










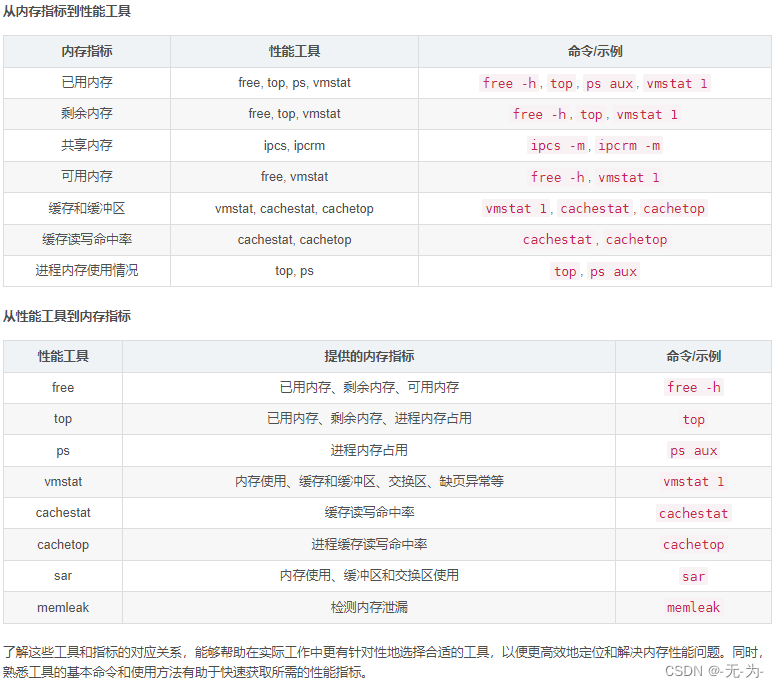
大多数场景,我们的Java web应用都是部署在linux环境,所以对linux服务器的性能指标需要有一个比较清晰的认识。Linux服务器的性能指标无非就5个方面:CPU、内存、磁盘、网络、文件系统。不同的性能指标都有对应的命令进行监控和查看(zabbix等监控工具,只是将服务器各个时间段的性能指标都收集起来,通过性能指标阈值进行告警,更容易也更直接,便于7*24分析;分析的指标也都是一样)。
性能调优的第一步就是性能分析,性能分析需要有参考的指标,有了性能指标,必须要做好监控,收集好性能数据,性能监控数据才是性能调优的依据和基础,在得到具体性能监控数据,依据性能指标,评估出性能瓶颈、才需要进行性能调优。不能为了调优而调优,那不是调优,而是耍流氓。
看到这里,可能有小伙伴会觉得这是“运维”的活,“运维”就是要时刻了解系统状态:cpu、内存、磁盘、网络和各种应用程序的运行于占用资源的状态等。然后对系统进行优化,以发挥更好的性能。其实不然,软件产品就像一个娃儿,作为开发、你们团队合作把娃儿生下来,难道就做甩手掌柜不管了么?他的生活环境、他的健康状态,也需要你来操心。
性能分析的目的
- 找出系统性能瓶颈
- 为以后的优化提供方案或者参考
- 达到良好利用资源的目的。硬件资源和软件配置。
性能分析的监控命令
放一张大佬整理的图,可以清晰看到5个方面相关的监控命令
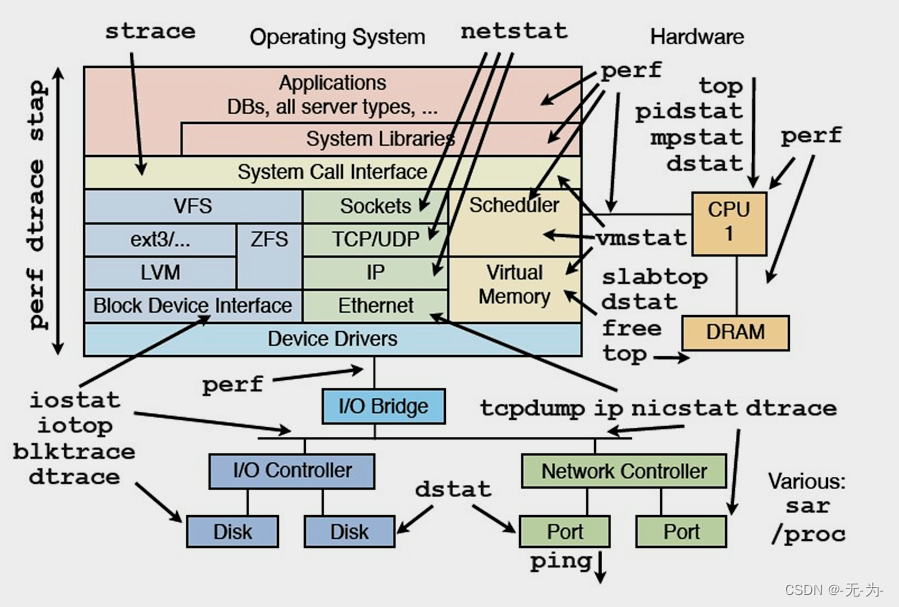
sar:收集、报告和保存系统活动信息。
sadf:以多种格式(例如 CSV、XML、JSON 等) 显示 sar 命令的输出。
iostat:报告 CPU 统计信息和输入/输出统计信息,用于设备和分区。
mpstat:报告关于各个可用 CPU 的统计信息。
pidstat:报告关于各个进程的统计信息。
tapestat:报告磁带驱动器统计信息。
cifsiostat:报告 CIFS 文件系统统计信息。
性能控指标
我们用到的命令包括:sar、top、free、vmstat、pidstat、iostat、netstat、lsof等。sar需要主动开启监控,可以保存历史监控数据,而且数据也很全cpu、内存、磁盘、网络都可以监控,其他命令都是实时监控,可以作为辅助,如vmstat则可以监控到上下文切换等。
基本上,一个top命令就可以反应大部分情况,除了网络。

影响性能因素
我们的java 应用分为OLTP联机事务处理、OLAP联机分析处理两大类。
OLTP:实时事务处理的支柱
OLTP(Online Transaction Processing,联机事务处理)是一种用于管理实时交易的数据处理系统。它的主要任务是确保数据库的完整性和一致性,并执行大量的读写操作。这些操作通常是简短的、小规模的,但需要快速完成。在银行、电商和其他需要实时处理大量交易的行业中,OLTP系统发挥着关键作用。
-
数据结构:OLTP系统通常采用关系型数据库(RDBMS),如MySQL、Oracle等。它们使用行存储方式,即数据以行为单位进行存储,这有利于快速读取和更新特定记录。
-
数据一致性:为了确保数据的一致性,OLTP系统采用了ACID(原子性、一致性、隔离性和持久性)属性。这意味着每个事务都必须完全执行,否则将回滚到事务开始前的状态。
-
读写操作:OLTP系统主要处理大量的插入、更新和删除操作。这些操作需要快速完成,以确保实时性。因此,OLTP系统通常使用索引来加速查询操作,并使用锁机制来防止数据冲突。
-
性能优化:为了提高性能,OLTP系统通常采用各种优化技术,如缓存、分区和负载均衡。这些技术有助于减少磁盘I/O和网络延迟,从而提高系统的吞吐量和响应时间。

