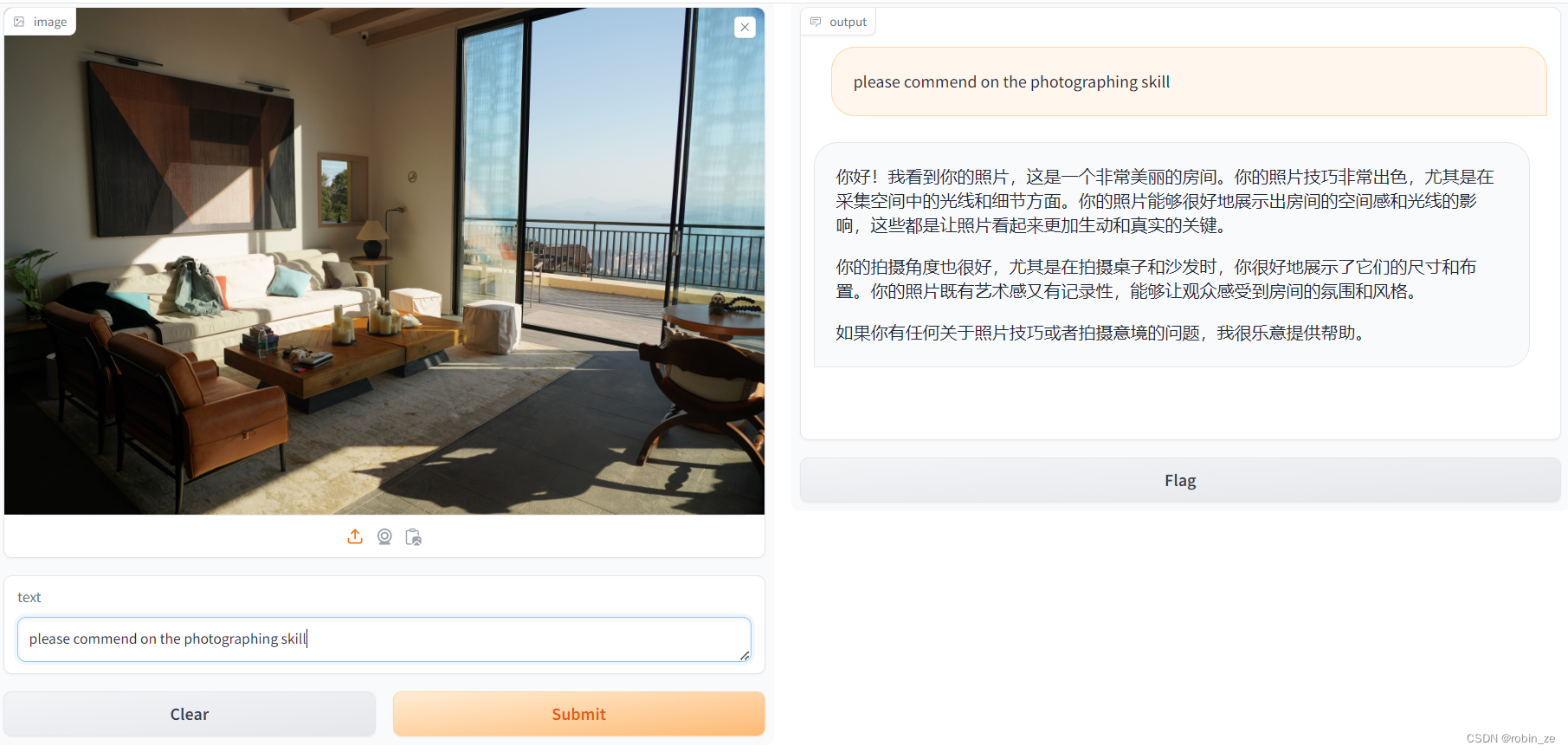
使用LMDeploy部署InternLM2-Chat-1.8B及其4 bit量化模型 与InternLM2-Chat-1.8B模型的对话过程 KV Cache最大占用比例为0.4,W4A16量化,命令行对话 KV Cache最大占用比例0.4,W4A16量化,Gradio Web端对话 量化模型的python代码集成 视觉多模态大模型LlaVA Gradio Demo


























 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






