







原文链接
文档概述
本文档在前面章节简单的介绍了React和其相关的一系列技术,最后章节介绍了React+Dva开发的整套过程和基本原理,也就是将一系列框架整合的结果。
文档结构
本文档划分为以下章节,前面几个章节是知识储备,最后章节是项目实践
- React
- Flux
- Redux
- React-Router
- Roadhog
- Ant Design
- DVA
- 项目实践
约束定语
本文中蓝色字体为超链接
本文中红色字体为特别注意内容
React
React是近期非常火热的一个前端开发框架,当然也有很多人认为它不是一个框架,因为它仅仅是作为MVC模式中的V层用来构建UI。在整个Web应用的MVC架构中,你可以将React看作为视图层,并且是一个高效的视图。React提供了和以往不一样的方式来看待视图,它以组件开发为基础。 对React应用而言,你需要分割你的页面,使其成为一个个的组件。也就是说,你的 应用是由这些组件组合而成的。你可以通过分割组件的方式去开发复杂的页面或某个功能区块,并且组件是可以 被复用的。这个过程大概类似于用乐高积木去瓶装不同的物体。我们称这种编程方式称为组件驱动开发。作为Facebook推出的一个JS库,React除了技术本身,人们更看重它的其实是它那种独特的开发思想,并在此基础上衍生出了一些列相关技术。React 通过对虚拟 DOM 中的微操作来实对现实际 DOM 的局部更新,提高性能。其组件的模块化开发提高了代码的可维护性,单向数据流的特点,让每个模块根据数据量自动更新。
JSX语法
JSX其实本质上是一种新的语言,只不过它设计成JavaScript一种扩展,所以,其语法绝大部分都和JavaScript一样。而同时它搭配一个JSX Transform的工具可以将JSX编译为原生的JavaScript。那么这样做好处是什么呢?当然了,首要任务就是让你写代码方便点,否则想想每次都要 React.createElement 也是醉了!其次呢,另一个好处就是它可以让你书写ES6之类的语法,就和CoffeeScript是一个道理,最终它会翻译到浏览器兼容的语法。
虚拟DOM
在传统的 Web 应用中,我们往往会把数据的变化实时地更新到用户界面中,于是每次数据的微小变动都会引起 DOM 树的重新渲染。如果当前 DOM 结构较为复杂,频繁的操作很可能会引发性能问题。React 为了解决这个问题,引入了虚拟 DOM 技术
虚拟 DOM 是一个 JavaScript 的树形结构,包含了 React 元素和模块。组件的 DOM 结构就是映射到对应的虚拟 DOM 上,React 通过渲染虚拟 DOM 到浏览器,使得用户界面得以显示。与此同时,React 在虚拟的 DOM 上实现了一个 diff 算法,当要更新组件的时候,会通过 diff 寻找到要变更的 DOM 节点,再把这个修改更新到浏览器实际的 DOM 节点上,所以在 React 中,当页面发生变化时实际上不是真的渲染整个 DOM 树。
组件概念
虚拟DOM不仅带来了简单的UI开发逻辑,同时也带来了组件化开发的思想,所谓组件,即封装起来的具有独立功能的UI部 件。React推荐以组件的方式去重新思考UI构成,将UI上每一个功能相对独立的模块定义成组件,然后将小的组件通过组合或者嵌套的方式构成大的组件, 最终完成整体UI的构建。
如果说MVC的思想让你做到视图-数据-控制器的分离,那么组件化的思考方式则是带来了UI功能模块之间的分离。对于MVC开发模式来说,开发者将三者定义成不同的类,实现了表现,数据,控制的分离。开发者更多的是从技术的角度来对UI进行拆分,实现松耦合。对于React而言,则完全是一个新的思路,开发者从功能的角度出发,将UI分成不同的组件,每个组件都独立封装。
在React中,按照界面模块自然划分的方式来组织和编写的代码,整个UI是一个通过小组件构成的大组件,每个组件只关心自己部分的逻辑,彼此独立。
组件特性
- 可组合:一个组件易于和其它组件一起使用,或者嵌套在另一个组件内- 部。如果一个组件内部创建了另一个组件,那么说父组件拥有它创建的子组件,通过这个特性,一个复杂的UI可以拆分成多个简单的UI组件;
- 可重用:每个组件都具有独立功能,可以被使用在多个UI场景;
- 可维护:每个小的组件仅仅包含自身的逻辑,更容易被理解和维护;
- 可测试:每个组件都是独立的,所以方便测试。
数据流props、state
在React中,数据流向是单向的从父节点传递到子节点,因而组件是简单且易于把握的,他们只需从父节点获取props渲染即可。如果顶层组件的某个prop改变了,React会递归地向下遍历整棵组建树,重新渲染所有使用这个属性的组件。 React组件内部还具有自己的状态,这些状态只能在组件内修改。React组件本身很简单,你可以把他们看成是一个函数,他接受props和state作为参数,返回一个虚拟的DOM表现。简单的来讲,react利用props形成单向的数据流,利用state更新界面。