OLAP:数据仓库与分析的基石
与OLTP不同,OLAP(Online Analytical Processing,联机分析处理)主要关注数据分析而非实时事务处理。它允许用户对大量历史数据进行复杂的查询和分析,以揭示隐藏在数据中的模式和趋势。数据仓库是OLAP系统的核心组成部分,用于存储和管理这些历史数据。
-
数据结构:与OLTP系统的行存储方式不同,OLAP系统通常采用列存储方式。这意味着数据以列为单位进行存储,这有利于执行聚合和计算操作,从而加速分析查询的速度。
-
数据聚合:OLAP系统支持多种数据聚合操作,如求和、平均值、最大值和最小值等。这些操作可以帮助用户对大量数据进行分组和汇总,以便更好地了解数据的分布和特征。
-
多维分析:OLAP系统支持多维数据分析,允许用户从不同角度查看数据。通过创建多维数据集(也称为数据立方体),用户可以对数据进行切片、切块和旋转等操作,以揭示数据中的关联和趋势。
-
查询性能:为了提高查询性能,OLAP系统通常采用各种优化技术,如索引、分区和并行处理。这些技术有助于减少查询响应时间,使用户能够更快地获取分析结果。

OLAP与OLTP的比较与权衡
虽然OLAP和OLTP在某些方面存在相似之处,但它们在数据结构、数据处理和分析能力等方面有着显著的差异。在实际应用中,企业需要根据自身的业务需求和数据特点来选择合适的系统。
-
数据结构:OLTP采用行存储方式,适用于实时事务处理;而OLAP采用列存储方式,适用于数据分析。
-
数据一致性:OLTP强调数据的强一致性,通过ACID属性确保每个事务的完整执行;而OLAP对一致性的要求相对较低,更注重查询和分析的性能。
-
读写操作:OLTP主要处理大量的插入、更新和删除操作,需要快速完成;而OLAP主要关注复杂的查询和分析操作,允许较长的响应时间。
-
性能优化:OLTP通过缓存、分区和负载均衡等技术提高性能;而OLAP则通过索引、分区和并行处理等技术优化查询性能。

无论是OLTP、还是OLAP,都需要用到不同的组件,不同的组件运行在不同的服务器上,以确保其相互之间不影响,不会有资源争用。从这一角度我们再次区分为CPU密集型和IO密集型。
cpu密集型:如web服务器Nginx、tomcat、apache等,需要cpu进行批处理和数学计算。
io密集型:如数据库服务器MySQL、Oracle、Redis等大量消耗内存和存储,对CPU(相对而言)和网络要去不高,一般都是CPU发起IO请求,然后进入sleep状态。

在实际应用中,任务的类型决定了对系统资源的需求和瓶颈,针对不同类型的任务进行合理的优化和资源分配,可以提高系统的性能和响应能力。
常见影响性能的场景如下:
- 大量的网页请求会填满运行队列、大量的上下文切换,中断
- 大量的磁盘些请求
- 网卡大量的吞吐
- 以及内存耗尽等。。
CPU
CPU使用情况: 通过检查cpu使用量,通过工具观测上下文切换、中断以及代码调用等方面来进行优化。检查CPU使用情况,查看正在处理器使用的百分比。根据具体需求,你可能需要了解CPU总体使用情况以及按流程或用户划分的细节,查看流程和用户的额外颗粒度,在问题出现时更容易进行故障排除。
cpu主要指标
以top、pidstat、vmstat为例主要指标是:使用率、上下文切换次数、平均负载;
- cup利用率[us <70%,sy<35%,id>=95% ]
- cs每秒上下文切换次数,越小越好[cs<100];
- cs和cpu利用率相关,如果能保持上面所说的利用率大量的切换可以接受
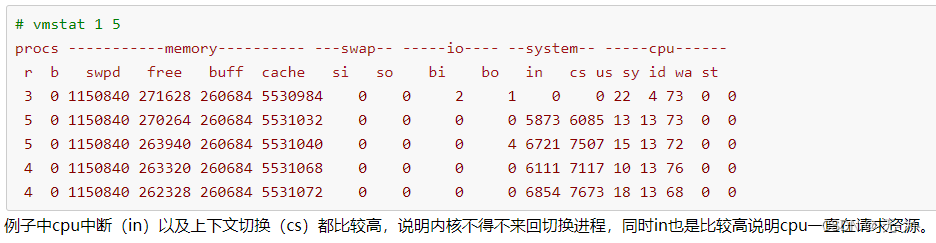
- 例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。如下图从0飙到6000多的cs:
- %iowait <= 100/cpu核心 %,等待 io 的 cpu 时间占比,这个值将在磁盘监控中再讲。
- Show the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.即CPU 在等待磁盘 I/O 请求完成时,处于空闲状态的时间百分比(此时正在运行着 idle 进程);Linux 会把 iowait 占用的时间输出到 /proc/stat 文件中,获取到 iowait 占用的时间:cat /proc/ stat
- 比如一个4颗物理CPU的系统,如果只有其中一颗物理CPU上有未完成IO请求,则iowait最高不会超过25%.
- load avg运行队列/平均负载 [ load avg/cpu核心数 < 5] (平均负载高有可能是cpu密集型任务)
在Linux系统中,uptime、w、top等命令都会有系统平均负载load average的输出 系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。 [ load avg/cpu核心数 < 5]
如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
例如:
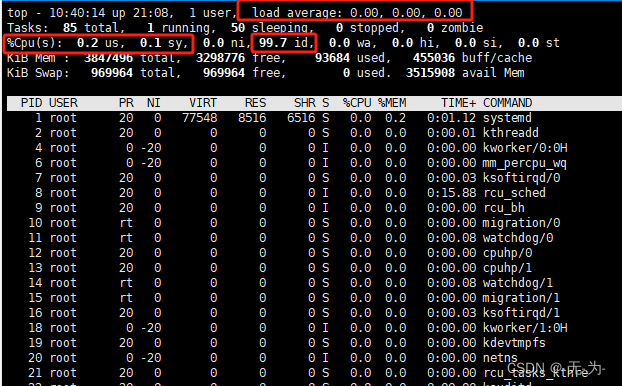
uptime 7:51pm up 2 days, 5:43, 2 users, load average: 8.13, 5.90, 4.94 命令输出的最后内容表示在过去的1、5、15分钟内运行队列中的平均进程数量。
一般来说只要每个CPU的当前活动进程数不大于3那么系统的性能就是良好的,如果每个CPU的任务数大于5,那么就表示这台机器的性能有严重问题。
[ load avg/cpu核心数 < 5] :对于上面的例子来说,假设系统有两个CPU,那么其每个CPU的当前任务数为:8.13/2=4.065。这表示该系统的性能是可以接受的。



