






什么是NoSQL
NoSQL(Not Only SQL)即不仅仅是SQL,泛指非关系型的数据库,它可以作为关系型数据库的良好补充。随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。
为什么会出现NoSQL技术
随着互联网web2.0网站的兴起,传统的关系型数据库在应付web2.0网站,特别是超大规模和高并发的SNS(Social Networking Services 社交网络服务)类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题:
- High performance - 数据的高并发读写
web2.0网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用动态页面静态化技术,因此数据库并发负载非常高,往往要达到每秒上万次读写请求。而关系型数据库应付上万次SQL查询还勉强可以承受,但是应付上万次SQL写数据请求,硬盘IO就已经无法承受了。其实对于普通的BBS网站,往往也存在对高并发写请求的需求,例如网站的实时统计在线用户状态,记录热门帖子的点击次数,投票计数等,因此这是一个相当普遍的需求。
- Huge Storage - 海量数据的高效率存储和访问
类似Facebook,twitter,Friendfeed这样的SNS网站,每天用户产生海量的用户动态,如Friendfeed一个月就达到了2.5亿条用户动态。对于关系型数据库而言,在一张2.5亿条记录的表里面进行SQL查询,效率是极其低下乃至不可忍受的。同样对于大型web网站的用户登录系统,如腾讯、阿里、网易等动辄数以亿计的帐号,使用关系型数据库很难应付。
- High Scalability & High Availability - 数据库的高扩展和高可用
在基于web的架构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,你的数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移,因此需要数据库具有可扩展和高可用的特性。
总结:传统的关系型数据库只能存储结构化数据,对于非结构化的数据支持不够完善。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。

