






PS:本博客均采用上文字下图片的方式进行描述,深入到源码进行讲解,如有问题,欢迎提出,本博客参考和整合了某站视频和一些博客的论述,希望你能从这篇博客中学习到什么。
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射,键值对的集合,源码中每个节点用Node<K,V>表示,Node是一个内部类,这里的key为键,value为值,next指向下一个元素,可以看出HashMap中的元素不是一个单纯的键值对,还包含下一个元素的引用。
我们知道,HashMap是数组+链表+红黑树的数据结构,所谓的扩容就是对数组的扩容,数组上的元素包含链表结点Node,以及在一定条件下转为的红黑树结点TreeNode,下图就是正常情况下的HashMap:
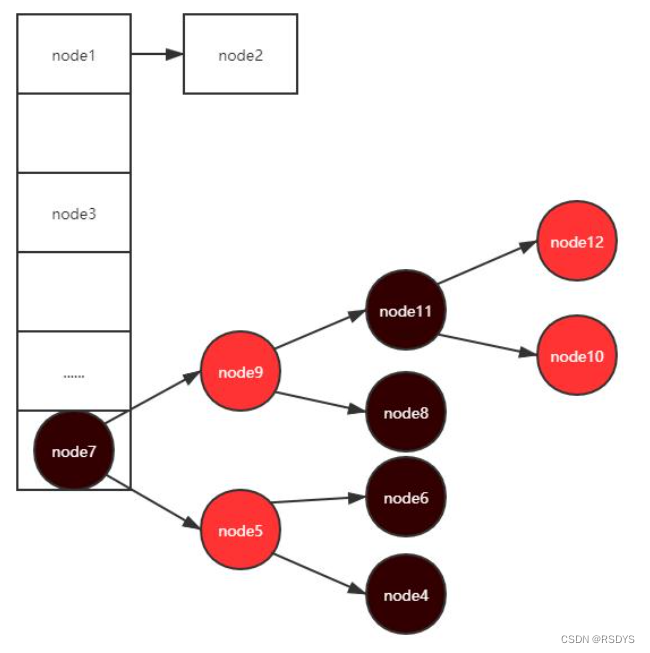
流程是要走一下的,这里将不多做HashMap的赘述,直接上源码:
先来看看一些HashMap定义的默认参数:

首先,当我们new一个HashMap实例,调用它的默认无参构造函数时,下图1.2是HashMap的构造函数,我们会发现,里面只有一条语句,就是设置了一个加载因子为默认的0.75,其他什么事也没有干,你构造的时候hashmap不会进行初始化,当你调用put函数进行插入时,HashMap才会进入resize方法进行初始化,过程包括赋初始默认值(数组长度16)和默认阈值(数组长度 * 默认加载因子 = 12)如下图1.1,这就是HashMap的懒加载机制。

图1.1

图1.2
于是,当我们调用put方法开始插入数据时,传入key键和value值,此时我们进入put方法,首先会判断table表是否为空,为空则调用resize方法进行初始化。
在初始化时,通过传入的key值在方法hashCode方法生成哈希值,然后在扰动函数hash中(下图1.3)对得到哈希值进行二次加工,这里为什么要进行二次加工呢?因为HashMap的散列性,我们要将元素较为均匀的放在数组上,尽量的减少hash冲突,而得到的hash值是位数较高的,在后面和数组长度相与的操作中高位基本上使用不到(因为数组长度一般不会很大,二进制位数和哈希值的位数相差很大),所以我们要对哈希值的高低16位进行异或运算,让哈希值的高位也参与到运算之中,更加保持HashMap的散列性,这里生成的就是加工后的hash值了。

