







正则表达式中的小括号"()"。是代表分组的意思。 如果再其后面出现\1则是代表与第一个小括号中要匹配的内容相同。注意:\1必须与小括号配合使用
\1 \2
String string="sdfffdsjjcvnnnnnfkkk";
String regex="(.)\\1+";
String[] strings=string.split(regex);
for (int i = 0; i < strings.length; i++) {
System.out.print(strings[i]);
}
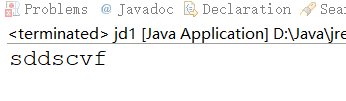
String string="sdfffdsjjcvnnnnnfkkk";
String regex="(.)\\1";
String[] strings=string.split(regex);
for (int i = 0; i < strings.length; i++) {
System.out.print(strings[i]);
}
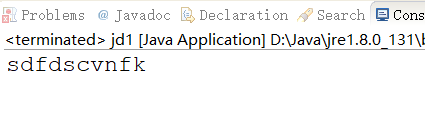
String regex="(...)\\1";
String string="abcabcacb";
String nString=string.replaceAll(regex, "");
System.out.println(nString);
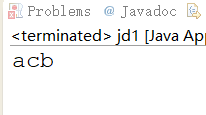
前面用括号捕获了一个子匹配,斜杠数字就表示和子匹配一样的内容,第一个子匹配就是\1,第二就是\2。
(?<=<(\w+)>).*(?=<\/\1>)
正则表达式看懂的最好方法就是一步步分开解析:
1)以 .*为分界,前面括号中的内容可以划分为 ?<=和 <(\w+)>,其中<(\w+)>表示匹配尖括号里面是字母、数字或下划线的内容[a-zA-Z_0-9],类似,外面还要加个括号是要实现分组;而?<=用到的是零宽断言语法,表示的是断定<(\w+)>后面有或没有内容,而且与内容的间隔宽度为零。
2)再看 .* 后面的部分,括号里面的内容可以分为 ‘?=’ 和 ‘<(\/\1>’,其中‘?=’用零宽断言表示匹配‘<(\/\1>’前面的部分,而对于‘<(\/\1>’,\/匹配/符号,类似,这里可能有些同学不太明白‘\1’是什么意思?这里用到的是捕获分组的思想,上述提到的‘<(\w+)>’外面加个小括号就表示一个分组,对于正则表达式的分组结果,索引 0表示匹配的整个内容,而1表示的是第1个子分组,所以这里的'\1'指向的就是前面的第一个分组‘<(\w+)>’,\2表示重复第2个子项,\n表示重复第n个子项;
3).* 就比较简单了,表示的是匹配 除了换行符意外的任意字符0次或多次。
综上,改表达式匹配的是类似html标签这种内容的,如<body>你好,正则!</body>
参考:请问这个「 (?<=<(\w+)>).*(?=</\1>) 」正则表达式是什么意思呢?
$1
String string="哇哇哇哇哇哇哇哇烦烦烦方法水水水水";
String string2=string.replaceAll("(.)\\1+", "$1");
System.out.println(string2);
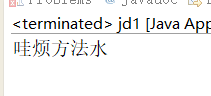
$1,$2…是表示的小括号里的内容
$1是第一个小括号里的 ,$2是第2个小括号里的
比如 /gai([\w]+?)over([\d]+)/
匹配 gainover123
$1= 括号里的 n
$2= 第2个括号里的 123
Pattern Matcher
public static void main(String[] args) {
String string="我的手机号18837489098,13488379,12374638965";
String regex="1[2387]\\d{9}";
Pattern p=Pattern.compile(regex);
Matcher m=p.matcher(string);
while (m.find()) {//必须先find才能group
System.out.println(m.group());
}















 3847
3847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