- 数据流与props
React中的数据流是单向的,只会从父组件传递到子组件。属性props(properties)是父子组件间进行状态传递的接口,React会向下遍历整个组件树,并重新渲染使用这个属性的组件。 -
组件内部状态state
props可以理解为父组件与子组件间的状态传递,而React的组件都有自己的状态,这个内部状态使用state表示。state是组建的属性,主要用来存储组件自身需要的数据。它是可以改变的,它的每次改变都会引起组件的更新,这也是ReactJS中的关键点之一。每次数据的更新都是通过修改state属性的值,然后ReactJS内部会监听state属性的变化,一旦发生变化,就会主动出发组件的render方法来更新DOM结构。简单来讲:用户界面随着state的变化而变化。哪些组件应该有state?
大部分组件的工作应该是从props里取数据并渲染出来,但有时需要对用户输入、服务器请求或者时间变化等作出响应,这时才需要state。组件应该尽可能的无状态化,这样能隔离state,把它放到最合理的地方(Redux做的就是这个事情?),也能减少冗余并易于解释程序运作过程。
常用的模式就是创建多个只负责渲染数据的无状态(stateless)组件,在他们的上层创建一个有状态(stateful)组件并把它的状态通过props传给子级。有状态的组件封装了所有的用户交互逻辑,而这些无状态组件只负责声明式地渲染数。
哪些应该作为state?
state应该包括那些可能被组件的事件处理器改变并触发用户界面更新的数据.这中数据一般很小且能被JSON序列化。当创建一个状态化的组件的时候,应该保持数据的精简,然后存入this.state.在render()中在根据state来计算需要的其他数据.因为如果在state里添加冗余数据或计算所得数据,经常需要手动保持数据同步。
那些不应该作为state?
this.state应该仅包括能表示用户界面状态所需要的最少数据,因此不应该包括: 计算所得数据; React组件:在render()里使用props和state来创建它;
基于props的重复数据:尽可能保持用props来做作为唯一的数据来源,把props保存到state中的有效的场景是需要知道它以前的值得时候,因为未来的props可能会变化。
组件创建
React提供3种方法创建组件,具体的3种方式:
1) 函数方式:通过定义函数创建无状态组件
2) ES6方式:通过extends React.Component创建组件
3) ES5原生方式:通过extend React.createClass定义的组件
无状态组件
创建无状态组件形式是从React 0.14版本开始出现的。它是为了创建纯展示组件,这种组件只负责根据传入的props来展示,不涉及到要改变state状态的操作。在大部分React代码中,大多数组件被写成无状态的组件,通过简单组合可以构建成其他的组件等;这种通过多个简单然后合并成一个大应用的设计模式被提倡。
以上代码就创建一个名为QaQuestion的无状态组件,该组件接收一个props参数,仅仅包含一个div无状态组件的创建形式使代码的可读性更好,并且减少了大量冗余的代码,大大的增强了编写一个组件的便利,除此之外无状态组件还有以下几个显著的特点:
- 组件不会被实例化,整体渲染性能得到提升
由于是无状态组件,所以无状态组件就不会在有组件实例化的过程,无实例化过程也就不需要分配多余的内存,从而性能得到一定的提升。 - 组件不能访问this对象
无状态组件由于没有实例化过程,所以无法访问组件this中的对象,例如:this.ref、this.state等均不能访问。若想访问就不能使用这种形式来创建组件 - 组件无法访问生命周期的方法
因为无状态组件是不需要组件生命周期管理和状态管理,所以底层实现这种形式的组件时是不会实现组件的生命周期方法。所以无状态组件是不能参与组件的各个生命周期管理的。 - 无状态组件只能访问输入的props,同样的props会得到同样的渲染结果
无状态组件被鼓励在大型项目中尽可能以简单的写法来分割原本庞大的组件,未来React也会这种面向无状态组件在譬如无意义的检查和内存分配领域进行一系列优化,所以只要有可能,尽量使用无状态组件。
原生React.createClass方式创建
React.createClass是react刚开始推荐的创建组件的方式,现在已经不推荐使用:
通过React.createClass方式和extends React.Component方式创建的组件都是有状态组件。但是随着React的发展,通过React.createClass这创建组件的这种方式也暴露出一些问题,并且在将来的React版本中,将不在支持这种方式创建组件,因此这种方式并不推荐使用。
extends React.Components方式创建