图1.3
得到hash值后,对传入的Entry对象包装成链表Node,图1.4是Node类的字段,包含传入的key,value值,生成的hash值,和链表的标志next字段。
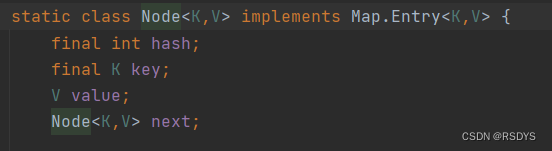
图1.4
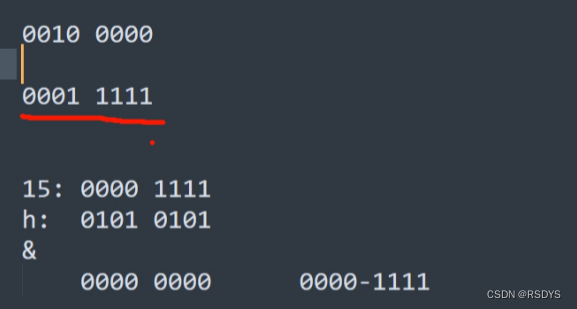
万事俱备,在完成这些后,我们就要要知道将这个结点插入到什么位置,如下图,这里就将最后的hash值和减一后的数组长度进行想与运算,那么问题来了,为什么要减掉1呢,而且为什么是与运算??这里举一个例子,假如数组长度就是默认的16,减一就是15,通过和15进行与运算计算出下标并且加入数组,因为要保证0-15比较均匀的存数,所以15保证了二进制位都为1,与哈希值相与就可以保证的出来的数在0-15的范围内且均匀分布,如果是16的话,0001 0000,相与后全填到一个位置上了。所以数组容量都是二的次方数。在此运算后得到的数字就是要插入的下标位置,将此结点插入数组对应的下标就可以了。
在插入完后,生成完新的结点Node,修改次数modCount + 1,判断size是否大于阈值,不大于则不扩容。

此处值得一提,jdk1.7利用的是头插法插入数据,因为直接插在链表头部不用遍历链表,很高效,但是在1.8中加入了红黑树,插入节点时就使用尾插法插入,因为需要遍历链表,当链表的结点数到一定阈值时,会转化为红黑树,这个下面再讲。
在put元素时,还有很多种情况,比如说put的元素得到的hash值在经过与运算后得到的数组下标上已经有元素了,也就是产生了hash冲突,如下图2.1,会对这个数组下标上的链表的结点一个个进行判断,如果key值相等或者key值进行equals方法的比对相同,就会认为是同一个元素(结点),不会进行插入操作,在后面会将这个元素的value值替换掉原来的元素的value值(图2.2),并且返回被替换掉的结点的value值。

图2.1

图2.2
如果找不到key相同的结点,就会进行插入操作,遍历这个位置的链表,到末尾插入这个加上这个结点。
当它的长度超过8时,也就是下图从0开始遍历的binCount到7(红黑树阈值8 - 1)时,链表中已经有了8个结点,此时还没进行++操作,所以实际上加上这个新的结点已经有9 个结点了,此时会进入treeifyBin方法尝试将这个链表转化为红黑树,下图2.3。
但是,这不是唯一一个让链表转化为红黑树的限制因素,在进入treeifyBin方法时,先判断数组容量是否小于64,如果小于的话,就不会转红黑树,会去调用扩容函数resize,在数组长度大于64时,才会真正的转化为红黑树,如下图2.4。
此处我们可以知道,resize是扩容函数,但是他之前也负责过数组的初始化。
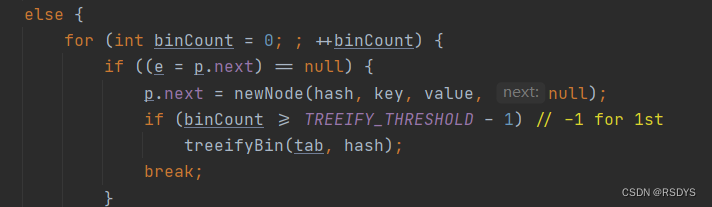
图2.3