4.调整进程优先级和绑定CPU
cpu负责所有计算任务,一般性能瓶颈很少出现在cpu上;服务器的cpu都是多核的,并且基于SMP(symmetric multiprocessing)结构的。
通过观察线上机器cpu使用率会发现,使用率很低很低,不到5%; 说明我们的资源浪费情况多么严重啊;(但为什么不能一台机器多部署几个应用呢,后边我会解释); 我们线上的cpu一个核支持超级线程,也就是一个核上可以并行运行几个线程)
1. 通过调整进程优先级调整:
nice 命令来调整进程优先级别;可调范围(-20到 19) 如: renice 5 pid
2.通过调整cpu的亲和度来集中处理某一个中断类型:将系统发出的中断都绑定在一个cpu上,这样其他cpu继续执行自己正在执行的线程,不被中断打扰,从而较少了线程上下文切换时间,增强性能;(如Nginx支持将进程绑定到cpu核心上)
注: cpu亲和度的概念: 在多核cpu中,linux操作系统抢占式调度系统,按照cpu时间片/中断/等 不断调度进程给cpu去执行的;如果在一个时间片调度线程1在cpu1上运行,另外一个时间片调度线程1在cpu2上去运行,这样会造成线程执行速度慢,性能降低。
为什么呢? 我们知道SMP上多核都是共享L1 ,L2 CPU Cache的。并且各个核的内存空间都是不可共享的,一个线程如果多次时间片上在不同的cpu上运行,会造成cache的不断失效和写入;性能会降低; 而linux的进程调度有个亲和度算法可以将尽量将进程每次都调度到同一个cpu上处理;linux调度时当然也有Loadbalance算法保证进程调度的均匀负载的;
例如: echo 03 > /proc/irq/19/smp-affinity (将中断类型为19的中断绑定到第三个cpu上处理)
内存
内存使用情况:总共用了多少内存以及单个进程和用户进和。根据需要,可以按百分比和/或GB/MB监控内存之使用情况。【查找内存泄漏】
Swap使用:Swap交换空间是保留的磁盘空间,是在可用内存不足时补充内存使用量。你的系统如何积极地使用交换空间取决于如何在1(低)到100(高)的范围内配置它的“swappiness”。如果要在系统内出现内存问题时允许进行一些交换而不完全禁用它(为0),使用10或更小的值是一个常态。当查看“交换空间使用情况”时,我们通常会看交换空间使用情况是否显著上升。如果真是如此,需要查内存和其他资源,看看自己是否可以挖掘到原因。【不使用swap,用了则说明内存不足】
CPU是不能与硬盘打交道的,只有数据被载入到内存中才可以被CPU调用。cpu在访问内存的时候需要先像内存监控程序请求,由监控程序控制和分配内存的读写请求,这个监控程序叫做MMU(内存管理单元)
线性地址到物理地址的映射,如果按照1个字节1个字节映射的话,需要一张非常大的表,这种转换关系会非常的复杂。因此把内存空间又划分成了另外一种存储单元格式,通常为4K。
每个进程如果需要访问内存的时候都需要去查找page table的话需要借助缓冲器TLB,但每次产找tlb没有或者大量查找还是会造成缓慢,所以又有了page table的分级目录。page table可以分为1级目录,2级目录和偏移量。
另外让系统管理大量内存有两种方法:
- 增加硬件内存管理单元中页表数
-
增大页面大小
第一种方法不太现实,所有我们考虑第二种方法。即:大页面。
32位系统4m大页框64位系统2m大页框,页框越粗浪费越严重。
查看系统的大页面:cat /proc/meminfo
AnonHugePages: 309248 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 6144 kB
DirectMap2M: 1042432 kB
DirectMap1G: 0 kB
AnonHugePages:透明大页面,THP是一个提取层,可自动创建、管理和使用超大页面的大多数方面。
另外HP必须在引导时设置。
手动设置大页面的页数:
sysctl vm.nr_hugepages = 20
DMA:直接读取内存
在实现DMA传输时,是由DMA控制器直接掌管总线,因此,存在着一个总线控制权转移问题。即DMA传输前,CPU要把总线控制权交给DMA控制器,而在结束DMA传输后,DMA控制器应立即把总线控制权再交回给CPU。一个完整的DMA传输过程必须经过DMA请求、DMA响应、DMA传输、DMA结束4个步骤。
虚拟内存:
32位的系统上每一个进程在访问内存的时候,每一个进程都当做自己有4个G的内存空间可用,这叫虚拟内存(地址),虚拟内存转化成物理内存是通过MMU来完成的。生产中我们尽量不使用虚拟内存。
影响系统性能的几个内存参数:
- overcommit_memory 过量使用内存
- 0 默认设置系统决定是否过量使用。
- 1 不过量使用
- 2 过量使用但有一定的比例默认百分值五十由overcommit_ratio决定(他就是默认的50),举个例子物理内存8g,swap4g,可以过量使用10g。
注:生产中尽量避免过量使用,例如redis要关闭过量使用。
- spappines
-将不活跃的进程换进swap。注:尽量不去使用swap。
生产中设置:
echp 10 > /proc/sys/vm/swappines - 回收内存
- 这个值设定为 1、2 或者 3 让内核放弃各种页缓存和 slab 缓存的各种组合。
1 系统无效并释放所有页缓冲内存即buffers
2 系统释放所有未使用的 slab 缓冲内存。即cached
3 系统释放所有页缓冲和 slab 缓冲内存。
生产中使用:
1.运行sync
- echo 3>/proc/sys/vm/drop_caches
- 这个值设定为 1、2 或者 3 让内核放弃各种页缓存和 slab 缓存的各种组合。
内存监控工具
分析示例
例子一:缓存占用过高
观察内存情况:
使用 free -h 查看内存占用情况,发现大部分内存被缓存占用。
确认缓存趋势:
运行 vmstat 1 或 sar 观察缓存的变化趋势,判断是否持续增长。
使用缓存分析工具:
如果缓存持续增长,使用缓存/缓冲区分析工具如 cachetop 或 slabtop 分析具体占用缓存的进程或对象。
例子二:系统可用内存不足
检查内存使用情况:
使用 free -h 发现系统可用内存不足,需要确认是否被缓存/缓冲区占用。
定位占用内存最多的进程:
运行 top 或 pidstat 定位占用内存最多的进程。
分析进程地址空间:
使用进程内存空间工具如 pmap 分析占用内存的进程的地址空间,了解具体内存使用情况。
例子三:内存不断增长,可能存在内存泄漏
观察内存趋势:
使用 vmstat 1 或 sar 观察内存的增长趋势。
检查内存泄漏:
运行内存分配分析工具如 memleak 进行内存泄漏检测。
分析内存泄漏的进程:
如果存在内存泄漏问题,memleak 会输出涉及内存泄漏的进程和相应的调用堆栈信息。内存主要指标
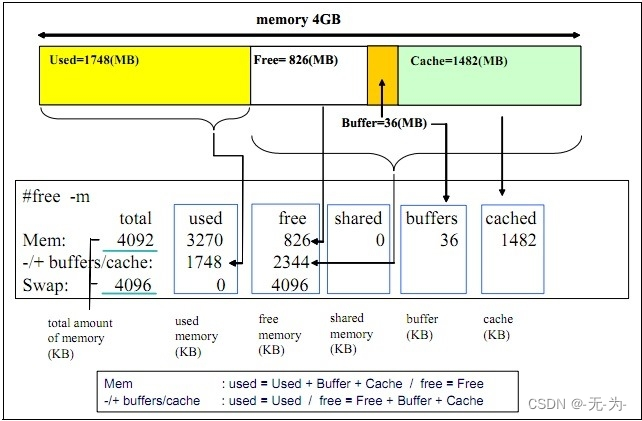
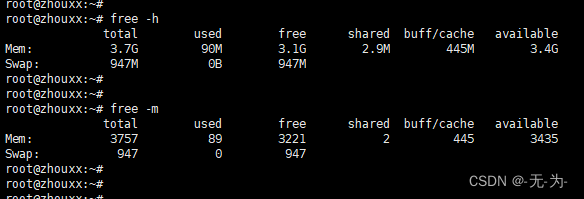
运行"free -m"命令得到的,它展示服务器当前的内存使用情况。
- total:表示服务器上总共的内存大小,3757MB。
- used:表示服务器当前正在使用的内存大小,89MB。
- free:表示服务器当前没有被使用的内存大小,3221MB。
- shared:表示被多个进程共享的内存大小,2MB。
- buff/cache:表示被缓存的内存大小,445MB。
- buff(Buffer Cache):用于缓存块设备的数据,包括文件读写的数据块、文件系统元数据等。当一个文件被读取时,数据块会被缓存到buff中,如果文件再次读取就可以直接从buff中读取,避免了再次从磁盘中读取数据的时间开销。buff通常用于缓存较小的数据块,如文件系统的元数据、目录项等。
- cache(Page Cache):用于缓存文件的数据,包括文件内容等。当一个文件被读取时,文件数据会被缓存到cache中,如果文件再次读取就可以直接从cache中读取,避免了再次从磁盘中读取数据的时间开销。与buff不同的是,cache用于缓存较大的数据块,如文件内容等。
- available:表示当前可用的内存大小,3435MB(真正可用内存)。在Linux系统中,available表示系统可用的内存总量,不包括已经被系统缓存或者保留的内存。具体来说,available指的是系统当前可用的空闲内存加上缓存的内存(包括buff/cache)和交换空间的内存。
内存指标参考
应用程序可用内存/系统物理内存>70%,
表示系统内存资源非常充足,不影响系统性能;
应用程序可用内存/系统物理内存<20%,
表示系统内存资源紧缺,需要增加系统内存;
20%<应用程序可用内存/系统物理内存<70%,
表示系统内存资源基本能满足应用需求,暂时不影响系统性能内存优化建议
内存问题优化思路:一旦定位到内存问题的来源,接下来的工作就是优化。内存调优的关键目标是确保应用程序的热点数据放在内存中,同时尽量减少换页和交换的次数。
以下是一些常见的优化思路:
禁用 Swap
最好禁用 Swap,尤其是在高性能应用场景下。可以通过修改 /etc/fstab 文件中的相关配置来禁用 Swap。降低 swappiness 值,通过修改 /proc/sys/vm/swappiness 或者 /etc/sysctl.conf 来减少系统对 Swap 的使用倾向。
sudo swapoff -a
修改 swappiness 值
echo "vm.swappiness=10" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p减少动态内存分配:
- 使用内存池、大页(Hugepage)等技术,减少频繁的动态内存分配。
- 使用内存分析工具(如 valgrind)检测和减少内存泄漏。
优化数据访问,使用缓存和缓冲区:
- 使用堆栈来明确声明内存空间,以存储需要缓存的数据。