React.Component是以ES6的形式来创建react的组件的,是React目前极为推荐的创建有状态组件的方式,最终会取代React.createClass形式。
React.createClass创建的组件,其状态state是通过getInitialState方法来配置组件相关的状态;React.Component创建的组件,其状态state是在constructor中像初始化组件属性一样声明的。
组件生命周期
在组件的整个生命周期中,随着该组件的props或者state发生改变,它的DOM表现也将有相应的变化,一个组件就是一个状态机:对于特定的输入,它总会返回一致的输出。 React为每个组件提供了生命周期钩子函数去响应不同的时刻,组件的生命周期分为三个部分:(1)实例化;(2)存在期;(3)销毁&清理期。

getInitialState: 初始化组件的state的值,其返回值会赋值给组件的this.state属性。对于组件的每个实例来说,这个方法的调用次数有且只有一次。与getDefaultProps方法不同的是,每次实例创建时该方法都会被调用一次。
componentWillMount :此方法会在完成首次渲染之前被调用。这也是在render方法调用前可以修改组件state的最后一次机会。
render :生成页面需要的虚拟DOM结构,用来表示组件的输出。Render需要满足:(1)只能通过this.props和this.state访问数据;
(2)可以返回null、false或者任何React组件;
(3)只能出现一个顶级组件;
(4)必需纯净,意味着不能改变组件的状态或者修改DOM的输出。
componentDidMount: 该方法发生在render方法成功调用并且真实的DOM已经被渲染之后,在该函数内部可以通过this.getDOMNode()来获取当前组件的节点。然后就可以像Web开发中的那样操作里面的DOM元素了。
componentWillReceiveProps :在任意时刻,组件的props都可以通过父辈组件来更改。当组件接收到新的props(这里不同于state)时,会触发该函数,我们同时也获得更改props对象及更新state的机会。
shouldComponentUpdate: 该方法用来拦截新的props和state,然后开发者可以根据自己设定逻辑,做出要不要更新render的决定,让它更快。
componentWillUpdate: 与componentWillMount方法类似,组件上会接收到新的props或者state渲染之前,调用该方法。但是不可以在该方法中更新state和props。
componentDidUpdate :与componentDidMount类似,更新已经渲染好的DOM。
componentWillUnmount:该方法会在组件被移出之前调被调用。在componentDidMount方法中添加的所有任务都需要在该方法中撤销,比如说创建的定时器或者添加的事件监听等。
Flux
Flux 是一种应用架构,或者说是一种思想或模式而不是一个正式的框架,它跟 React 本身没什么关系,它可以用在 React 上,也可以用在别的框架上。Flux 在 React 中主要用来统一管理引起 state 变化的情况。Flux 维护着一个或者多个叫做 Store 的变量,就像 MVC 里面的 Model,里面存放着应用用到的所有数据,当一个事件触发时 ,Flux 对事件进行处理,对 Store 进行更新,当 Store 发生变化时,通常是由应用的根组件(也叫 controller view)去获取最新的 store,然后更新 state,之后利用 React 单向数据流的特点一层层将新的 state 向下传递实现 view 的更新。这里的 controller view 可以有多个也可以不是根组件,但是这样数据流维护起来就比较麻烦。
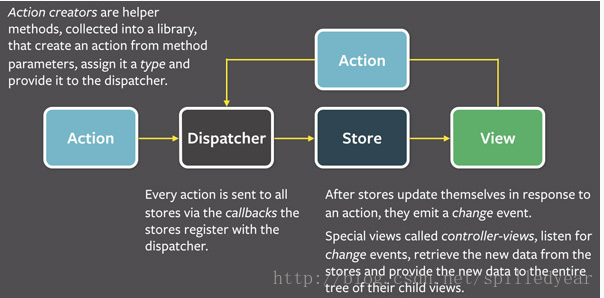
Dispatcher就像一个中心枢纽所有数据的流动都要通过这里。Action来源于用户与views的交互行为,Action触发Dispatcher。Dipatcher分发这个事件给对应的Store(通过之前注册的回调函数callback)。Store在修改State后触发一个”change”事件通知controller-views数据发生变化了。controller-views监听这些”change”事件并且从stores暴露的函数中获取(新)数据,然后调用自己的setState()方法,rerender自己和它的子组件。
- Dispatcher
事Dispatcher是Flux应用中管理所有数据流的中心枢纽。它本质上就是一些Store回调函数的注册器,它本身没有其他逻辑 -
只是提供了把Action分发给Store的机制。dispatcher根据action