图2.4
其实在找到要插入元素hash对应的数组位置后,在生成结点前时,还有一层判断,就是判断当前位置是不是一颗红黑树,也就是用instanceof判断这个位置的结点的类型是否是TreeNode类型(图2.5),也就是判断这个数组下标位是不是颗红黑树,如果是红黑树的话,进入红黑树的插入函数,不是的话,就当成普通的Node链表来插入。
如下图2.6是TreeNode类(红黑树)的字段,不光有左右结点left和right,还有父节点parent,其实还继承了Node结点的next,所以也是一个双向链表,parent字段用于红黑树的旋转等操作,还有一个标志当前结点为红还是黑的red字段。

图2.5
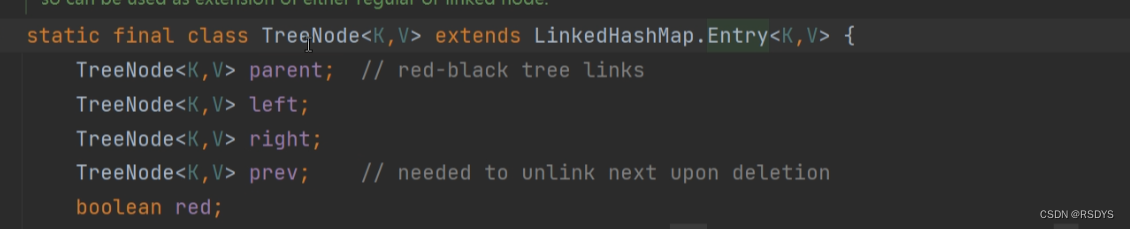
图2.6
此处划分
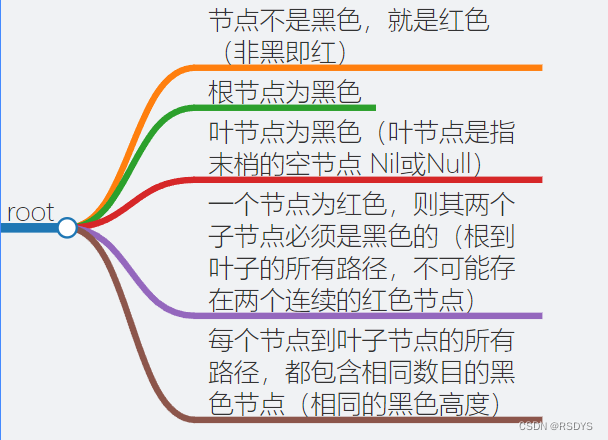
简单介绍一下红黑树背景吧,首先链表查找的时间复杂度是O(N),我们要进行不断的遍历,二叉树在极端情况下就相当于是一个链表,最坏时间复杂度也是O(N),查找效率很低,这时就引入了VAL平衡树,在左右子树深度差不大于1的情况下一直进行旋转调整,最差的时间复杂度就优化为了O(LogN),但是平衡条件比较苛刻,插入数据就很大概率会破坏掉平衡,然后就出现了红黑树,红黑树的条件如下图,相对于VAL树来说平衡条件不是很苛刻,可以相差在两倍以内,降低了对旋转的要求,从而提高了性能。

