







问题1:为什么要调试GC参数?
在32核处理器的系统上,10%的GC时间导致75%的吞吐量损失。所以在大型系统上,调试GC是以小博大的不错选择。' small improvements in reducing such a bottleneck can produce large gains in performance.'
在32核处理器的系统上,10%的GC时间导致75%的吞吐量损失。所以在大型系统上,调试GC是以小博大的不错选择。' small improvements in reducing such a bottleneck can produce large gains in performance.'

问题2:怎么样调试GC?
调试GC,有
三个主要的参数:
- 选择合适的GC Collector
- 整个JVM Heap堆的大小
- Young Generation的大小(-Xmn?m or -XX:NewRatio=?)
问题3:有哪些不同的GC Collector?
Tony Printezis (JVM大牛)在
Garbage Collection in the Java HotSpot Virtual Machine有图为证,还有一篇更早的
sun开发人员介绍GC调试也是有图为证
neo4j总结如下
| GC shortname | Generation | Command line parameter | Comment |
|---|---|---|---|
| Copy | Young | | The Copying collector |
| MarkSweepCompact | Tenured | | The Mark and Sweep Compactor |
| ConcurrentMarkSweep | Tenured | | The Concurrent Mark and Sweep Compactor |
| ParNew | Young | | The parallel Young Generation Collector — can only be used with the Concurrent mark and sweep compactor. |
| PS Scavenge | Young | | The parallel object scavenger |
| PS MarkSweep | Tenured | | The parallel mark and sweep collector |
简而言之,Young和Tenured各种三种Collector,分别是
- Serial 单线程
- Parallel 多线程并行, GC线程和App线程取一运行,即GC要Stop the (app) world。
- Concurrent 多线程并发,GC线程和App线程可同时运行。(注: Young generation 没有CMS,取而代之的是可和CMS(Old)一起运行的ParNew)

问题4:如何选择Collector?
Serial可以直接排除掉,现在最普通的服务器也有双核64位\8G内存,默认的Collector是
PS Scavenge和PS MarkSweep。所以Collector在并行(Parallel)和并发(Concurrent)两者之间选择。
问题5:选择的标准(参数指标)是什么?如何得到这些参数值(How to measure it)?
throughput和latency。garbage-collection-in-java-part-3从GC的耗时给出了吞吐量和响应速度的公式
Total Execution Time = Useful Time + Paused Time
throughput = Useful Time / Total Execution Time
latency = average paused time
如何得到Useful time 和 Paused Time?即如何得到JVM的GC时间,有以下几种方式
GC Log
打印GC log,java 启动参数中加入下面的语句(本文为tomcat应用)。GC Log 记录每次GC时间,可根据GC Log计算平均GC时间和累积GC时间。
- CATALINA_OPTS="$CATALINA_OPTS -verbose:gc -Xloggc:/usr/local/tomcat/gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
JDK自带工具,java 启动参数中加入下面的语句(本文为tomcat应用),然后在监控端可以远程连接1090端口。在内存一项,有累积GC时间和次数。注意在以min为单位显示时,只显示整数部分,如1min20s显示为1min。
- CATALINA_OPTS="$CATALINA_OPTS -Dcom.sun.management.jmxremote.port=1090 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
JVM监控工具,未同JDK一起发布,可在JVisualvm(JDK自带)中以插件的方式使用,本文为独立使用。有累积GC时间和次数,并有曲线图直观显示。
首先在Server端启动jstatd
- vi jstatd.all.policy
- grant codebase "file:${java.home}/../lib/tools.jar" {
- permission java.security.AllPermission;
- };
- jstatd -J-Djava.security.policy=jstatd.all.policy
然后在监控启动VisualGC,远程连接服务端进程id
visualgc 102592@remote.domain
问题5:应用请求的吞吐量和响应是否可以反映JVM的性能?
