









BOM(Byte Order Mark)
在分析unicode之前,先把bom(byte order mark)说一下。
bom是unicode字符顺序的标识符号,一般以魔数(magic code)的形式出现在以Unicode字符编码的文件的开始的头部,作为该文件的编码标识。
来举个很简单的例子,在windows下新建一个文本文件,并另存为utf8的文件格式:

该文件里面没有任何内容,我们再用Hex Edit来查看该文件的二进制内容:
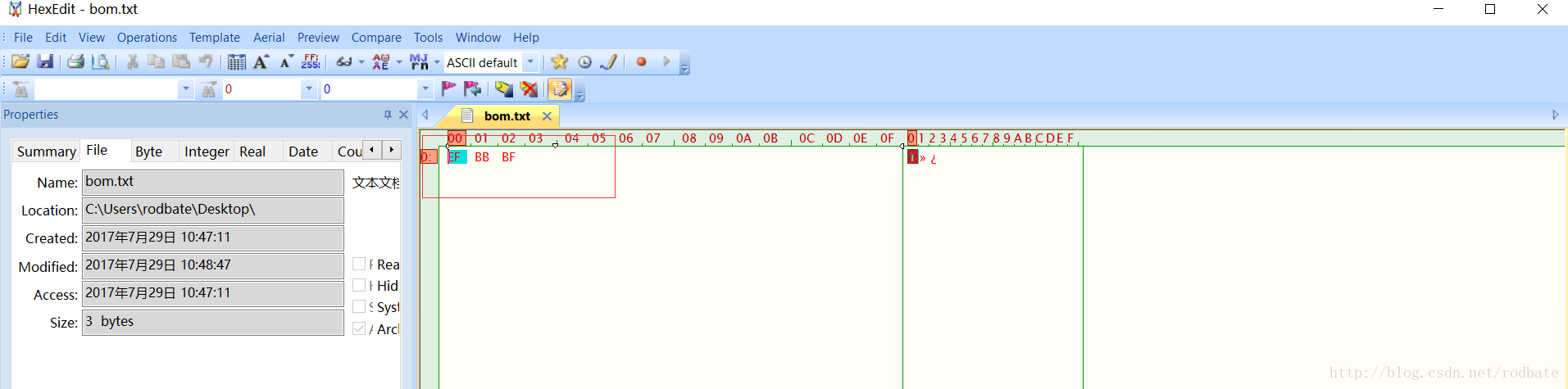
0XEFBBBF就是这个文件的bom, 这也就是标识该文件是以utf8为编码格式的,下面来看看字符编码与其bom的对应关系
| 字符编码 | Bom (十六进制) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) 大端 | FE FF |
| UTF-16 (LE) 小端 | FF FE |
| UTF-32 (BE) 大端 | 00 00 FE FF |
| UTF-32 (LE) 小端 | FF FE 00 00 |
| GB-18030 | 84 31 95 33 |
上面只是列举了一些常用的字符编码,上面其它的bom验证也可以像上面的utf8 bom一样验证。
UTF-8编码剖析
Unicode编码以code point 来标识每一个字符, code point 的范围是
0x000000 – 0x10FFFF,也就是每一个字符的code point都落在这个范围,而utf8的一个字符可以用1-4字节来表示,可能有人会说这code point最大也就是0x10FFFF,为什么最大不是可以用三个字节表示呢?那是因为utf8有自己独特的表示格式,先来看看下面的对应关系:
| 字节数 | 字符code point位数 | 最小的code point | 最大的code point | 第一个字节 | 第二个字节 | 第三个字节 | 第四个字节 |
|---|---|---|---|---|---|---|---|
| 1 | 7 | U+0000 | U+007F | 0XXXXXXX | 无 | 无 | 无 |
| 2 | 11 | U+0080 | U+07FF | 110XXXXX | 10XXXXXX | 无 | 无 |
| 3 | 16 | U+0800 | U+FFFF | 1110XXXX | 10XXXXXX | 10XXXXXX | 无 |
| 4 | 21 | U+10000 | U+10FFFF | 11110XXX | 10XXXXXX | 10XXXXXX | 10XXXXXX |
看到上面的对应关系,应该可以看出点规律了吧,总结一下:
- 当某个字符的code point (cp简称)
U+0000 <= cp <= U+007F落在这个范围内,这时只需要一个字节来表示 0XXXXXXX,将该字符的code point (7位)填入X的位置,就可以得到该字符的utf8的编码后的格式了。我们以小写字母a举个例子,a的code point是01100001, 经过utf8编码后 01100001(0x61), 可以用hex edit验证一下

再用个稍微大点的code point 来验证下, 中文汉字 加 code point 为 0x52A0 二进制格式 0101 0010 1010 0000, 按照上表中的规则,该字符需要用三个字节来表示,按照填充规则 ,第一个字节 1110XXXX -> 11100101 , 第二个字节10XXXXXX -> 10001010 , 第三个字节10XXXXXX -> 10100000, 组合起来就是11100101 10001010 10100000 HEX-> 0xE58AA0, 用hex edit来验证一下