type调用对应的回调函数。每一个Store都在Dispatcher注册(AppDispatcher.register)并提供回调函数。随着应用的发展,Dispatcher会变得越来越重要。例如Dispatcher可以用来管理Stores之间的依赖关系,通过特定的顺序来调用注册了的回调函数就可以办到。Stores可以等到其他Stores完成更新再进行自己的更新操作。 - Store
Store负责封装应用的业务逻辑跟数据的交互,包含应用所有的数据,是应用中唯一的数据发生变更的地方。Store中没有赋值接口,所有数据变更都是由dispatcher发送到store,新的数据随着Store触发的change事件传回view。Store对外只暴露getter,不允许提供setter,禁止在任何地方直接操作Store。 - Views和Controller-Views React在View(MVC)层提供了可组合的可自由重新渲染的Views,
在嵌套的views结构顶部, 一个特别的view监听着stores广播的事件,
我们管这种view叫controller-view。在controller-view中我们完成这样的操作::从stores中获取数据并且传递这些数据的到它的子代中.
我们总有一个这样的controller-view控制页面的某一部分。
当controller-view接受到store广播的事件,它首先从store的公共getter方法中获取它需要的新数据,然后调起setState()或者forceUpdate()方法,那么它和它所有子代的render()方法都会运行。
我们常常把整个store的state放在一个对象里面传递到子代中,让子代选择自己需要的东西。这样除了可以在层级结构顶层保持控制(controller)行为因此尽可能保证子代views的单一功能外,还可以减少我们需要管理的属性(props)的数目。
有时候我们可能需要在层级结构的某一层建立另外的一些controller-view使一些组件能简单些。这样可以帮助我们更好地去封装层级上的与特定的数据有关联的一些模块。请注意,在不是顶层建立一个controller-view会破坏单项数据流这个原则,因为有可能会存在数据入口的冲突。在做这样的决定之前,我们可以衡量一下得到一个简单一点的组件和多重数据流多个数据更新入口孰轻孰重。多重数据流会有一些副作用:
React的render()方法会因为不同的controller-view的数据更新而多次被处罚, 会增加debug的难度。
Redux
Redux 的作用跟 Flux 是一样的,它可以看作是 Flux 的一种实现,但是又有点不同。
-
Redux 只有一个 store 。Flux 里面会有多个 store 存储应用数据,并在 store 里面执行更新逻辑,当 store变化的时候再通知 controller-view 更新自己的数据,Redux 将各个 store 整合成一个完整的 store,并且可以根据这个 store 推导出应用完整的 state。同时 Redux 中更新的逻辑也不在 store 中执行而是放在reducer 中。
-
没有 Dispatcher。 Redux 中没有 Dispatcher 的概念,它使用 reducer 来进行事件的处理,reducer 是一个纯函数,这个函数被表述为 (previousState, action) => newState ,它根据应用的状态和当前的 action 推导出新的 state。Redux 中有多个 reducer,每个 reducer 负责维护应用整体 state 树中的某一部分,多个 reducer 可以通过 combineReducers 方法合成一个根reducer,这个根reducer负责维护完整的 state,当一个 action 被发出,store 会调用 dispatch 方法向某个特定的 reducer 传递该 action,reducer 收到 action 之后执行对应的更新逻辑然后返回一个新的 state,state 的更新最终会传递到根reducer处,返回一个全新的完整的 state,然后传递给 view。
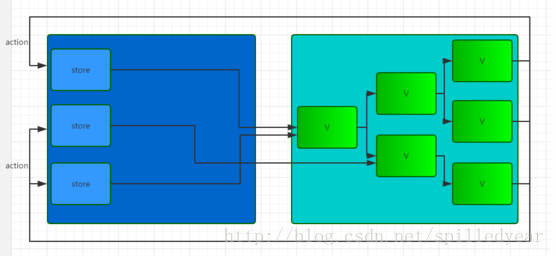
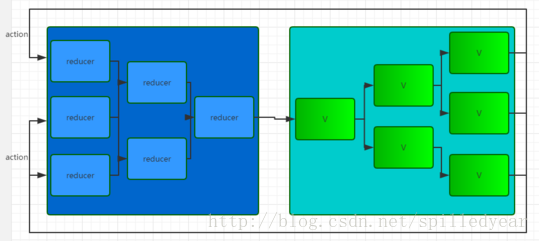
Redux 和 Flux 之间最大的区别就是对 store/reducer 的抽象,Flux 中 store 是各自为战的,每个 store 只对对应的 controller-view 负责,每次更新都只通知对应的 controller-view;而 Redux 中各子 reducer 都是由根reducer统一管理的,每个子reducer的变化都要经过根reducer的整合。用图表示的话可以像这样:
Flux 中的 store :
Redux 中的 store(或者叫 reducer)
