






搭建预测模型
根据60款车型在22个细分市场(省份)的销量连续24个月的销量数据,建立销量预测模型;
基于该模型预测同一款车型和相同细分市场在接下来一个季度连续4个月份的销量;
- 数据字段包括(10个维度):
1月 - 12月
省份 省份编码 车型编码 车身类型 年 月 销量 搜索量 对车型相关新闻文章的评论数量 对车型的评价数量
初赛60款车型,复赛82款车型 - 目标
预测次年1月到4月各车型在各细分市场中的销量 - 评价指标
归一化均方根误差的均值
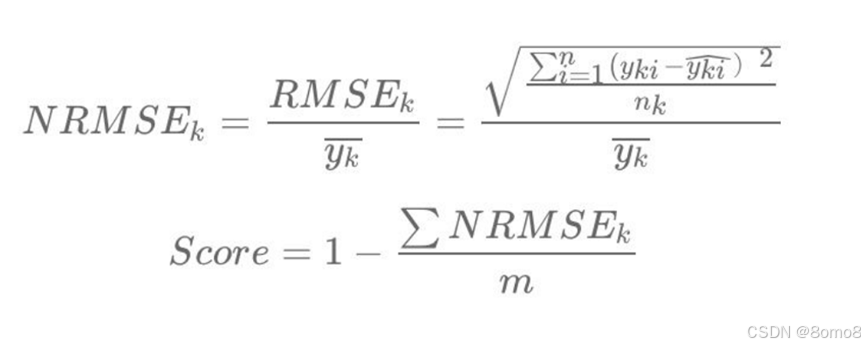
特征工程
包括传统的时序特征和统计特征,趋势特征,节假日特征。
销量环比:反映当前与历史前n个月的销量变化幅度
销量同比:反映当前与历史同期的销量变化幅度
历史销量:反映历史前n月销量大小
前几个月统计信息
省份、车型、月份编码、省份特征可以很好地对每个样本进行表征。
一阶、二阶差分特征:反应过去到现在的销量变化多少
EMA:该指标用在规则上效果显著
难点在一月和二月
注:16-18年的春节分别在二月、一月、二月
因此对春节所在月份进行了标记,还有当前月距离最近的春节间隔了几个月
def extract_feature(data, history, gap=1):
dataset = data.copy()
hist = history.copy()
dataset.reset_index(drop=True, inplace=True)
hist.reset_index(drop=True, inplace=True)
print('Before data shape: ', dataset.shape)
print('-' * 30)
'''历史特征'''
# sale
last_mt_sales, last_y_pops = [], []
prev_mt1_sales, prev_mt2_sales, prev_mt3_sales, prev_mt4_sales, prev_mt5_sales, prev_mt6_sales = [], [], [], [], [], []
prev_mt7_sales, prev_mt8_sales, prev_mt9_sales, prev_mt10_sales, prev_mt11_sales, prev_mt12_sales = [], [], [], [], [], []
last_mt_pops, last_y_pops = [], []
prev_mt1_pops, prev_mt2_pops, prev_mt3_pops, prev_mt4_pops, prev_mt5_pops, prev_mt6_pops = [], [], [], [], [], []
prev_mt7_pops, prev_mt8_pops, prev_mt9_pops, prev_mt10_pops, prev_mt11_pops, prev_mt12_pops = [], [], [], [], [], []
for row in dataset.itertuples():
# row = dataset[i:i+1][['province', 'model', 'regYear', 'regMonth']]
# values = row.values.tolist()[0]
province, model, regYear, regMonth = row.province, row.model, row.regYear, row.regMonth
# 去年同月
last_mt_sale = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-12)]['salesVolume'].values[0]
last_mt_sales.append(last_mt_sale)
last_mt_pop = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-12)]['popularity'].values[0]
last_mt_pops.append(last_mt_pop)
# 前几个月sale
prev_sale1 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-1)]['salesVolume'].values[0]
prev_mt1_sales.append(prev_sale1)
prev_sale2 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-2)]['salesVolume'].values[0]
prev_mt2_sales.append(prev_sale2)
prev_sale3 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-3)]['salesVolume'].values[0]
prev_mt3_sales.append(prev_sale3)
prev_sale4 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-4)]['salesVolume'].values[0]
prev_mt4_sales.append(prev_sale4)
prev_sale5 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-5)]['salesVolume'].values[0]
prev_mt5_sales.append(prev_sale5)
prev_sale6 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-6)]['salesVolume'].values[0]
prev_mt6_sales.append(prev_sale6)
prev_sale7 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-7)]['salesVolume'].values[0]
prev_mt7_sales.append(prev_sale7)
prev_sale8 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-8)]['salesVolume'].values[0]
prev_mt8_sales.append(prev_sale8)
prev_sale9 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-9)]['salesVolume'].values[0]
prev_mt9_sales.append(prev_sale9)
prev_sale10 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-10)]['salesVolume'].values[0]
prev_mt10_sales.append(prev_sale10)
prev_sale11 = hist[(hist['province']==province) & (hist['model']==model) & (hist['regMonth']==regMonth-11)]['salesVolume'].values[0]
prev_mt11_sales.append(prev_sale11)
多模型建模策略
模型使用 规则 + 机器学习lgb + 深度学习LSTM
LightGBMs,LSTMs ->多个模型、每个模型采用不同的特征子集 特征集合;
构建了多个机器学习模型和深度学习模型,最后分月线性加权融合得到最终结果。
–其中,为了避免误差传递:要预测1月的销量,则滑窗时用下一个月的销量对其进行打标;预测二月时,打标的时候要再间隔1个月;
预测三月时,打标的时候要再间隔2个月;预测四月时,打标的时候要再间隔3个月。
这种建模方式就有效避免了误差传递。
–其中,搭建的神经网络模型,是利用前n个月的销量预测当月销量,如:用1-9月预测10月,往后平移一个月,用2-10月预测11月的销量。评价指标使用的RMSE,预测结果对模型结构以及网络权重极其敏感,并且非常容易产生过拟合,我们除了使用Dropout和早停外,还尝试了SWA这种模型优化方法。SWA是一种基于权重空间进行加权的思想。
import os
import random
import warnings
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from keras import backend as K
from keras.utils import plot_model
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.preprocessing import MinMaxScaler
from keras.layers import LSTM, RNN, GRU, SimpleRNN
from sklearn.model_selection import train_test_split
from keras.initializers import glorot_uniform
seed = 2019
random.seed(seed)
tf.set_random_seed(seed)
np.random.seed(seed)
warnings.filterwarnings('ignore')
模型分月融合
不同模型对不同月份预测效果不一样,LSTM对3、4月预测更为精准,融合收益特别高,LGB2+LSTMs能到更高接近0.7。最终模型融合采用的分月融合策略
def model_fusion_function(value_1, value_2, value_3, value_4, month):
if month == 1:
return value_1 * w11 + value_2 * w21 + value_3 * w31
elif month == 2:
return value_1 * w12 + value_2 * w22 + value_3 * w32
elif month == 3:
return value_1 * w13 + value_2 * w23 + value_3 * w33 + w43 * value_4
elif month == 4:
return value_1 * w14 + value_2 * w24 + value_3 * w34 + w44 * value_4
综述
从实际业务场景出发,构造出多样、可解释强的特征;
采用深度学习方法分车型建模,有效地增加模型差异度;
使用神经网络模型优化方法SWA,减小模型误差。
###原始输入data数据等相关资源私信免费获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









