







=================================================================
除了网络搜索,我们还在模型中引入了几个新组件,以进一步改进最终模型。我们在网络的开头和结尾重新设计了计算成本高的层。我们还引入了一种新的非线性,h-swish,它是最近 swish 非线性的修改版本,计算速度更快,量化更友好。
一旦通过架构搜索找到模型,我们观察到一些最后一层以及一些较早的层比其他层更昂贵。我们建议对架构进行一些修改,以减少这些慢层的延迟,同时保持准确性。这些修改超出了当前搜索空间的范围。
第一个修改修改了网络的最后几层如何交互,以便更有效地生成最终特征。当前基于 MobileNetV2 的倒置瓶颈结构和变体的模型使用 1x1 卷积作为最后一层,以便扩展到更高维的特征空间。该层对于具有丰富的预测特征至关重要。然而,这是以额外的延迟为代价的。
为了减少延迟并保留高维特征,我们将这一层移到最终的平均池化之后。最后一组特征现在以 1x1 空间分辨率而不是 7x7 空间分辨率计算。这种设计选择的结果是特征的计算在计算和延迟方面变得几乎免费。
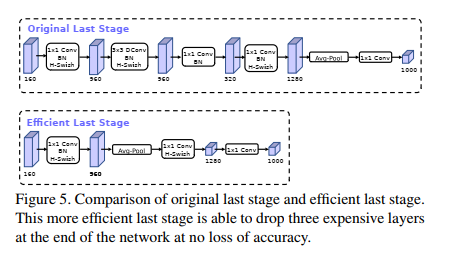
一旦降低了该特征生成层的成本,就不再需要先前的瓶颈投影层来减少计算量。这一观察使我们能够移除先前瓶颈层中的投影和过滤层,进一步降低计算复杂度。原始和优化的最后阶段可以在图 5 中看到。高效的最后阶段将延迟减少了 7 毫秒,这是运行时间的 11%,并且减少了 3000 万次 MAdd 的操作数量,几乎没有损失准确性。第 6 节包含详细结果。
在 [36, 13, 16] 中,引入了一种称为 swish 的非线性,当用作 ReLU 的替代品时,它显着提高了神经网络的准确性。 非线性定义为
swish x = x ⋅ σ ( x ) \operatorname{swish} x=x \cdot \sigma(x) swishx=x⋅σ(x)
虽然这种非线性提高了准确性,但它在嵌入式环境中具有非零成本,因为在移动设备上计算 sigmoid 函数的成本要高得多。 我们以两种方式处理这个问题。
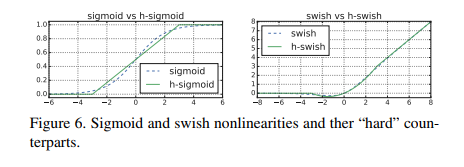
- 我们用它的分段线性硬模拟替换 sigmoid 函数: ReLU6 ( x + 3 ) 6 \frac{\text { ReLU6 }(x+3)}{6} 6 ReLU6 (x+3),类似于 [11, 44]。 细微的区别是我们使用 ReLU6 而不是自定义裁剪常量。 同样,swish 的硬版本变成
h-swish [ x ] = x ReLU 6 ( x + 3 ) 6 \text { h-swish }[x]=x \frac{\operatorname{ReLU} 6(x+3)}{6} h-swish [x]=x6ReLU6(x+3)
最近在 [2] 中也提出了类似版本的 hard-swish。 sigmoid 和 swish 非线性的软和硬版本的比较如图 6 所示。我们选择常数的动机是简单,并且与原始平滑版本很好匹配。 在我们的实验中,我们发现所有这些功能的硬版本在准确性上没有明显差异,但从部署的角度来看具有多种优势。 首先,ReLU6 的优化实现几乎可以在所有软件和硬件框架上使用。 其次,在量化模式下,它消除了由近似 sigmoid 的不同实现引起的潜在数值精度损失。 最后,在实践中,h-swish 可以实现为分段函数,以减少内存访问次数,从而大幅降低延迟成本。
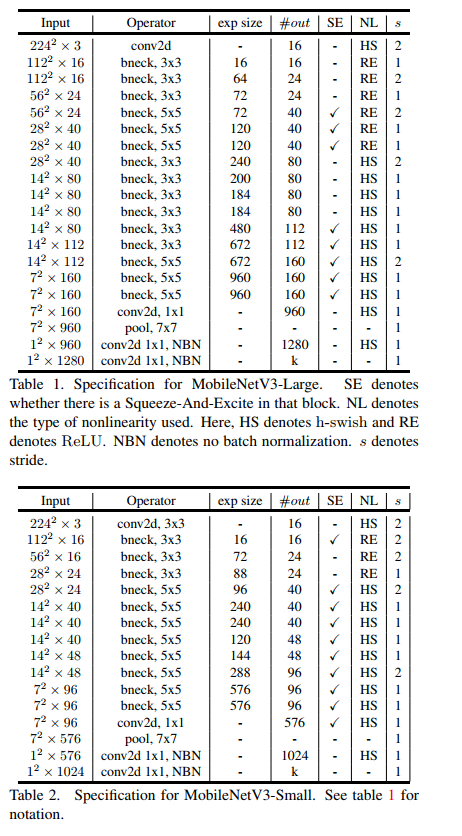
- 随着我们深入网络,应用非线性的成本会降低,因为每次分辨率下降时,每一层的激活内存通常都会减半。 顺便说一句,我们发现大多数好处都是通过仅在更深层使用它们来实现的。 因此,在我们的架构中,我们只在模型的后半部分使用 h-swish。 我们参考表 1 和表 2 了解精确布局。
即使有这些优化,h-swish 仍然会引入一些延迟成本。 然而,正如我们在第 6 节中所展示的,当使用基于分段函数的优化实现时,对准确性和延迟的净影响是积极的,没有优化和实质性。
在 [43] 中,squeeze-and-excite 瓶颈的大小是相对于卷积瓶颈的大小。 相反,我们将它们全部替换为固定为扩展层通道数的 1/4。 我们发现这样做可以提高准确性,同时适度增加参数数量,并且没有明显的延迟成本。
MobileNetV3 被定义为两个模型:MobileNetV3-Large 和 MobileNetV3-Small。 这些模型分别针对高资源和低资源用例。 这些模型是通过应用平台感知 NAS 和 NetAdapt 进行网络搜索并结合本节中定义的网络改进来创建的。 有关我们网络的完整规格,请参见表 1 和表 2。
===============================================================
我们展示了实验结果来证明新的 MobileNetV3 模型的有效性。 我们报告分类、检测和分割的结果。 我们还报告了各种消融研究,以阐明各种设计决策的影响。
正如已经成为标准的那样,我们将 ImageNet[38] 用于我们所有的分类实验,并将准确性与各种资源使用量度进行比较,例如延迟和乘法相加 (MAdds)。
6.1.1 训练设置
我们使用具有 0.9 动量的标准 tensorflow RMSPropOptimizer 在 4x4 TPU Pod [24] 上使用同步训练设置来训练我们的模型。 我们使用 0.1 的初始学习率,批量大小为 4096(每个芯片 128 张图像),每 3 个 epoch 的学习率衰减率为 0.01。 我们使用 0.8 的 dropout,l2 权重衰减 1e-5 以及与 Inception [42] 相同的图像预处理。 最后我们使用衰减为 0.9999 的指数移动平均线。 我们所有的卷积层都使用平均衰减为 0.99 的批量归一化层。
6.1.2 测量设置
为了测量延迟,我们使用标准的 Google Pixel 手机并通过标准的 TFLite Benchmark Tool 运行所有网络。 我们在所有测量中都使用单线程大内核。 我们不报告多核推理时间,因为我们发现这种设置对于移动应用程序不太实用。 我们为 tensorflow lite 贡献了一个原子 h-swish 运算符,现在它在最新版本中是默认的。 我们在图 9 上展示了优化的 h-swish 的影响。

