









1. 使用常量内存的好处
- 访问常量内存时, GPU会针对访问同一个地址的half-warp(16个threads)只读取一次此地址.
- 被访问的常量内存被cache, 之后的对此地址的访问可以更加快捷.
如果half-warp内的threads需要访问不同的地址, 那么这些访问就会串行进行, 速度会比使用global memory要慢. 因为访问global memory是可以并行的.
2. 光线追踪问题
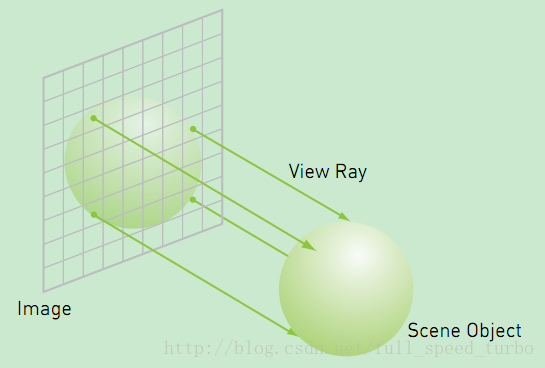
可以简化为: 从某一个像素射出的垂直于bitmap平面的射线,和当前球体相交,求出最近的一个交点.
可以设置不同大小, 位置和颜色的球体.
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#define INF 2e10f
#define rnd( x ) (x * rand() / RAND_MAX)
#define SPHERES 20 //球体数量
#define DIM 1024 // bitmap图大小
struct Sphere{
float r,b,g;
float radius;
float x,y,z; //球心
//从某一个像素射出的垂直于bitmap平面的射线,和当前球体相交,求出最近的一个交点
//没有交点就返回负无穷
__device__ float hit(float ox, float oy, float *n)
{
float dx = ox - x;
float dy = oy - y;
if(dx*dx + dy*dy < radius*radius)
{
float dz = sqrtf(radius*radius - dx*dx - dy*dy);
*n = dz / sqrtf( radius * radius);
return dz + z;
}
return -INF;
}
};
// kernel函数应该加入第二个参数Sphere* s
// 因为main函数里的s是host变量,不能由kernel使用
__global__ void kernel( unsigned char *ptr, Sphere *s)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x - DIM/2);
float oy = (y - DIM/2);
float r=0, g=0, b=0;
float maxz = -INF;
for (int i=0; i<SPHERES; i++)
{
float n;
float t = s[i].hit(ox, oy, &n);
if (t > maxz)
{
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
}
}
//四个通道赋值
ptr[offset*4 + 0] = (int)(r*255);
ptr[offset*4 + 1] = (int)(g*255);
ptr[offset*4 + 2] = (int)(b*255);
ptr[offset*4 + 3] = 255;
}
int main(void)
{
cudaEvent_t start, stop;
HANDLE_ERROR( cudaEventCreate( &start ) );
HANDLE_ERROR( cudaEventCreate( &stop ) );
HANDLE_ERROR( cudaEventCreate( &start, 0 ) );
CPUBitmap bitmap(DIM, DIM);
unsigned char *dev_bitmap;
Sphere *s;
HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap,
bitmap.image_size() ) );
HANDLE_ERROR( cudaMalloc( (void**)&s,
sizeof(Sphere) * SPHERES ) );
//球体参数在CPU上初始化
Sphere *temp_s = (Sphere*)malloc( sizeof(Sphere) * SPHERES );
for (int i=0; i<SPHERES; i++)
{
temp_s[i].r = rnd( 1.0f );
temp_s[i].g = rnd( 1.0f );
temp_s[i].b = rnd( 1.0f );
temp_s[i].x = rnd( 1000.0f ) - 500;
temp_s[i].y = rnd( 1000.0f ) - 500;
temp_s[i].z = rnd( 1000.0f ) - 500;
temp_s[i].radius = rnd( 100.0f ) + 20;
}
//把Sphere从主机拷贝到GPU上
HANDLE_ERROR( cudaMemcpy( s, temp_s,
sizeof(Sphere) * SPHERES,
cudaMemcpyHostToDevice ) );
free( temp_s );
// GPU上做处理
dim3 grids(DIM/16, DIM/16);
dim3 threads(16, 16);
kernel<<<grids,threads>>>(dev_bitmap, s);
//从GPU拷贝到Host上
HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(),
dev_bitmap,
bitmap.image_size(),
cudaMemcpyDeviceToHost ) );
bitmap.display_and_exit();
//free memory
cudaFree( dev_bitmap );
cudaFree( s );
}输出:

