







重建索引、索引长度、区分度
重建索引。SQL语句:REPAIR TABLE `table_name` QUICK。重建索引在常规的数据库维护操作中也经常使用。在数据库运行了较长时间后,索引都有损坏的可能,这时就需要重建。对数据重建索引可以起到提高检索效率。
判断数据结构是否适合创建索引:
SELECT channel_subordinate_type,count(*) AS cishu FROM sku_channel GROUP BY channel_subordinate_type ORDER BY cishu
1、索引是否创建,统计下索引的基数(也叫区分度)
select count(distinct col)/count(col) from table 得出百分百,越大索引越有效,反之即便创建索引也无用
==================== 根据sql'执行顺序优化,小表驱动大表
from 子句--执行顺序为从后往前、从右到左
表名(最后面的那个表名为驱动表,执行顺序为从后往前, 所以数据量较少的表尽量放后)
oracle 的解析器按照从右到左的顺序处理,FROM 子句中的表名,FROM 子句中写在最后的表(基础表 driving table)将被最先处理,即最后的表为驱动表,在FROM 子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3 个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指被其他表所引用的表
多表连接时,使用表的别名并把别名前缀于每个Column上。可以减少解析的时间并减少那些由Column 歧义引起的语法错误.
▼
▼
where子句--执行顺序为自下而上、从右到左
ORACLE 采用自下而上从右到左的顺序解析Where 子句,根据这个原理,表之间的连接必须写在其他Where 条件之前, 可以过滤掉最大数量记录的条件必须写在Where 子句的末尾。
▼
▼
group by--执行顺序从左往右分组
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉。即在GROUP BY前使用WHERE来过虑,而尽量避免GROUP BY后再HAVING过滤。
▼
▼
having 子句----很耗资源,尽量少用
避免使用HAVING 子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作.
如果能通过Where 子句在GROUP BY前限制记录的数目,那就能减少这方面的开销.
(非oracle 中)on、where、having 这三个都可以加条件的子句中,on 是最先执行,where 次之,having 最后,因为on 是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,
where 也应该比having 快点的,因为它过滤数据后才进行sum,在两个表联接时才用on 的,所以在一个表的时候,就剩下where 跟having比较了。
在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where 可以使用rushmore 技术,而having 就不能,在速度上后者要慢。
如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的,where 的作用时间是在计算之前就完成的,而having 就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。
在多表联接查询时,on 比where 更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where 进行过滤,然后再计算,计算完后再由having 进行过滤。
由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里。
▼
▼
select子句--少用*号,尽量取字段名称。
ORACLE 在解析的过程中, 会将依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 使用列名意味着将减少消耗时间。
sql 语句用大写的;因为 oracle 总是先解析 sql 语句,把小写的字母转换成大写的再执行
▼
▼
order by子句--执行顺序为从左到右排序,很耗资源
mysql 索引长度对索引的影响
惯用手法: 截取不同长度,并测试其区分度,
- select count(distinct left(word,6))/count(*) from dict;
- +---------------------------------------+
- | count(distinct left(word,6))/count(*) |
- +---------------------------------------+
- | 0.9992 |
- +---------------------------------------+</span>
截取word字段长度,从1开始截取,计算字符前缀没有重复的字符占全部数据的比例
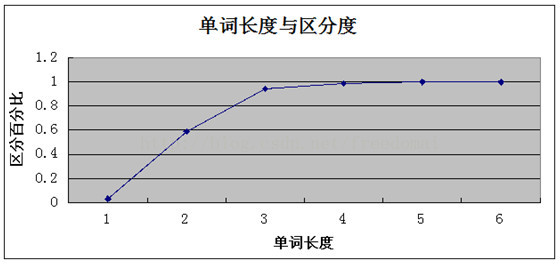
对于一般的系统应用: 区别度能达到0.1,索引的性能就可以接受.
创建指定长度的索引:
- CREATE INDEX index_name ON table_name (column_name(length), clolumn_name(length)…);















 2282
2282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