NoSQL的类别
-
键值(Key-Value)存储数据库
说明:这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。
Key/Value模型对于IT系统来说优势在于简单、易部署。
应用:内容缓存,主要用于处理大量数据的高访问负载。
产品:Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
优势:快速查询
劣势:存储的数据缺少结构化
-
列存储数据库
说明:这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列,这些列是由列家族来安排的。
应用:分布式文件系统
产品:Cassandra,HBase,Riak
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限
-
文档型数据库
说明:该类型的数据模型 是版本化的文档,半结构化的文档以特定的格式存储,如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。
应用:Web应用
产品:CouchDB,MongoDB
优势:数据结构要求不严格
劣势:查询性能不高,且缺乏统一的查询语法
-
图形(Graph)数据库
说明:图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST格式的数据接口或者查询API。
应用:社交网络
产品: Neo4j,InfoGrid,Infinite Graph
优势:利用图结构相关算法
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案
NoSQL适应场景
- 数据模型比较简单
- 需要灵活性更强的IT系统
- 对数据库性能要求较高
- 不需要高度的数据一致性
- 对于给定key,比较容易映射复杂的环境
- 取最新的N个数据(如排行榜)
- 数据缓存
在分布式数据库中CAP原理
传统的ACID是什么
关系型数据库遵循ACID规则,事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
-
A (Atomicity) 原子性
指事务里的所有操作要么都成功,要么都失败。事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
-
C (Consistency) 一致性
指数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
-
I (Isolation) 隔离性
指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
-
D (Durability) 持久性
是指一旦事务提交后,它所做的修改将会永久的保存在数据库中,即使出现宕机也不会丢失。
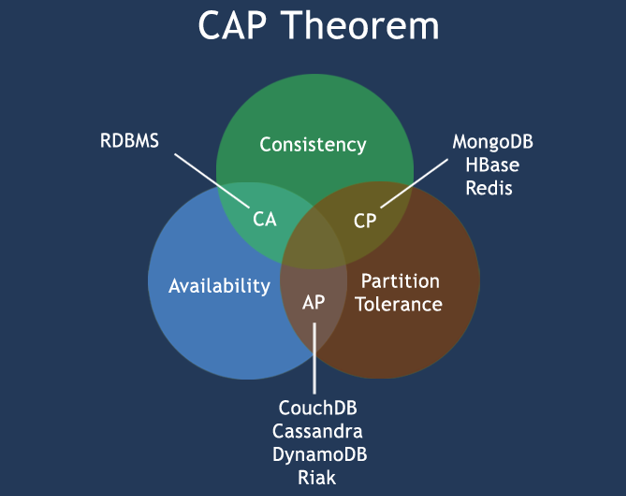
CAP
- Consistency(强一致性)
- Availability(可用性)
- Partition tolerance(分区容错性)
CAP理论是指在分布式存储系统中,最多只能实现上面的两点。由于当前的网络硬件存在延迟丢包等问题,所以分区容忍性是我们必须要实现的。所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
- CA 传统Oracle数据库
- AP 大多数网站架构的选择
- CP Redis、Mongodb
注意:在做分布式架构的时候必须做出取舍。一致性和可用性之间取一个平衡。对于大多数web应用,其实并不需要强一致性。因此牺牲C换取P,这是目前分布式数据库产品的方向。
经典CAP图
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
什么是BASE
BASE就是为了解决关系数据库强一致性引起的问题而导致可用性降低而提出的解决方案。BASE其实是下面三个术语的缩写:
基本可用(Basically Available)
软状态(Soft state)
最终一致(Eventually consistent)
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法。
什么是Redis
2008年,意大利的一家创业公司Merzia推出了一款基于MySQL的网站实时统计系统LLOOGG,然而没过多久该公司的创始人 Salvatore Sanfilippo便开始对MySQL的性能感到失望,于是他决定亲自为LLOOGG量身定做一个数据库,并于2009年开发完成,这个数据库就是Redis。不过Salvatore Sanfilippo并不满足只将Redis用于LLOOGG这一款产品,而是希望更多的人使用它,于是在同一年Salvatore Sanfilippo将Redis开源发布,并开始和Redis的另一名主要的代码贡献者Pieter Noordhuis一起继续着Redis的开发,直到今天。
Salvatore Sanfilippo自己也没有想到,短短的几年时间,Redis就拥有了庞大的用户群体。Hacker News在2012年发布了一份数据库的使用情况调查,结果显示有近12%的公司在使用Redis。国内如新浪微博、街旁网、知乎,国外如GitHub、Stack Overflow、Flickr、暴雪和Instagram,都是Redis的用户。
VMware公司从2010年开始赞助Redis的开发, Salvatore Sanfilippo和Pieter Noordhuis也分别在3月和5月加入VMware,全职开发Redis。【本部分内容取自《REDIS入门指南》】
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Redis(REmote Dctionary Server 远程字典服务器),是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(key/value)分布式内存数据库,基于内存运行,并支持持久化的NoSQL数据库,是当前最热门的NoSQL数据库之一, 也被人们称为数据结构服务器。
Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
Redis是一个开源的高性能键值对(Key-Value)数据库。它通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
- 字符串类型
- 散列类型
- 列表类型
- 集合类型
- 有序集合类型
学习参考网站:https://www.redis.net.cn/
Redis能干什么
- 内存存储和持久化:redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务
- 取最新N个数据的操作,如:可以将最新的10条评论的ID放在Redis的List集合里面
- 模拟类似于HttpSession这种需要设定过期时间的功能
- 发布、订阅消息系统
- 定时器、计数器
Redis的特点
- 性能极高:Redis 读的速度是 110000 次 /s,写的速度是 81000 次 /s 。
- 丰富的数据类型:Redis 支持二进制案例的 String,List,Hash,Set及 ZSet 数据类型操作。
- 原子性:Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
- 数据持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用
- 其他特性:Redis 还支持 publish/subscribe 通知,key 过期等特性。
Redis 提供的API支持:C、C++、C#、Clojure、Java、JavaScript、Lua、PHP、Python、Ruby、Go、Scala、Perl等多种语言。
Redis与memcached对比
-
共同点
无论是Memcached还是Redis底层都是使用C语言编写,都是基于key-value,存储的数据都是在内存中。
-
不同点
Memcached支持的数据类型比较简单(String,Object);Redis 支持的数据类型比较丰富。
Memcached默认一个值的最大存储不能超过1M;Redis一个值的最大存储1G。
Memcached中存储的数据不能持久化,一旦断电数据丢失;Redis中存储的数据可以持久化。
Memcached是多线程,支持并发访问;Redis是单线程,不支持并发访问。
Memcached自身不支持集群环境;Redis从3.0版本之后自身开始提供集群环境支持。

















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