- 利用外部缓存组件(如 Redis)来优化数据的访问,减少对数据库的频繁访问。
使用 cgroups 限制进程内存使用:
使用 cgroups 控制组,限制特定进程或组内进程的内存使用情况。
创建 cgroup
sudo cgcreate -g memory:/mygroup
限制内存使用
echo "100M" > /sys/fs/cgroup/memory/mygroup/memory.limit_in_bytes调整 OOM Score:
通过调整 /proc/pid/oom_adj 文件,调整进程的 OOM 分数,确保关键应用即使在内存紧张时也不会被 OOM 杀死。
查看当前 OOM 分数
cat /proc//oom_adj
调整 OOM 分数
echo "-17" > /proc//oom_adj磁盘
磁盘使用情况:使用了多少磁盘空间。与内存使用情况类似,可以按百分比或空间来监控磁盘使用情况。还应该跟踪inode的使用情况,Inode用于存储系统中文件系统对象的信息。耗尽inode不常见,但还是要检查一下,如果你碰巧知道服务器上运行的应用程序往往有很多小文件,就像一些CI/CD工具那样。重点关注空闲容量、io状态。
linux的子系统VFS(virtural file system)虚拟文件系统;从高层将各种文件系统,以及底层磁盘特性隐藏,对程序员提供:read,write,delete等文件操作;这就是之所以我们可以在linux上mount多种不同格式的文件系统的,而window确不行; 当然基于:虚拟文件系统,文件系统,文件系统驱动程序,硬件特性方面,都能找到性能瓶颈;
1.选择适合应用的文件系统;
2. 调整进程I/O请求的优先级,分三种级别:1代表 real time ; 2代表best-effort; 3代表idle ; 如:ionice -c1 -p1113(给进程1113的I/O优先级设置为最高优先级)
3.根据应用类型,适当调整page size 和block size;
4.升级驱动程序;
磁盘监控工具
sar: sar -d 收集报告系统活动信息。
iotop: iotop -oPa 监控磁盘io使用情况
vmstat: 用于监控虚拟内存、进程、cpu活动等信息
iostat:iostat -dx 1 用于监控cpu、io使用的情况。
smartctl: smartctl -a /dev/sda 查询磁盘健康状态和硬件参数。
磁盘性能测试工具,一般用于测试磁盘读写速度:dd、hdparm
dd:可以用来测试磁盘的读写速度。
写速度测试:
dd if=/dev/zero of=testfile bs=1G count=1 oflag=dsync
读速度测试:
dd if=testfile of=/dev/null bs=1G count=1 iflag=dsync hdparm :sudo hdparm -t /dev/sda 可以用来测试磁盘的性能。
磁盘主要指标
一般是通过top的 iowait>100/cpu核心数 %,来判断io忙,需要继续用iostat来分析。IOwait 是指CPU空闲时,且当前有task在等待IO的时间。因IO阻塞而调度主要出现在 1.等待数据返回; 2.并发IO时竞争资源。
影响该时间的因素很多,不只有IO负载,CPU负载也会严重影响该参数,不可一味根据IOwait判断系统的IO压力,还需要结合iostat 等数据综合判断。
iowait的一些事实
(1) %iowait合理值取决于应用IO特点。比如备份任务往往iowait较高;而cache命中率高、磁盘读写少的应用负载iowait一般不高。
(2) 从上述说明可以看到,减少%iowait的方法有两类:一类是进一步缩减IO处理时间,比如采用SSD盘,或者甚至内存盘等技术;
(3) %iowait比例与是否存在IO性能问题并无直接关系:低iowait也不代表没有磁盘性能问题;参考第二点,完全可能在实际上IO服务时间非常长,但由于系统中同时存在CPU密集型任务掩盖了iowait。高iowait不一定代表有磁盘性能问题;因为系统可能比较空闲,而业务类型是IO密集型比如备份。
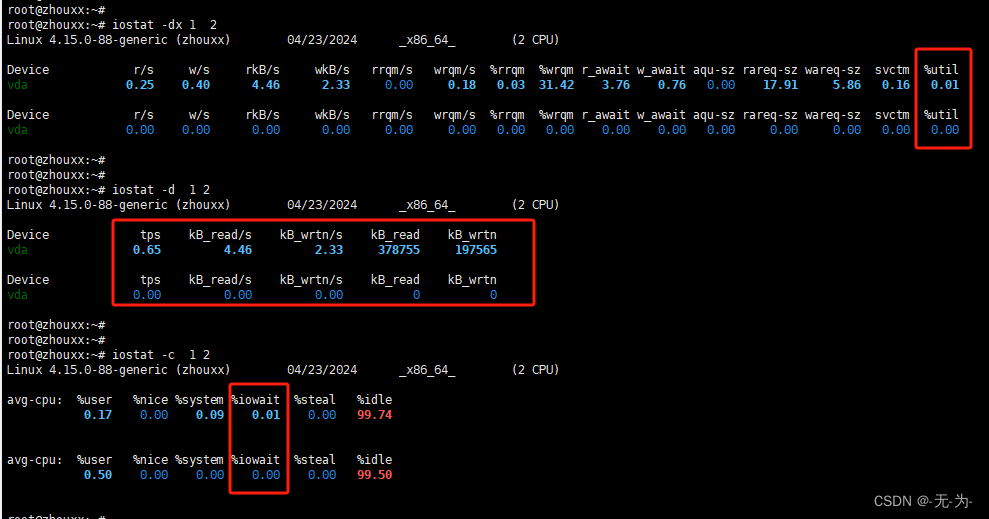
如上图
cpu %iowait < 100/2%=50%
disk %util 列就是我们关心的磁盘利用率。该值表示磁盘的负载程度,即磁盘处于忙碌状态的时间比例。%util值越高,表示磁盘越繁忙。[%util <= 70% ]
在性能测试中,我们可以重点关注iowait%和%util参数。其中iowait% 表示CPU等待IO时间占整个CPU周期的百分比,如果iowait值超过50%,或者明显大于%system、%user以及%idle,表示IO可能存在问题了;%util表示磁盘忙碌的情况,一般%util<=70%表示io状态良好。
字段说明:
rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并;
wrqm/s: 每秒对该设备的写请求被合并次数;
r/s: 每秒完成的读次数;
w/s: 每秒完成的写次数;
rkB/s: 每秒读数据量(kB为单位);
wkB/s: 每秒写数据量(kB为单位);
avgrq-sz:平均每次IO操作的数据量(扇区数为单位);
avgqu-sz: 平均等待处理的IO请求队列长度;
await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位);
svctm: 平均每次IO请求的处理时间(毫秒为单位);
%util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率;%util 和磁盘设备饱和度
注意,%util是最容易让人产生误解的一个参数。看到%util 等于100%就说硬盘能力到顶了,这种说法是错误的。util=100%并不意味着磁盘读写能力到了瓶颈(只代表单车道到了瓶颈,不代表别的车道不能走车),也并不意味着业务系统的TPS到了瓶颈,因为业务的吞吐量(单位时间请求数)和读写磁盘的IO并不是一一对应的关系。
%util数据源自diskstats中的io_ticks,这个值并不关心等待在队里里面IO的个数,它只关心队列中有没有IO。
和超时排队结账这个类比最本质的区别在于,现代硬盘都有并行处理多个IO的能力,但是收银员没有。收银员无法做到同时处理10个顾客的结账任务而消耗的总时间与处理一个顾客结账任务相差无几。但是磁盘可以。所以,即使%util到了100%,也并不意味着设备饱和了。
最简单的例子是,某硬盘处理单个IO请求需要0.1秒,有能力同时处理10个。但是当10个请求依次提交的时候,需要1秒钟才能完成这10%的请求,,在1秒的采样周期里,%util达到了100%。但是如果10个请一次性提交的话, 硬盘可以在0.1秒内全部完成,这时候,%util只有10%。
因此,在上面的例子中,一秒中10个IO,即IOPS=10的时候,%util就达到了100%,这并不能表明,该盘的IOPS就只能到10,事实上,纵使%util到了100%,硬盘可能仍然有很大的余力处理更多的请求,即并未达到饱和的状态。
磁盘优化建议
当磁盘的%util很高时,可能会导致系统性能下降。为了解决这个问题,可以采取以下优化措施:
1. 减少IO请求
- 合并和批量处理IO请求:将多个小的IO请求合并为一个更大的IO请求,减少IO请求的次数。
- 使用缓存:通过使用缓存来减少磁盘IO请求的数量,提高系统的性能。
2. 增加磁盘性能
- 使用高性能磁盘:将低性能磁盘替换为高性能磁盘,如SSD。
- 使用RAID:通过使用RAID技术,可以将多个磁盘组合成一个逻辑卷,提高磁盘的性能和可靠性。
3. 调整系统参数
- 调整磁盘调度算法:磁盘调度算法可以影响磁盘IO性能。根据具体情况选择合适的调度算法,如deadline、noop或cfq。
网络
网络活动:监控网络流量需要哪些精确度,取决于服务器托管的内容。在通常情况下,即使运行静态站点但未主动访问的服务器也会看到运行在其上的其他进程的I/O,服务器网络不应该降到0。包括网速、延迟、丢包率、连接数、流量等。
网络性能指标是评估网络连接和通信效率的关键指标。这些指标直接影响着用户体验、应用程序的响应时间以及系统的可用性。了解这些指标可以帮助您发现潜在的问题,并优化网络架构,提高系统性能。
网络主要指标
-
带宽(Bandwidth): 衡量网络连接传输数据的速率,通常以每秒比特数(bps)为单位。较高的带宽意味着更多的数据可以在同一时间内传输。
-
延迟(Latency): 衡量数据从源到目的地所需的时间。低延迟是实时应用程序(如视频通话或在线游戏)的关键。
-
丢包率(Packet Loss): 衡量在数据传输过程中丢失的数据包的百分比。高丢包率可能导致数据重传和性能下降。
-
吞吐量(Throughput): 衡量在网络上实际传输的数据量。与带宽不同,吞吐量考虑了网络上可能的瓶颈和拥塞。
-
连接数:主要是TCP连接数
网络监控工具
qperf
、qperf常用参数说明
以下是qperf常用参数说明:
-t 测试时间,单位为秒,默认值为10秒。
-l 数据长度,单位为字节,默认值为64字节。
-p 测试端口,默认值为端口号为19765。
-i 测试的间隔时间,默认值为1s。
-u 使用UDP协议进行测试。
-v 输出详细的测试结果。可以多次使用增加详细度。
-s 指定服务器地址。
-ca 指定客户端的CPU亲和性(即将进程绑定到某个CPU核心上)。
-rca 指定远程服务器的CPU亲和性。
-lca 指定本地服务器的CPU亲和性。
-fb 指定反向测试的数据流。
-u 指定使用UDP协议进行测试。
-ua 指定UDP测试的数据包大小,默认为1470字节。
这些参数可以通过在命令行中添加对应的参数来使用。例如,以下命令将使用UDP协议进行1秒钟的测试,并输出详细的测试结果:
qperf 192.168.1.100 -u -t 1 -v