正是我们调优的目标。本文使用Jmeter来做压力测试,并给出吞吐量和响应 report。
测试
硬件环境
|
| ||||||||||||||||||
Test case
- 使用用Jmeter压力测试
- 共6个client,每个client启动30个线程发送请求
- 每个请求从16种测试样例中随机挑选一个,发送到server端
- 测试持续10min
参数值
- server使用默认GC(PS Scavenge和PS MarkSweep)
- server使用CMS(-XX:+UseConcMarkSweepGC-XX:+UseParNewGC)
- server使用CMS(-XX:+UseConcMarkSweepGC -XX:+UseParNewGC),设置Young generation的大小为200m(-Xmn200m)
- server使用CMS(-XX:+UseConcMarkSweepGC -XX:+UseParNewGC),设置Young generation的大小为600m(-Xmn600m)
观察值
- Jmeter请求的summary report
- server端累积GC时间和次数
测试结果
1) CMS和Parallel比较
1.1) 吞吐量和响应
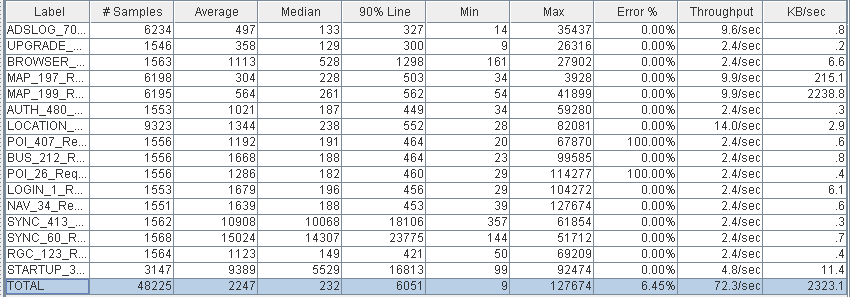 (PS Scavenge和PS MarkSweep)
(PS Scavenge和PS MarkSweep)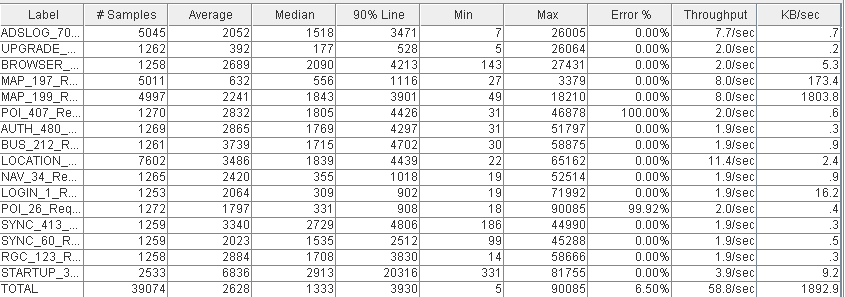 (ParNew和CMS)
(ParNew和CMS)
从Jmeter的report中可以看出, 使用CMS后吞吐量(对应总的请求数)下降18%,而最大响应时间(包括最小响应时间)有近30%的提升(变小)。这验证了Tony Printezis在Step-by-Step:Garbage Collection Tuning in the Java HotSpot™ Virtual Machine中说使用CMS应用的吞吐量会相对下降,但有更好的最差响应时间。
- Expect longer young GC times
- Due to slower allocations into the old gen
- Expect better worst-case latencies
- CMS does its work mostly-concurrently
- Shorter worst-case pauses
- Expect lower throughput
- CMS does more work
在官方的JVM性能调优中给出的建议也是,如果你的应用对峰值处理有要求,而对一两秒的停顿可以接受,则使用(-XX:+UseParallelGC);如果应用对响应有更高的要求,停顿最好小于一秒,则使用(-XX:+UseConcMarkSweepGC)。
1.2) GC 累积时间和次数
 (PS Scavenge和PS MarkSweep)