React-Router
React-Router 是一个为 React 设计的强大的路由库。可以帮助我们快速的实现路由功能,包括 URL 和 React components 之间的同步映射关系。
-
前端路由 前端的路由和后端的路由在实现技术上不一样,但是原理都是一样的。在 HTML5 的 history API出现之前,前端的路由都是通过 hash 来实现的,hash 能兼容低版本的浏览器,它的 URI 规则中需要带上 #。例如:http://localhost:8000/#/login Web 服务并不会解析 hash,也就是说 # 后的内容 Web服务都会自动忽略,但是 JavaScript 是可以通过 window.location.hash读取到的,读取到路径加以解析之后就可以响应不同路径的逻辑处理。 history 是 HTML5 才有的新 API,可以用来操作浏览器的session history (会话历史)。基于 history 来实现的路由可以不需要#,例如localhost:8080/login
-
前端路由
先看一段配置代码Router组件本身只是一个容器,真正的路由要通过Route组件定义,path对应的是访问路径,component是该路径对应的组件。例如:在浏览器中访问/qaBasic的时候,会加载qaBasic这个组件。当然这里还有组件嵌套,也就是在一个Route里面包含另一个子Route,表明在访问子组件的时候,会先加载父组件,然后再父组件里面加载子组件。
Roadhog
roadhog 是一个 cli 工具,提供 server、 build 和 test 三个命令,分别用于本地调试和构建,并且提供了特别易用的 mock 功能。命令行体验和 create-react-app 一致,配置略有不同,比如默认开启 css modules,然后还提供了 JSON 格式的配置方式。
roadhog配置详解
Ant Design
Ant design是蚂蚁金服出品的一款前端UI librar,提供了丰富的React组件。
ant design组件库
DVA
dva 是基于现有应用架构 (redux + react-router + redux-saga 等)的一层轻量封装,没有引入任何新概念,全部代码不到 100 行。( Inspired by elm and choo. )dva 是 框架,不是 library,类似 emberjs,会很明确地告诉你每个部件应该怎么写,这对于团队而言,会更可控。另外,除了 react 和 react-dom 是 peerDependencies 以外,dva 封装了所有其他依赖。dva 实现上尽量不创建新语法,而是用依赖库本身的语法,比如 router 的定义还是用 react-router 的 JSX 语法的方式。
项目实践
本章节介绍windows系统下react+dva构建项目实现过程,将前面介绍的知识点进行整合,主要包括:项目的搭建、基本配置、目录规划、路由配置、前端通过调用后台restful接口获取数据、react组件间的数据传递等。
创建项目
这里通过dva来快速新建一个项目,当然在次之前需要提前准备好node环境
1) 安装node
- 下载:https://nodejs.org/en/download/
- 安装:
- 检测:命令行下输入 node -v
2) 安装dva-cli
- 安装: npm install dva-cli -g
- 检测:dva-v
3) 利用dva创建项目
- dva new PORTAL //会创建 PORTAL 目录,并在该目录下生成一些基本配置文件
4) 启动应用
- 在PORTAL目录下,执行命令 npm start
基本配置
在项目创建成功之后,会在项目下看到一些基础配置文件,这也是一点通过dva来构建项目的方便之处。一般可以看到以下几个配置文件:.eslintrc、.editorconfig、.roadhogrc、.roadhogrc.mock.js、package.json,这里简单了解两个配置文件:roadhogrc和package.json。基于npm模式开发的时候,和以前那样纯粹的写js代码不同,因为这是面向模块化的前端开发。有关于前端模块化开发,这里提供一个介绍文档。
基于npm模式的前端开发
package.json配置文件非常像maven中的pom.xml文件,虽然它还有其它用途,但在很多情况下,都有着管理模块的的作用,例如:
将项目中需要用到的模块添加进package.json文件,然后执行 npm install 就可以将这些模块从npm库下载到本地。
.roadhogrc配置文件里面的内容是一个json对象,是对roadhog模块的配置
以上是代码中,entry 指定了整个项目的入口文件;proxy设置了代理,上面的意思是会配置所有以api开头的请求
目录规划
