







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
pip install selenium
2️⃣安装ChromeDriver驱动:
(根据浏览器版本安装对应的浏览器驱动)
步骤:
-
获取当前浏览器版本(谷歌为例:帮助里面)
-
访问下载地址 下载对应的driver版本(注意你的浏览器版本和driver驱动版本没有一一对应的版本号,请前往ChromeDriver官网查看确认自己浏览器对应的驱动版本哦!)
-
解压,获取可执行文件:
windows为chromedriver.exe
linux/mac为chromedriver
- chromedriver环境变量配置:
①Windows环境下,需要将chromedriver.exe所在的目录设置为path环境变量中的路径/直接将chromedriver.exe文件拖到Python的Scripts目录下(建议这样做!);
②linux/mac环境下,将chromedriver所在的目录设置到系统的PATH环境值中。
- 验证安装——CMD窗口中输入chromedriver出现如下图所示界面:

1️⃣作用:
-
自动化测试,通过它我们可以写出自动化程序,模拟浏览器里操作web界面。 比如点击界面按钮,在文本框中输入文字 等操作。
-
获取信息——从web界面获取信息。 比如招聘网站职位信息,财经网站股票价格信息 等等,然后用程序进行分析处理。
2️⃣工作原理:
(开发使用有头浏览器,部署使用无界面浏览器无界面浏览器phantomjs官方下载地址)。
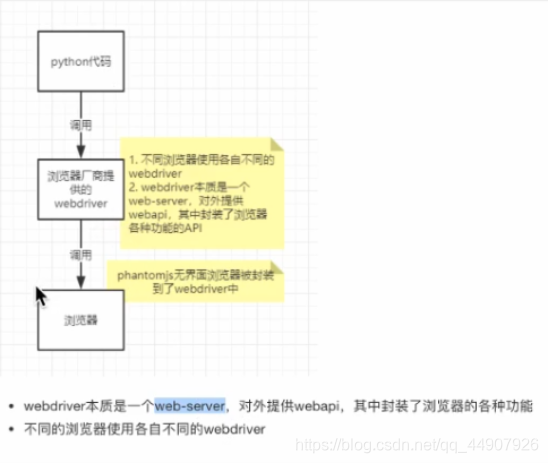
注意事项:
| 新版本的Selenium已经不再支持phantomjs,原作者也已经放弃维护该项目了。还有在做爬虫的时候尽量不要用这种方法,Selenium+浏览器的组合速度慢,应付不了数据量比较大的爬取以及并发爬取。并且很吃电脑资源。 |
⛔️①上代码:
from selenium import webdriver # 控制浏览器的模块
import time # 加入睡眠,不然运行的太快了录屏效果不行!
声明浏览器对象——如果是火狐浏览器的话:driver = webdriver.Firefos()
driver = webdriver.Chrome() # 获取chrome控制对象——webdriver对象
1.向一个url发起请求
driver.get(‘http://www.baidu.com’)
time.sleep(1)
2.定位到搜索框标签
input_tag = driver.find_element_by_id(‘kw’)
3.往搜索框中输入搜索内容
input_tag.send_keys(‘猫咪图片’)
4.定位到百度一下的搜索图标
submit_tag = driver.find_element_by_id(‘su’)
time.sleep(1)
5.单击搜索图标
submit_tag.click()
time.sleep(5)
6.一定要退出!不退出会有残留进程!!!
driver.quit()
⛔️②代码解析:
-
webdriver.Chrome() 如果没有将驱动加入环境变量,则需要在Chrome中加入executable参数,值为下载好的chromedriver文件路径;
-
driver.find_element_by_id(‘kw’).send_keys(‘猫咪图片’) 定位id属性值是‘kw’的标签,并向其中输入字符串‘猫咪图片’;
-
driver.find_element_by_id(‘su’).click()定位id属性值是su的标签;
-
click函数的作用是:触发标签的js的click事件。
⛔️③效果展示:
selenium简单使用!
===================================================================================
🚩(1)骚操作及代码实现:
| 浏览器操作 | 代码 |
| — | — |
| 最大化浏览器 | driver.maximize_window() |
| 刷新 | driver.refresh() |
| 后退 | driver.back() |
| 前进 | driver.forward() |
| 设置浏览器大小 | driver.set_window_size(300,300) |
| 设置浏览器位置 | driver.set_window_position(300,200) |
| 关闭浏览器单个窗口,如果只有一个标签页则关闭整个浏览器 | driver.close() |
| 关闭浏览器所有窗口 | driver.quit() |
🚩(2)实战使用:
连续访问三个页面——天猫,淘宝,京东,然后调用back()方法回到第二个页面——淘宝,接下来再调用forward()方法又可以前进到第三个页面——京东!
⚠️①上代码:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.tmall.com/’)
time.sleep(1)
browser.get(‘https://taobao.com/’)
time.sleep(1)
browser.get(‘https://www.jd.com/’)
time.sleep(1)
browser.back()
time.sleep(1)
browser.forward()
time.sleep(1)
browser.close()
⚠️②实现效果:
selenium操作实战
第一种方法——find_element(s)by_…方法:
⚓️(1)单个节点:
在一个页面中有很多不同的策略可以定位一个元素。我们可以选择最合适的方法去查找元素。Selenium提供了下列的方法:
| 单个元素查找方法 | 作用 |
| — | — |
| find_element_by_xpath() | 通过Xpath查找 |
| find_element_by_class_name() | 通过class属性查找 |
| find_element_by_id() | 通过id属性查找 |
| find_element_by_name() | 通过name属性进行查找 |
| find_element_by_css_selector() | 通过css选择器查找 语法规则 |
| find_element_by_link_text() | 通过链接文本查找 |
| find_element_by_partial_link_text() | 通过链接文本的部分匹配查找 |
| find_element_by_tag_name() | 通过标签名查找 (只有目标元素在当前html中是唯一标签或者是众多定位出来的标签中的第一个的时候才使用!) |
注意:通过上述不管是哪一种方法,其返回的节点类型都是WebElement类型!