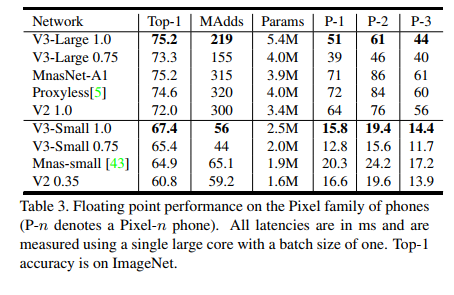
如图 1 所示,我们的模型优于 MnasNet [43]、ProxylessNas [5] 和 MobileNetV2 [39] 等当前最先进的模型。 我们在表 3 中报告了不同 Pixel 手机上的浮点性能。我们在表 4 中包含了量化结果。
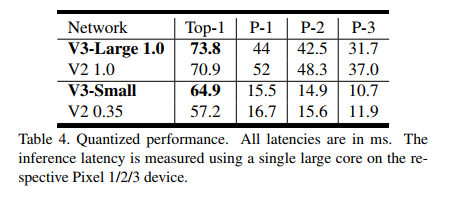
在图 7 中,我们展示了 MobileNetV3 性能权衡作为乘数和分辨率的函数。 请注意,MobileNetV3-Small 的性能如何优于 MobileNetV3-Large,其乘数缩放以匹配近 3% 的性能。 另一方面,分辨率提供了比乘数更好的折衷。 但是,需要注意的是,分辨率往往是由问题决定的(例如分割和检测问题通常需要更高的分辨率),因此不能总是用作可调参数。
6.2.1 消融研究
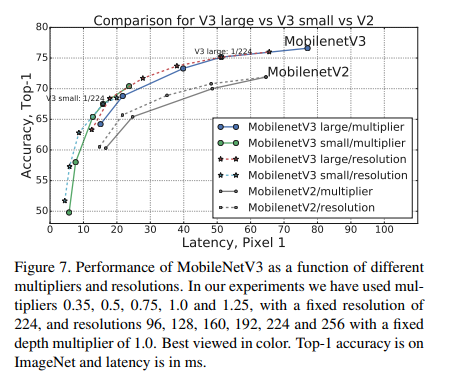
非线性的影响在表 5 中,我们研究了插入 h-swish 非线性的位置的选择,以及使用优化实现相对于简单实现的改进。 可以看出,使用 h-swish 的优化实现节省了 6ms(超过 10% 的运行时间)。 与传统 ReLU 相比,优化后的 h-swish 仅增加了 1ms。