前端应用越来越复杂,也越来越规范,在前后端分离的系统中,前端实际上已经控制了MVC模式中的Controller和View层,而后端仅仅是作为M层提供数据。因此,在前端应用开发过程中,特别是基于React这套前端框架的应用中,目录规划显得十分重要。在利用dva开发前端构建react的应用中,主要划分为以下几个目录:components、container、models、routes、services、utils、styles 以下是项目目录截图:

- components:最基础的组件。这里面存放的只是最基本的UI组件,这些组件接收外部传过来的参数(数据),并将这些数据渲染的到界面。根据传入的参数的不同,界面渲染也不同。
- container:contatiner负责将数据的组件进行连接,相当于将compontent组件和store里面的数据进行包装,生成一个新的有数据的组件。然后,在router.js配置文件中引用container中的组件。
routers:router目录其实和container目录基本一样,只是在利用dva开发的应用中叫router,在不是利用dva开发的应用中叫container而已,两者有一个即可。 - models:model是dva中的一个重要概念,也可以看作是前端中的数据层。在我的理解里,dva将model以
namespace作为唯一标识进行区分,然后将所有model的数据存储到redux
中的store里面。在引用的时候,通过各个model的namespace进行引用。Model,是一个处理数据的地方,在model里面调用service层获取数据。
services:services负责向后台请求数据,在services里调用后台提供的api获取数据。 - utils:工具类目录,比如常见的后台接口请求工具类。
- styles:存放css或less样式文件。
- constants.js:在里面定义一些通用的常量。
- router.js:配置整个应用的路由。
- index.js:整个应用的入口文件,dva和其它框架稍有不同。
路由配置
路由配置主要是为了控制在浏览器上界面的跳转。这里引用的是react-router这个框架。在router.js里面对整个应用的路由惊醒配置。主要注意的几点就是:在router.js里面引用的一般都是container组件,通过配置,将路径和对应的要在浏览器上加载的组件对应起来,再通过window.location.hash或者是‘routerRedux’这个组件进行路由之间的转跳。
以上便是一个最基础的路由配置,path对应的是浏览器上地址栏的路径,component是访问该路径时将会在界面上加载的组件。还有这里用到了router嵌套,即在一个router里面嵌套另外一个router,这种情况下,在访问子router对应的路径时,会先加载父router对应的组件,然后再父组件里面加载子router对应的组件。
前后端交互
在前后端分离的项目中,前后端的数据交互式通过在前端应用中调用后端提供的restful接口获取数据。在dva构建的前端应用中,标准的前后端交互大概是这个流程:
1) 新建一个model
model是dva中非常重要的一个概念,dva中的model实际上类似于封装了redux里面的action和reducer,并给每个model提供一个namespace交于strore管理。这样,在外部引用的时候,可以直接获取到model对应的namespace,然后根据namespace获取数据。
新建一个model主要注意以下几个细节:
-
model需要在 index.js 里面声明
app.model(require(‘./models/qa)); -
model里面需要有namesapce这个属性值
- 外部使用model里面的方法值时需要通过namespace
namespace/方法名
以上新建了一个namespace 为 ‘qa’的model,并在effects里面添加了一个fetchGuide方法和在reducers里面添加了一个guideSave方法。
Subscriptions里面的内容表示在项目启动加载model的时候就会执行,dispatch({ type: ‘fetchGuide’,payload:{}});就相当于在项目启动的时候,就会先调用一次effects里面的fetchGuide方法;
effects里面的put 方法,会调用reducers 里面的方法,根据方法中参数type的值找到reducers中的那个方法并执行。这个过程其原理就是redux中 dispatch 一个action的过程。
reducers里面的 方法负责改变store中的值,其实也只有通过这种方式才能改变store中的值。
2) 新建一个service
在上面的model中,可以发现有这样代码:
import * as service from ‘../services/qa’;