如下图,是红黑树的插入删除的变换过程,有意者可以去深入探究,本篇博客不多做赘述(这是人看的? ?.?):
言归正传,前面我们引到了扩容,在扩容时,要先判断是否大于最大值,每个节点会根据其哈希值和数组长度重新计算位置,当经过位移,红黑树的节点数小于等于6时,会将红黑树退化成链表。
而我们数组的扩容只会将数组的容量扩容成二的次方数,也就是说每次扩容都是进行翻倍,具体实现就是将二进制数左移一位(0001 0000 到 0010 0000 就是从16扩容到了32),为什么每次扩容后的容量都是2的次方数呢,因为Hashmap计算存储位置时,使用了(n - 1) & hash。只有当容量n为2的幂次方,n-1的二进制会全为1(0001 0000为16,0000 1111为15,保证0-15位上都有可能插入,如果是0000 1110,则相与后永远也得不到1,永远也插入不到下标为1的位置),位运算时可以充分散列,避免不必要的哈希冲突,所以扩容必须2倍就是为了维持容量始终为2的幂次方。
总结扩容就是生成了一个新的数组,这个数组的长度为老数组的两倍,然后我们要重新通过(n - 1) & hash来计算每个结点在新数组的位置!!!
深挖细节:jdk1.7在扩容后会一个个遍历每个节点,对各个结点进行转移操作,利用两个循环完成,比较暴力,jdk1.8优化了这种操作:
重点:
这里先介绍一下jdk1.8进行优化的神奇操作:
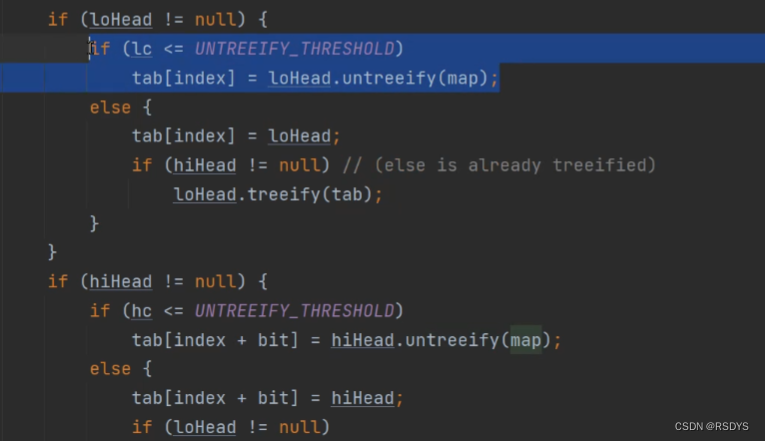
前面提到jdk1.8没有像之前那样对老数组的所有结点都一个个的进行遍历和移动,他采取了一种将链表划分成用高位链表和低位链表两个链表的方式移动到新数组,之前提到,在数组扩容后容量为之前的两倍,那么假如说是0001 0000 扩容到 0010 0000 ,那么他们的计算存储位置时用到的(n - 1) & hash中的n-1就从 0000 1111变到0001 1111,所以某个结点的hash与新的数组的 0001 1111相与时,当hash的第5位为0时,那么它和老数组的0000 1111相与是没有区别的,也就是说得出来的数组下标是一样的,那么这个结点只需要移动到新数组对应老数组的下标处即可,而当hash第5位为1时,和新数组相与后得到的结果比和老数组相与多出来一个0001 0000,也就是多出来一个老数组的长度,那么就移动到在下标上加上老数组长度的位置。
所以,要移动的结点现在看来就只有两种,一种是移动后下标不变的,还有一种是移动后下标要加上老数组长度的。
每个结点新位置计算的方法讲完了,但是优化在哪里?不还是一个个结点的遍历吗?其实遍历确实都需要,但是优化就体现在了移动操作上,上面提到,1.8用高低位链表来移动,那么我们只需要创造两个链表,一个存储下标不需要变换的结点,把它叫做低位链表,另一个存储下标要加上老数组长度的结点,我们就把它叫做高位链表,在遍历完这个老数组对应下标上的链表时,就将高低位链表也填充完毕了,这时只需要将低位链表头结点的引用放到新数组的对应下标,高位表头结点的引用放到新数组的对应下标加上老数组长度的位置即可。
所以,在移动上的优化就让每个老数组下标上的链表最多只需要移动两个链表的引用即可完成所有结点的移动,不必一个个移动结点,大大提高了效率。
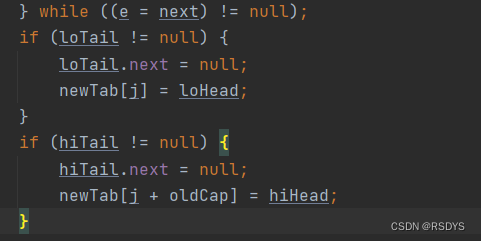
所以jdk1.8把元素的移动情况分为了如下四种:
1. 数组位置上只有一个Node结点(也就是说这个地方只有一个结点),也就是这个头结点的next为null,通过将其的哈希值和新数组长度相与计算在新数组的位置,并且直接转移。
2. next上是一个Node(也就是说这个地方有一个链表),利用两个链表,高位链表和低位链表,一个个的遍历Node,判断他是在高位还是低位,高位的都进入高位链表,低位的都进入低位链表,然后判断是否有高位链表,有则放到新数组的:(老数组下标+老数组长度)的位置,有低位链表则放入新数组的:(老数组下标)的位置。
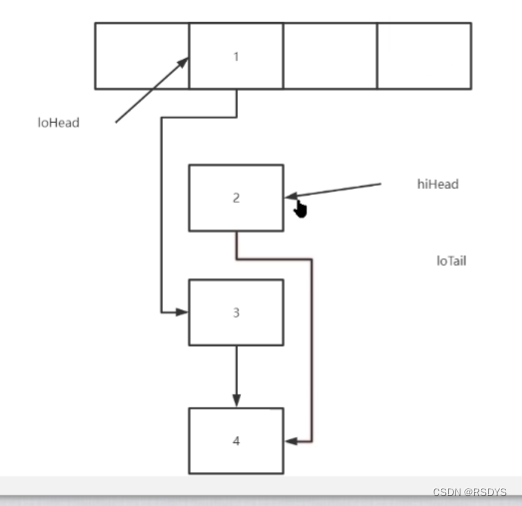