监控说明
-vvu表示开启详细输出,包括每个测试项的详细性能数据。
tcp_lat和udp_lat分别表示TCP和UDP的单向延迟测试。
tcp_bw和udp_bw分别表示TCP和UDP的双向吞吐量测试。
conf表示输出测试节点的配置信息。
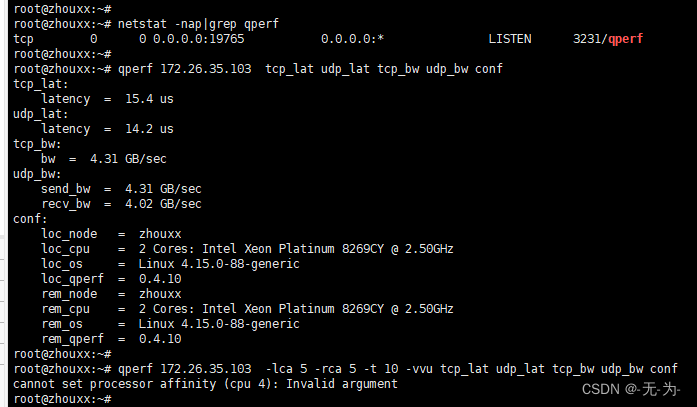
输出结果显示了针对远程节点的四个不同性能测试的结果,以及测试节点的配置信息:
tcp_lat:TCP的单向延迟测试结果,latency为1.61us,msg_size为1字节,表示测试发送和接收1字节的数据所需的平均时间。
udp_lat:UDP的单向延迟测试结果,latency为1.42us,msg_size为1字节,表示测试发送和接收1字节的数据所需的平均时间。
tcp_bw:TCP的双向吞吐量测试结果,bw为13.3GB/sec,msg_size为64KB,表示测试在10秒内双向传输64KB数据时的平均带宽。
udp_bw:UDP的双向吞吐量测试结果,send_bw和recv_bw均为10.6GB/sec,msg_size为32KB,表示测试在10秒内发送和接收32KB数据时的平均带宽。
conf:测试节点的一些配置信息,包括本地节点和远程节点的名称、CPU类型、操作系统、qperf版本等。
sar
命令说明
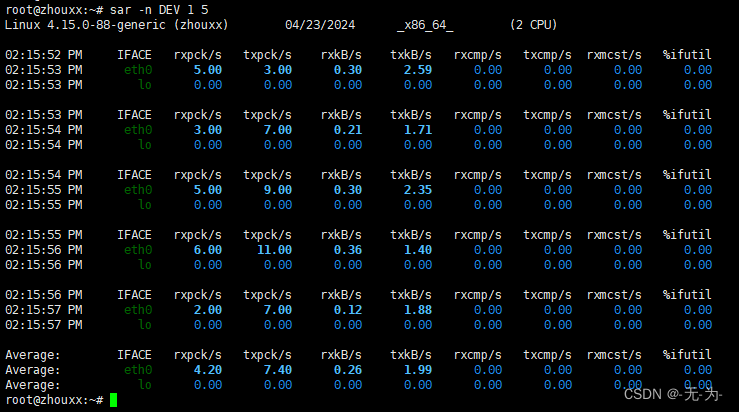
给sar增加-n参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP等等。
sar -n DEV 1
输出指标的含义:
rxpck/s和txpck/s:分别是接收和发送的PPS,单位为包/秒
rxkB/s和txkB/s:分别是接收和发送的吞吐量,单位是kB/秒
rxcmp/s和txcmp/s:分别是接收和发送的压缩包数,单位是包/秒
%ifutil:网络接口的使用率,半双工模式下为 (rxkB/s + txkB/s) / BandWidth,而全双工模式下为max(rxkB/s, txkB/s) / BandWidth
此命令除了可以用于查看网卡的信息,还可以用来搜集如下服务的状态信息:
-A:所有报告的总和
-u:CPU使用率
-v:进程、I节点、文件和锁表状态
-d:硬盘的使用报告
-r:没有使用的内存页面和硬盘块
-g:串口I/O的情况
-b:缓冲区的使用情况
-a:文件的读写情况
-c:系统的调用情况
-R:进程的活动情况
-y:终端设备的活动情况
-w:系统的交换活动
其他命令ping、telnet、netstat、tracert、nslookup就不讲了
网络优化建议
建议1:尽量减少不必要的网络 IO
不必要用网络 IO 的尽量不用。
是的,网络在现代的互联网世界里承载了很重要的角色。用户通过网络请求线上服务、服务器通过网络读取数据库中数据,通过网络构建能力无比强大分布式系统。网络很好,能降低模块的开发难度,也能用它搭建出更强大的系统。但是这不是你滥用它的理由!
原因是即使是本机网络 IO 开销仍然是很大的。先说发送一个网络包,首先得从用户态切换到内核态,花费一次系统调用的开销。进入到内核以后,又得经过冗长的协议栈,这会花费不少的 CPU 周期,最后进入环回设备的“驱动程序”。接收端呢,软中断花费不少的 CPU 周期又得经过接收协议栈的处理,最后唤醒或者通知用户进程来处理。当服务端处理完以后,还得把结果再发过来。又得来这么一遍,最后你的进程才能收到结果。你说麻烦不麻烦。另外还有个问题就是多个进程协作来完成一项工作就必然会引入更多的进程上下文切换开销,这些开销从开发视角来看,做的其实都是无用功。
上面我们还分析的只是本机网络 IO,如果是跨机器的还得会有双方网卡的 DMA 拷贝过程,以及两端之间的网络 RTT 耗时延迟。所以,网络虽好,但也不能随意滥用!
建议2:尽量合并网络请求
在可能的情况下,尽可能地把多次的网络请求合并到一次,这样既节约了双端的 CPU 开销,也能降低多次 RTT 导致的耗时。
我们举个实践中的例子可能更好理解。假如有一个 redis,里面存了每一个 App 的信息(应用名、包名、版本、截图等等)。你现在需要根据用户安装应用列表来查询数据库中有哪些应用比用户的版本更新,如果有则提醒用户更新。
那么最好不要写出如下的代码:
<?php
for(安装列表 as 包名){
redis->get(包名)
...
}上面这段代码功能上实现上没问题,问题在于性能。据我们统计现代用户平均安装 App 的数量在 60 个左右。那这段代码在运行的时候,每当用户来请求一次,你的服务器就需要和 redis 进行 60 次网络请求。 总耗时最少是 60 个 RTT 起。更好的方法是应该使用 redis 中提供的批量获取命令,如 hmget、pipeline等,经过一次网络 IO 就获取到所有想要的数据,如图。