(PS Scavenge和PS MarkSweep)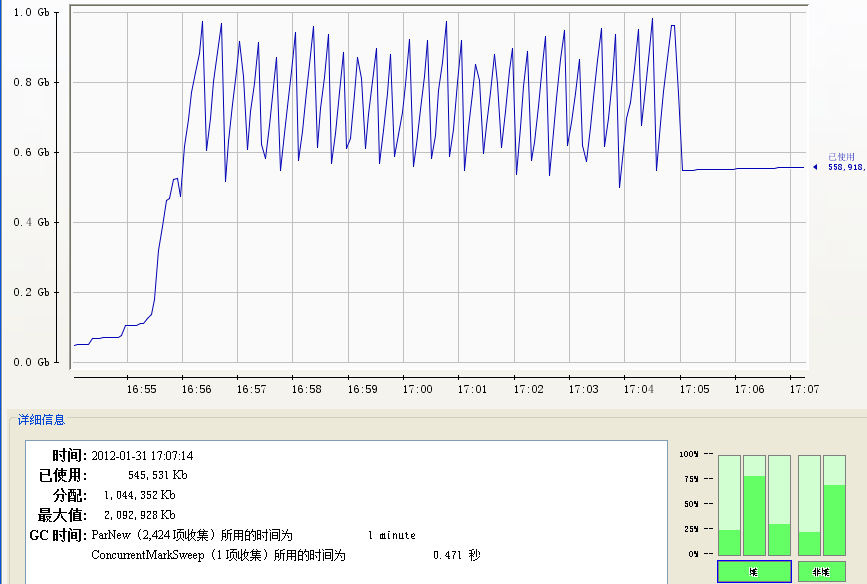 (ParNew和CMS)
(ParNew和CMS)
PS累积GC时间(visualgc)为1min25s,其中Eden 189次,共52s;old 13次,共33s。
CMS 累积GC(visualgc)为2min2s,其中Eden 2333次,共1min46s;old 55次,共16s。(Jconsole和GC log却显示没有Full GC,从understanding cms gc logs和jstat显示的full GC次数与CMS周期的关系中我推测visualgc与jstat显示一致,都是统计old的回收次数;而Full GC则是Young和Old一起回收,在其他类型的GC里,Old只有Full GC时才触发)。
可以看到PS的GC频率相对低,但每次GC时间长,每次Full在3s左右徘徊,Yong在0.3s左右;CMS则是短频快,频繁快速回收,yong在0.03s(<0.1s)左右,old<0.5s。从JMeter上,使用PS GC,Request Report会有间歇性的停顿,即server没有任何响应;CMS则相对较少,停顿不那么明显。
2) CMS下不同Xmn的比较
由于CMS Young太多频繁,又测试了分别调整Xmn为200m和600m之后的结果。200m是仿照cassandra中100m * cpu #来设置Young gen的大小;600m则是与PS下的Young gen一致。
 200m
200m 600m
600m
随着Young gen的增大(40m -> 200m -> 600m),Young 的回收次数减少,Old的回收次数增加,总体GC累积时间下降,应用吞吐量上升,最差响应时间变慢(即便和PS比较也更差,是我的测试有问题?)。
结论
app停顿3s是不可接受的,因此倾向于使用CMS;CMS的default young gen相当小,于是设置Xmn。对于更加Prefer响应的应用,下面配置是否是黄金标配:
JVM_OPTS = "$JVM_OPTS -XX:+UseParNewGC"JVM_OPTS = "$JVM_OPTS -XX:+UseConcMarkSweepGC"JVM_OPTS = "$JVM_OPTS -XX:+CMSParallelRemarkEnabled"JVM_OPTS = "$JVM_OPTS -XX:SurvivorRatio=8"JVM_OPTS = "$JVM_OPTS -XX:MaxTenuringThreshold=1"JVM_OPTS = "$JVM_OPTS -XX:CMSInitiatingOccupancyFraction=75"JVM_OPTS = "$JVM_OPTS -XX:+UseCMSInitiatingOccupancyOnly"















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









