







完整 select 语法
select [select选项] 字段列表 [字段别名] / * from 数据源 [where条件子句] [group by子句] [having子句] [order by子句] [limit 子句];select选项:select对查出来的结果的处理方式
- all:默认的,保留所有的结果;
- distinct:去重,查出来的结果,将重复的去掉(整条记录的所有字段都相同,不能对单独字段进行处理)
Ex: select distinct from user;- 字段别名:字段 [as] 别名
Ex: select name as 姓名, sex 性别 from user;where子句
- 用于判断数据,筛选数据
- 返回结果:0或1
- 原理:where是唯一一个直接从磁盘获取数据的时候就开始判断的条件。从磁盘取出一条记录,开始进行where判断,判断的结果如果成立保存到内存,如果失败直接放弃。
Ex: select * from user where sex = '男';group by子句:根据某(些)字段进行分组,相同的放一组,不同的分到不同的组)
- 基本语法:group by 字段名;
- 统计:分组是为了统计数据(按分组字段进行统计)
- SQL提供了一系列统计函数
- count():统计分组后的记录数,即每一组有多少记录,可以有两种参数,*代表统计记录,字段名代表统计对应的字段(NULL 不统计)。
- max():统计每组中的最大值。
- min():统计每组中的最小值。
- avg():统计平均值。
- sum():统计和。
分组会进行自动排序:根据分组字段对分组的结果合并之后的整个结果进行排序,默认升序。
- group by [asc|desc];
多字段分组:先根据一个字段进行分组,然后对分组后的结果再次按照其他字段进行分组。
- group_concat函数:可以对分组结果的某个字段进行字符串连接(保留该组所有的某个字段),group_concat(字段名);

- 回溯统计 with rollup(不常用):任何一个分组后都会有一个小组,最后都需要向上级分组进行汇报统计。回溯统计时会将分组字段置空。


Ex:
-- 分组统计:身高高矮,平均年龄和总年龄
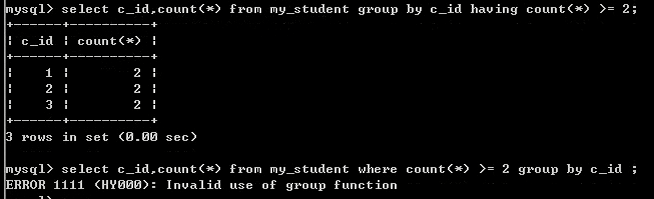
select sex,count(*),max(height),min(height),avg(age),sum(age) from student group by sex;having子句:同where作用相仿,进行条件判断。不同之处在于where子句是针对磁盘数据进行筛选,而having子句是针对内存中的数据进行筛选。
因为统计函数是在数据进入内存后才进行数据处理,所以使用统计函数后的SQL语句只能通过having子句进行数据处理。
having能够使用字段别名,where不能,where是从磁盘获取数据,而名字只能是字段名,别名是在字段进入内存后才会产生。

- order by子句
- 语法格式:order by 字段名 [asc|desc] [,字段名 [asc|desc]];
- 与group by对比:group by是为了统计,order by是为了让数据有序
- 排序可以进行多字段排序:先根据某个字段进行排序, 然后在排好序的内部按照下一个字段进行排序
Ex:select * from user order by name, sex desc;- limit子句
- 方案一:只限制数据量,limit 数据量;
- 方案二:限制起始位置和数据量,limit 起始位置,长度;
Ex:
select * from user limit 2;
select * from user limit 2,2;














 5855
5855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