建议3:调用者与被调用机器尽可能部署的近一些
在前面的章节中我们看到在握手一切正常的情况下, TCP 握手的时间基本取决于两台机器之间的 RTT 耗时。虽然我们没办法彻底去掉这个耗时,但是我们却有办法把 RTT 降低,那就是把客户端和服务器放的足够地近一些。尽量把每个机房内部的数据请求都在本地机房解决,减少跨地网络传输。
举例,假如你的服务是部署在北京机房的,你调用的 mysql、redis最好都位于北京机房内部。尽量不要跨过千里万里跑到广东机房去请求数据,即使你有专线,耗时也会大大增加!在机房内部的服务器之间的 RTT 延迟大概只有零点几毫秒,同地区的不同机房之间大约是 1 ms 多一些。但如果从北京跨到广东的话,延迟将是 30 - 40 ms 左右,几十倍的上涨!
建议4:内网调用不要用外网域名
假如说你所在负责的服务需要调用兄弟部门的一个搜索接口,假设接口是:"http://www.sogou.com/wq?key=开发内功修炼"。
那既然是兄弟部门,那很可能这个接口和你的服务是部署在一个机房的。即使没有部署在一个机房,一般也是有专线可达的。所以不要直接请求 http://www.sogou.com, 而是应该使用该服务在公司对应的内网域名。在我们公司内部,每一个外网服务都会配置一个对应的内网域名,我相信你们公司也有。
为什么要这么做,原因有以下几点
1)外网接口慢。本来内网可能过个交换机就能达到兄弟部门的机器,非得上外网兜一圈再回来,时间上肯定会慢。
2)带宽成本高。在互联网服务里,除了机器以外,另外一块很大的成本就是 IDC 机房的出入口带宽成本。 两台机器在内网不管如何通信都不涉及到带宽的计算。但是一旦你去外网兜了一圈回来,行了,一进一出全部要缴带宽费,你说亏不亏!!
3)NAT 单点瓶颈。一般的服务器都没有外网 IP,所以要想请求外网的资源,必须要经过 NAT 服务器。但是一个公司的机房里几千台服务器中,承担 NAT 角色的可能就那么几台。它很容易成为瓶颈。我们的业务就遇到过好几次 NAT 故障导致外网请求失败的情形。 NAT 机器挂了,你的服务可能也就挂了,故障率大大增加。
建议5:调整网卡 RingBuffer 大小
在 Linux 的整个网络栈中,RingBuffer 起到一个任务的收发中转站的角色。对于接收过程来讲,网卡负责往 RingBuffer 中写入收到的数据帧,ksoftirqd 内核线程负责从中取走处理。只要 ksoftirqd 线程工作的足够快,RingBuffer 这个中转站就不会出现问题。
但是我们设想一下,假如某一时刻,瞬间来了特别多的包,而 ksoftirqd 处理不过来了,会发生什么?这时 RingBuffer 可能瞬间就被填满了,后面再来的包网卡直接就会丢弃,不做任何处理!