3. 在光线追踪问题中使用Constant Memory
使用常量内存要注意:
1. 分配常量内存不使用动态分配, 直接在编译时分配. 而且此声明不能放在函数体内部.
__constant__ Sphere s[SPHERES];- 将数据从Host拷贝到GPU的constant memory上需要使用:
cudaMemcpyToSymbol( s, temp_s, sizeof(Sphere) * SPHERES );完整代码:
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#define INF 2e10f
#define rnd( x ) (x * rand() / RAND_MAX)
#define SPHERES 20 //球体数量
#define DIM 1024 // bitmap图大小
struct Sphere{
float r,b,g;
float radius;
float x,y,z; //球心
//从某一个像素射出的垂直于bitmap平面的射线,和当前球体相交,求出最近的一个交点
//没有交点就返回负无穷
__device__ float hit(float ox, float oy, float *n)
{
float dx = ox - x;
float dy = oy - y;
if(dx*dx + dy*dy < radius*radius)
{
float dz = sqrtf(radius*radius - dx*dx - dy*dy);
*n = dz / sqrtf( radius * radius);
return dz + z;
}
return -INF;
}
};
// 不是指针
// 常量内存的声明不能放在函数体内部.
__constant__ Sphere s[SPHERES];
__global__ void kernel( unsigned char *ptr)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x - DIM/2);
float oy = (y - DIM/2);
float r=0, g=0, b=0;
float maxz = -INF;
for (int i=0; i<SPHERES; i++)
{
float n;
float t = s[i].hit(ox, oy, &n);
if (t > maxz)
{
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
}
}
//四个通道赋值
ptr[offset*4 + 0] = (int)(r*255);
ptr[offset*4 + 1] = (int)(g*255);
ptr[offset*4 + 2] = (int)(b*255);
ptr[offset*4 + 3] = 255;
}
int main(void)
{
cudaEvent_t start, stop;
HANDLE_ERROR( cudaEventCreate( &start ) );
HANDLE_ERROR( cudaEventCreate( &stop ) );
HANDLE_ERROR( cudaEventCreate( &start, 0 ) );
CPUBitmap bitmap(DIM, DIM);
unsigned char *dev_bitmap;
HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap,
bitmap.image_size() ) );
//常量内存不需要为之开辟GPU存储空间.
//HANDLE_ERROR( cudaMalloc( (void**)&s,
// sizeof(Sphere) * SPHERES ) );
//球体参数在CPU上初始化
Sphere *temp_s = (Sphere*)malloc( sizeof(Sphere) * SPHERES );
for (int i=0; i<SPHERES; i++)
{
temp_s[i].r = rnd( 1.0f );
temp_s[i].g = rnd( 1.0f );
temp_s[i].b = rnd( 1.0f );
temp_s[i].x = rnd( 1000.0f ) - 500;
temp_s[i].y = rnd( 1000.0f ) - 500;
temp_s[i].z = rnd( 1000.0f ) - 500;
temp_s[i].radius = rnd( 100.0f ) + 20;
}
//把Sphere从主机拷贝到GPU上
HANDLE_ERROR( cudaMemcpyToSymbol( s, temp_s,
sizeof(Sphere) * SPHERES ) );
free( temp_s );
// GPU上做处理
dim3 grids(DIM/16, DIM/16);
dim3 threads(16, 16);
kernel<<<grids,threads>>>(dev_bitmap);
//从GPU拷贝到Host上
HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(),
dev_bitmap,
bitmap.image_size(),
cudaMemcpyDeviceToHost ) );
bitmap.display_and_exit();
//free memory
cudaFree( dev_bitmap );
//cudaFree( s );
}














 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