图 8 显示了基于非线性选择和网络宽度的有效边界。 MobileNetV3 在网络中间使用了 h-swish,明显主导了 ReLU。 有趣的是,在整个网络中加入 h-swish 比扩大网络的插值前沿略好。
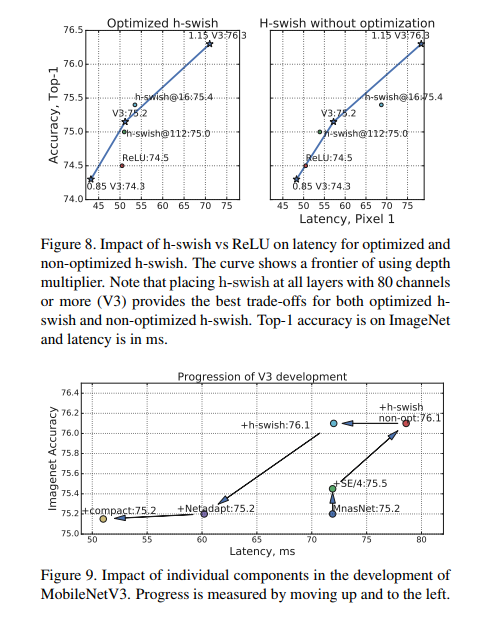
其他组件的影响在图 9 中,我们展示了不同组件的引入是如何沿着延迟/准确度曲线移动的。
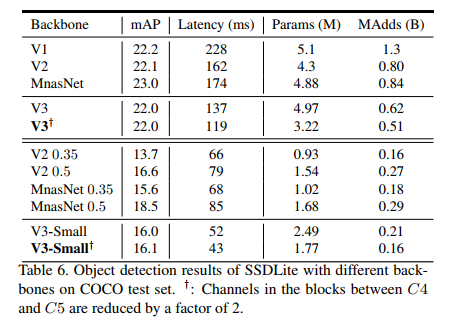
我们使用 MobileNetV3 作为 SSDLite [39] 中骨干特征提取器的替代品,并与 COCO 数据集 [26] 上的其他骨干网络进行比较。
在 MobileNetV2 [39] 之后,我们将 SSDLite 的第一层附加到输出步幅为 16 的最后一个特征提取器层,并将 SSDLite 的第二层附加到输出步幅为 32 的最后一个特征提取器层。 在检测文献中,我们将这两个特征提取层分别称为 C4 和 C5。 对于 MobileNetV3-Large,C4 是第 13 个瓶颈块的扩展层。 对于 MobileNetV3-Small,C4 是第 9 个瓶颈块的扩展层。 对于这两个网络,C5 是池化之前的层。
我们另外将 C4 和 C5 之间的所有特征层的通道数减少了 2。这是因为 MobileNetV3 的最后几层被调整为输出 1000 个类,这在转移到具有 90 个类的 COCO 时可能是多余的。
最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)

术停滞不前!**
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)
[外链图片转存中…(img-LQPWai5X-1710885619901)]















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