通过 ethtool 就可以加大 RingBuffer 这个“中转仓库”的大小。。
# ethtool -G eth1 rx 4096 tx 4096
这样网卡会被分配更大一点的”中转站“,可以解决偶发的瞬时的丢包。不过这种方法有个小副作用,那就是排队的包过多会增加处理网络包的延时。所以应该让内核处理网络包的速度更快一些更好,而不是让网络包傻傻地在 RingBuffer 中排队。我们后面会再介绍到 RSS ,它可以让更多的核来参与网络包接收。
建议6:减少内存拷贝
假如你要发送一个文件给另外一台机器上,那么比较基础的做法是先调用 read 把文件读出来,再调用 send 把数据把数据发出去。这样数据需要频繁地在内核态内存和用户态内存之间拷贝,如图

目前减少内存拷贝主要有两种方法,分别是使用 mmap 和 sendfile 两个系统调用。使用 mmap 系统调用的话,映射进来的这段地址空间的内存在用户态和内核态都是可以使用的。如果你发送数据是发的是 mmap 映射进来的数据,则内核直接就可以从地址空间中读取,这样就节约了一次从内核态到用户态的拷贝过程。

不过在 mmap 发送文件的方式里,系统调用的开销并没有减少,还是发生两次内核态和用户态的上下文切换。 如果你只是想把一个文件发送出去,而不关心它的内容,则可以调用另外一个做的更极致的系统调用 - sendfile。在这个系统调用里,彻底把读文件和发送文件给合并起来了,系统调用的开销又省了一次。再配合绝大多数网卡都支持的"分散-收集"(Scatter-gather)DMA 功能。可以直接从 PageCache 缓存区中 DMA 拷贝到网卡中,如图 9.8。这样绝大部分的 CPU 拷贝操作就都省去了。

建议7:使用 eBPF 绕开协议栈的本机 IO
如果你的业务中涉及到大量的本机网络 IO 可以考虑这个优化方案。本机网络 IO 和跨机 IO 比较起来,确实是节约了驱动上的一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、设备子系统整个走 了一个遍。连“驱动”程序都走了(虽然对于回环设备来说这个驱动只是一个纯软件的虚拟出来的东东)。
如果想用本机网络 IO,但是又不想频繁地在协议栈中绕来绕去。那么你可以试试 eBPF。使用 eBPF 的 sockmap 和 sk redirect 可以绕过 TCP/IP 协议栈,而被直接发送给接收端的 socket,业界已经有公司在这么做了。
建议8: 尽量少用 recvfrom 等进程阻塞的方式
在使用了 recvfrom 阻塞方式来接收 socket 上数据的时候。每次一个进程专⻔为了等一个 socket 上的数据就得被从 CPU 上拿下来。然后再换上另一个 进程。等到数据 ready 了,睡眠的进程又会被唤醒。总共两次进程上下文切换开销。如果我们服务器上需要有大量的用户请求需要处理,那就需要有很多的进程存在,而且不停地切换来切换去。这样的缺点有如下这么几个:
- 因为每个进程只能同时等待一条连接,所以需要大量的进程。
- 进程之间互相切换的时候需要消耗很多 CPU 周期,一次切换大约是 3 - 5 us 左右。
- 频繁的切换导致 L1、L2、L3 等高速缓存的效果大打折扣
大家可能以为这种网络 IO 模型很少见了。但其实在很多传统的客户端 SDK 中,比如 mysql、redis 和 kafka 仍然是沿用了这种方式。
建议9:使用成熟的网络库
使用 epoll 可以高效地管理海量的 socket。在服务器端。我们有各种成熟的网络库进行使用。这些网络库都对 epoll 使用了不同程度的封装。
首先第一个要给大家参考的是 Redis。老版本的 Redis 里单进程高效地使用 epoll 就能支持每秒数万 QPS 的高性能。如果你的服务是单进程的,可以参考 Redis 在网络 IO 这块的源码。
如果是多线程的,线程之间的分工有很多种模式。那么哪个线程负责等待读 IO 事件,那个线程负责处理用户请求,哪个线程又负责给用户写返回。根据分工的不同,又衍生出单 Reactor、多 Reactor、以及 Proactor 等多种模式。大家也不必头疼,只要理解了这些原理之后选择一个性能不错的网络库就可以了。比如 PHP 中的 Swoole、Golang 的 net 包、Java 中的 netty 、C++ 中的 Sogou Workflow 都封装的非常的不错。
建议10:使用 Kernel-ByPass 新技术
如果你的服务对网络要求确实特别特特别的高,而且各种优化措施也都用过了,那么现在还有终极优化大招 -- Kernel-ByPass 技术。
内核在接收网络包的时候要经过很⻓的收发路径。在这期间牵涉到很多内核组件之间的协同、协议栈的处理、以及内核态和用户态的拷贝和切换。 Kernel-ByPass 这类的技术方案就是绕开内核协议栈,自己在用户态来实现网络包的收发。这样不但避开了繁杂的内核协议栈处理,也减少了频繁了内核态用户态之间的拷贝和切换,性能将发挥到极致!
目前我所知道的方案有 SOLARFLARE 的软硬件方案、DPDK 等等。如果大家感兴趣,可以多去了解一下!