3. next不为null,且结点是TreeNode(也就是说这个位置有一颗红黑树),调用split方法,一开始也是遍历链表,划分高低位链表,利用lc和hc计算高低位的个数,当高位链表或者低位链表为空,也就是全是高位(或者全是低位),那就没必要去划分了,直接将根结点的引用写在新数组的高位(低位)处即可。如果高低位链表都有结点,那就要进行下述的判断了,当低位或者高位的节点数小于等于6,就会将其退化成链表,放到新数组上。


4. 数组位置为null。
最后一提,get方法在实现时也是同理,先通过key的HashCode找到对应下标,然后一个个比对key,得到它的value。
以下再做点补充:
当用带参构造函数构造Map时,假如你定的长度为n时,他会去创建一个比n大的2的次方数。
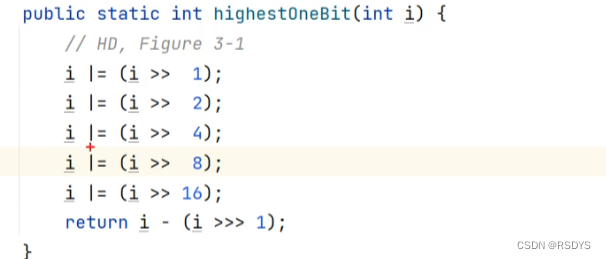
下图这个函数获取的是比传入数字小的2的次方数,进行位运算。

理论上再通过上述的方法获得大于传入数字的2的次方数,得到小的次方数,左移一位,也就是翻倍,就可以得到目标了,不过实现起来并不是这样的,是直接先对传进来的数进行操作,然后传入highestOneBit方法直接得到目标数,例如传入10,先将其-1后翻倍,得到18,再用函数获取比18小的最大2的次方数。
这篇博客没有用到任何的代码块,全都是截图,就是希望各位在看博客时可以自己深入一下源码,毕竟看过源码的人是不会来看我的博客的,自己写一个put函数,通过debug来一步步的深入源码,你会收获很多。ctrl+鼠标左键进入方法,ctrl+alt+←回退到之前的方法,去尝试吧,少年。
至此,
基本上就完成了本博客的论述,
非常感谢你可以坚持看到这里,勇士,在总结这篇博客时,
我也收获到了许多,虽然很多东西说的不够全面,我也希望你能从这里学到一些东西,哪怕是一点点,这篇博客就很有价值了,如果你对博客有什么意见或者建议和纠错,欢迎来找我讨论,一起进步吧。















 7841
7841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