⚓️(2)多个节点:
| 上面方法的element加上一个s,则是对应的多个元素的查找方法。 |
如下可知其返回内容是列表类型,列表中每个节点仍然是WebElement类型:
[<selenium.webdriver.remote.webelement.WebElement (session=“73974727c0ec09e0b7d57639c3”, element=“1b33ea80-ba15-91ac-635903f79df2”)>,
<selenium.webdriver.remote.webelement.WebElement (session=“739747be09cb27c0ecd57639c3”, element=“1ac2f257-4364-be00-84de883b265d”)>]
注意:find_element匹配不到就抛出异常,但是find_elements匹配不到返回空列表!
第二种方法——By对象查找:
| 除了以上的多种查找方式,还有两种私有方法集成了上面的所有的查找方法,让我们更方便的使用! |
| 方法 | 作用 |
| — | — |
| find_element(By.XPATH, ‘//button/span’) | 通过Xpath查找一个 |
| find_elements(By.XPATH, ‘//button/span’) | 通过Xpath查找多个 |
其中的第一个参数可以选择使用查找的方法,By.xxx 使用xxx方式解析,解析方法如下(注意——By对象导入: from selenium.webdriver.common.by import By):
-
ID = “id”
-
XPATH = “xpath”
-
LINK_TEXT = “link text”
-
PARTIAL_LINK_TEXT = “partial link text”
-
NAME = “name”
-
TAG_NAME = “tag name”
-
CLASS_NAME = “class name”
-
CSS_SELECTOR = “css selector”
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。
🚀(1)常见用法:
| 方法 | 作用 |
| — | — |
| send_keys() | 输入文字 |
| clear() | 清空文字 |
| click() | 点击按钮 |
| submit() | 提交表单 |
🚀(2)示例之骚操作:
定位用户名
element=driver.find_element_by_id(“userA”)
输入用户名
element.send_keys(“admin1”)
删除输入的用户名
element.send_keys(Keys.BACK_SPACE)
重新输入用户名
element.send_keys(“admin_new”)
全选
element.send_keys(Keys.CONTROL,‘a’)
复制
element.send_keys(Keys.CONTROL,‘c’)
粘贴
driver.find_element_by_id(‘passwordA’).send_keys(Keys.CONTROL,‘v’)
👑(1)讲解:
-
在selenium当中除了简单的点击动作外,还有一些稍微复杂的动作,就需要用到ActionChains(动作链)这个子模块来满足我们的需求。
-
ActionChains可以完成复杂一点的页面交互行为,例如元素的拖拽,鼠标移动,悬停行为,内容菜单交互。 它的执行原理就是当调用ActionChains方法的时候不会立即执行,而是将所有的操作暂时储存在一个队列中,当调用perform()方法的时候,会按照队列中放入的先后顺序执行前面的操作。
-
导入ActionChains包:
from selenium.webdriver.common.action_chains import ActionChains
👑(2)方法:
| ActionChains提供的方法 | 作用 |
| — | — |
| click(on_element=None) | 鼠标左键单击传入的元素 |
| double_click(on_element=None) | 双击鼠标左键 |
| context_click(on_element=None) | 点击鼠标右键 |
| click_and_hold(on_element=None) | 点击鼠标左键,按住不放 |
| release(on_element=None) | 在某个元素位置松开鼠标左键 |
| drag_and_drop(source, target) | 拖拽到某个元素然后松开 |
| drag_and_drop_by_offset(source, xoffset, yoffset) | 拖拽到某个坐标然后松开 |
| move_to_element(to_element) | 鼠标移动到某个元素 |
| move_by_offset(xoffset, yoffset) | 移动鼠标到指定的x,y位置 |
| move_to_element_with_offset(to_element, xoffset, yoffset) | 将鼠标移动到距某个元素多少距离的位置 |
| perform() | 执行链中的所有动作 |
👑(3)示例:
示例:
-
导包:from selenium.webdriver.common.action_chains import ActionChains
-
实例化ActionChains对象:Action=ActionChains(driver)
-
调用右键方法:element=Action.context_click(username)
-
执行:element.perform()
♥️(1)获取文本内容:
- element.text
通过定位获取的标签对象的 text 属性,获取文本内容。
♥️(2)获取属性值:
- element.get_attribute(‘属性名’)
通过定位获取的标签对象的 get_attribute()函数,传入属性名,来获取属性的值。
| 对于某些操作:Selenium是没有提供相关的API的。比如:往下滑动页面,但是Selenium伟大的创造者给了我们另一个更为方便的方法——它可以直接模拟运行JavaScript,使用execute_script()方法即可! |
⚽️实战演示:
📌①上代码:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E6%96%87%E5%BA%93/4928294?fr=aladdin’)
执行JS代码,滑动网页至最底部!
js = ‘window.scrollTo(0, document.body.scrollHeight)’
browser.execute_script(js)
执行JS代码,弹窗提示文字!
browser.execute_script(‘alert(“到达最底部啦!”)’)
time.sleep(3)
📌②效果展示:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
发软件都在这里了,给大家节省了很多时间。
三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-33eqZ1xj-1713444035100)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