EF BB BF 是utf8的bom, 结果一致,可以自己试一试。
UTF-16编码剖析
utf-16编码的单元是两个字节,也就是16位。utf-16编码格式在程序内存里经常使用,因为它比较高效, java中Character 字符用的就是utf-16编码格式,在早期的时候,世界上所有的字符都可以用两个字节标识,也就是code point范围 U+0000 – U+FFFF,这样utf-16就可以很好的表示了,而且也不用像utf8那样按照固定的模板组合,可以直接用字符的code point表示,非常高效, 但是随着时间的推移,所有字符远远不能用两个字节的code point 表示了,那为了兼容code point 超过U+FFFF的字符 就出现字符代理对(Surrogate pair), utf16就是使用代理对来表示code point 范围在 U+10000 -> U+10FFFF之间的字符,当然也就的使用四个字节来表示该字符了。对于Surrogate pair 与code point 之间的对应关系算法,等会儿再说, 先来看下utf16对于code point 小与U+10000的字符表示,其实用的就是字符的code point表示,这里还区分了大小端的表示法。还是来看中文汉字 加 code point 为 0x52A0, 推测一下,如果用utf16大端存储,那就是0x52A0;
如果用utf16小端存储,那就是0xA052, 来用hex edit 验证下。
utf16 大端

utf 小端
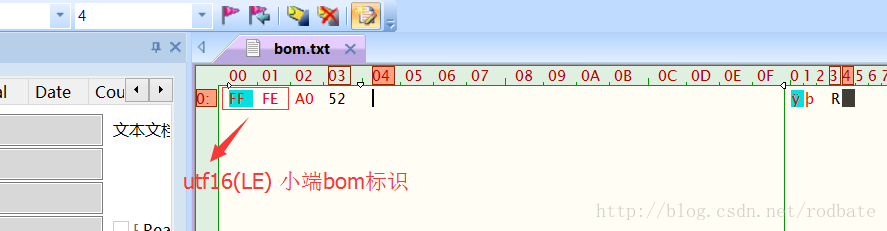
结果验证正确。
对于code point 大于U+FFFF是如何用Surrogate pair 表示的呢?下面来细说。
来看一个��U+10437 code point 超过U+FFFF的字符。Surrogate pair 分为high surrogate 和low surrogate ,总共四个字节。
high surrogate 的范围 0xD800 -> 0xDBFF, low surrogate 的范围 0xDC00 -> 0xDFFF
将code point 转化为surrogate pair 的算法步骤:
- 先将字符code point
0x10437减去基数0x10000, 得到0x437 二进制 0000000001 0000110111,这里注意 因为unicode 的最大code point 不超过U+10FFFF, 也就是code point 不会超过20个二进制位, 重点来了 - high surrogate 等于上面的结果的前10位 加上最小的high surrogate
0xD800得到0xD801 - low surrogate 等于上面的结果的前10位 加上最小的lowsurrogate
0xDC00得到0xDC37 - 组合起来就是
0xD801 DC37大端
用hex edit 来验证下

小端utf16 0x01D8 37DC

当然将utf16编码后的格式 反过来用code point 表示就是过程的逆向,可以根据 字符是否落在 high surrogate 的范围 0xD800 -> 0xDBFF, low surrogate 的范围 0xDC00 -> 0xDFFF 这个范围来判断该utf16字符是否是surrogate pair。然后再进行转化,这里就不再赘述了。java 中的Character类中这两种过程的都有
1. surrogate pair 转化为code point
public static int toCodePoint(char high, char low) {
// Optimized form of:
// return ((high - MIN_HIGH_SURROGATE) << 10)
// + (low - MIN_LOW_SURROGATE)
// + MIN_SUPPLEMENTARY_CODE_POINT;
return ((high << 10) + low) + (MIN_SUPPLEMENTARY_CODE_POINT
- (MIN_HIGH_SURROGATE << 10)
- MIN_LOW_SURROGATE);
}
2. code point 转化为 surrogate pair
public static char highSurrogate(int codePoint) {
return (char) ((codePoint >>> 10)
+ (MIN_HIGH_SURROGATE - (MIN_SUPPLEMENTARY_CODE_POINT >>> 10)));
}
public static char lowSurrogate(int codePoint) {
return (char) ((codePoint & 0x3ff) + MIN_LOW_SURROGATE);
}UTF-32编码剖析
utf-32用四个字节表示每一个字符,直接用字符的code point表示,非常高效,不需要任何的转化操作,但占用的存储空间却是很大的,会有空间的浪费。
比如说 小写字母a code point 是0x61 用utf32表示就是大端 -> 0x00 00 00 61 ; 小端 -> 0x61 00 00 00, 这样会造成存储空间的浪费,当然应用场景不同而已,当追求高效的转换而忽略存储空间的浪费这个问题,utf32编码格式是比较好的选择。而utf8的原则是尽可能的节省存储空间,牺牲转化的效率,各有各的好处。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