const {rows} = yield call(service.fetchGuide, {guidelineId});
其中yeild 是ES6中的关键字,表示以同步的写法来实现异步操作。可以发现,这里引入了一个service目录下的qa.js文件,并调用了该文件中的fetchGuide方法
可以看到,这个文件比较简单:
首先从utils目录学引入了一个工具类,该工具类主要用来请求后端数据。就是
一个工具类而已,传入两个参数,一个是后台提供的restful API地址,一个是参
数。然后得到后台返回的数据,这就是这个工具类的主要用途。然后再service的
fetchGuide方法里面,传入参数进行调用,并最终返回后台数据。也就是说,在
model里面调用service,可以获取后台的数据,然后保存到store中。
3) 配置代理
这一部分的内容我其实并不太清楚它的前因后果。目前知道的做法是这样的,在我们的.roadhogrc配置文件中,添加以下内容:
以上内容表示在前端请求以‘api’为前缀的api的时候,会使用代理:怎么说呢,就相当于在请求/api/qa/guide 这个路径的时候,最后实际上请求的路径会是http://localhost:8080/api/ qa/guide,这样一方面方便了我们配置,在改变ip的时候只需要在配置文件里面改革ip就可以了,很方便。但不是很了解这个到底是怎么一个流程?还有,使用这种方式会自动解决js跨域的问题吗?因为在一般情况下,js跨域问题是需要去解决的,那这种方式呢?还不是很懂。
因此,dva中的前后端交互主要就是以下流程:

组件数据流
前一小节讲解了在dva中的前后端交互流程,在获取到数据之后,接下来面临的一个问题就是怎么将数据传递到组件上了。
我们知道,react是自上而下的单向数据流,也就是从父组件传递到子组件,而不能从子组件传递到父组件。那么当我们需要将子组件的数据传递到父组件时,该怎么办呢?一种方法是使用回调函数,当发生某个操作时执行回调函数改变state然后重新渲染界面。还有一种方法是使用第三方框架。Dva中就包含了一个这样的框架:redux
在redux中,通过store管理所有的state,dva只是将几个框架进行整合,根本的东西其实根本没有一丝改变,所以dva中model里面的那些数据其实都是存储在store里面的。Model下的namespace,就相当于是store下的一个个属性。理解清楚了这个,那么给组件传递数据的流程也就清楚了。
1) 在container组件中,通过redux中的connect获取store里面的数据
这就是redux那一套的标准写法。首先就是在container组件里面引用components组件,然后将store下的数据传递到components组件上
以上就是一个container组件,当然,上面的写法其实有点多余:const qaQuestion 这里其实生成的还是一个components组件,然后将QaQuestion 这个components组件包装到qaQuestion 组件里面,这里有点多余。但是不影响我们分析问题。Connect是redux提供的一个函数,作用是将数据和组件连接起来,也就是所谓的向components组件传递数据。在这里我们传递了一个qa参数,其实这是一个namespace名为qa的model,当然,数据最终是存储在store下面。也就是说,我们通过connect这个函数,可以直接拿到store里面的数据(model也是在store里面);然后再qaQuestion这个组件上,接收一个参数,也就是connect高阶函数中取出的那个参数,然后我们再将 qa下面的questionList值传递给了QaQuestion组件,参数名为 props,这样我们就可以在QaQuestion组件中直接使用props(它的值就是qa. questionList)这个参数了。
2) 在components组件中使用传递过来的数据
从上可以看出,已经使用到了container里面传过来的参数。
Dva启动文件
默认情况是index.js,当然这个可以在.roadhogrc配置文件中进行配置。以下是index.js内容
在dva中,项目启动主要分为以下过程:第一步是实例化一个dva对象;第二步是添加需要使用到的插件;第三步是添加需要使用到的model;第四部是添加路由配置;第五步是调用dva中的start方法,该方法接收一个参数,这个参数是html文件中某个元素的id,作为整个应用的挂载点。
hml文件默认是public目录下的index.html文件,以下是html文件的内容,非常简单,在body标签下面只有一个div标签,这个div就是作为整个应用的挂载点。其中还有个

















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