建议11:配置充足的端口范围
客户端在调用 connect 系统调用发起连接的时候,需要先选择一个可用的端口。内核在选用端口的时候,是采用从可用端口范围中某一个随机位置开始遍历的方式。如果端口不充足的话,内核可能需要循环撞很多次才能选上一个可用的。这也会导致花费更多的 CPU 周期在内部的哈希表查找以及可能的自旋锁等待上。因此不要等到端口用尽报错了才开始加大端口范围,而且应该一开始的时候就保持一个比较充足的值。
# vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 5000 65000
# sysctl -p //使配置生效如果端口加大了仍然不够用,那么可以考虑开启端口 reuse 和 recycle。这样端口在连接断开的时候就不需要等待 2MSL 的时间了,可以快速回收。开启这个参数之前需要保证 tcp_timestamps 是开启的。
# vi /etc/sysctl.conf
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tw_recycle = 1
# sysctl -p建议12:小心连接队列溢出
服务器端使用了两个连接队列来响应来自客户端的握手请求。这两个队列的长度是在服务器 listen 的时候就确定好了的。如果发生溢出,很可能会丢包。所以如果你的业务使用的是短连接且流量比较大,那么一定得学会观察这两个队列是否存在溢出的情况。因为一旦出现因为连接队列导致的握手问题,那么 TCP 连接耗时都是秒级以上了。
对于半连接队列, 有个简单的办法。那就是只要保证 tcp_syncookies 这个内核参数是 1 就能保证不会有因为半连接队列满而发生的丢包。
对于全连接队列来说,可以通过 netstat -s 来观察。netstat -s 可查看到当前系统全连接队列满导致的丢包统计。但该数字记录的是总丢包数,所以你需要再借助 watch 命令动态监控。
# watch 'netstat -s | grep overflowed'
160 times the listen queue of a socket overflowed //全连接队列满导致的丢包如果输出的数字在你监控的过程中变了,那说明当前服务器有因为全连接队列满而产生的丢包。你就需要加大你的全连接队列的⻓度了。全连接队列是应用程序调用 listen时传入的 backlog 以及内核参数 net.core.somaxconn 二者之中较小的那个。如果需要加大,可能两个参数都需要改。
如果你手头并没有服务器的权限,只是发现自己的客户端机连接某个 server 出现耗时长,想定位一下是否是因为握手队列的问题。那也有间接的办法,可以 tcpdump 抓包查看是否有 SYN 的 TCP Retransmission。如果有偶发的 TCP Retransmission, 那就说明对应的服务端连接队列可能有问题了。
建议13:减少握手重试
在 6.5 节我们看到如果握手发生异常,客户端或者服务端就会启动超时重传机制。这个超时重试的时间间隔是翻倍地增长的,1 秒、3 秒、7 秒、15 秒、31 秒、63 秒 ......。对于我们提供给用户直接访问的接口来说,重试第一次耗时 1 秒多已经是严重影响用户体验了。如果重试到第三次以后,很有可能某一个环节已经报错返回 504 了。所以在这种应用场景下,维护这么多的超时次数其实没有任何意义。倒不如把他们设置的小一些,尽早放弃。 其中客户端的 syn 重传次数由 tcp_syn_retries 控制,服务器半连接队列中的超时次数是由 tcp_synack_retries 来控制。把它们两个调成你想要的值。
建议14: 如果请求频繁,请弃用短连接改用长连接
如果你的服务器频繁请求某个 server,比如 redis 缓存。和建议 1 比起来,一个更好一点的方法是使用长连接。这样的好处有
1)节约了握手开销。短连接中每次请求都需要服务和缓存之间进行握手,这样每次都得让用户多等一个握手的时间开销。
2)规避了队列满的问题。前面我们看到当全连接或者半连接队列溢出的时候,服务器直接丢包。而客户端呢并不知情,所以傻傻地等 3 秒才会重试。要知道 tcp 本身并不是专门为互联网服务设计的。这个 3 秒的超时对于互联网用户的体验影响是致命的。
3)端口数不容易出问题。端连接中,在释放连接的时候,客户端使用的端口需要进入 TIME_WAIT 状态,等待 2 MSL的时间才能释放。所以如果连接频繁,端口数量很容易不够用。而长连接就固定使用那么几十上百个端口就够用了。
建议15:TIME_WAIT 的优化
很多线上服务如果使用了短连接的情况下,就会出现大量的 TIME_WAIT。
首先,我想说的是没有必要见到两三万个 TIME_WAIT 就恐慌的不行。从内存的⻆度来考虑,一条 TIME_WAIT 状态的连接仅仅是 0.5 KB 的内存而已。从端口占用的角度来说,确实是消耗掉了一个端口。但假如你下次再连接的是不同的 Server 的话,该端口仍然可以使用。只有在所有 TIME_WAIT 都聚集在和一个 Server 的连接上的时候才会有问题。
那怎么解决呢? 其实办法有很多。第一个办法是按上面建议开启端口 reuse 和 recycle。 第二个办法是限制 TIME_WAIT 状态的连接的最大数量。
# vi /etc/sysctl.conf
net.ipv4.tcp_max_tw_buckets = 32768
# sysctl -p如果再彻底一些,也可以干脆直接用⻓连接代替频繁的短连接。连接频率大大降低以后,自然也就没有 TIME_WAIT 的问题了。
操作系统
运行时间:对于虚拟服务器,正常运行时间是服务器运行的时间。监控主要是为了查看服务器是否经历了意外重启。
打开的句柄数:对于一般的应用来说(象Apache、系统进程)1024完全足够使用。但是像redis、KFK、mysql、oracle、java等单进程处理大量请求的应用来说,1024就有点捉襟见肘。如果单个进程打开的文件句柄数量超过了系统定义的值,就会提到“too many files open”的错误提示。














 6164
6164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









