









1、hashtable在插入、删除、搜寻操作上具有“常数平均时间”的表现,不依赖输入元素的随机性。
2、hashtable通过hashfunction将元素映射到不同的位置,但当不同的元素通过hash function映射到相同的位置时,便产生了“碰撞”问题。解决碰撞问题的方法主要有线性探测、二次探测、开链法等。
3、线性探测
当hash function计算出某个元素的插入位置,而该位置的空间已不可用时,循序往下寻找下一可用位置(到达尾端时绕到头部继续寻找),会产生primary clustering问题。
4、二次探测
当hash function计算出某个元素的插入位置为H,而该位置的空间已被占用,就尝试H+12、H+22…,会产生secondary clustering问题。
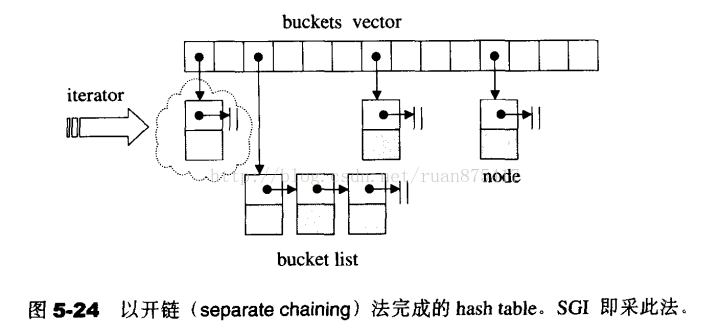
5、开链
在每一个表格元素中维护一个list:hash function为我们分配某个list,在那个list上进行元素插入、删除、搜寻等操作。SGI STL解决碰撞问题的方法就是此方法。
6、hashtable节点定义:
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;
Value val;
};7、hashtable的迭代器
hashtable迭代器必须永远维系与整个“buckets vector”的关系,并记录目前所知节点。hashtable的迭代器没有后退操作,也没有逆向迭代器。
8、hashtable的数据结构
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc>value:节点的实值类别
key:节点的键值类别
HashFcn:hash function函数类别
ExtractKey:从节点中取出键值的方法
EqualKey:判断键值相同与否的方法
Alloc:空间配置器,默认使用std::alloc
9、hashtable的构造与内存管理
节点配置函数与节点释放函数
node* new_node(const value_type& obj)
{
node* n = node_allocator::allocate();
n->next = 0;
__STL_TRY {
construct(&n->val, obj);
return n;
}
__STL_UNWIND(node_allocator::deallocate(n));
}
void delete_node(node* n)
{
destroy(&n->val);
node_allocator::deallocate(n);
}
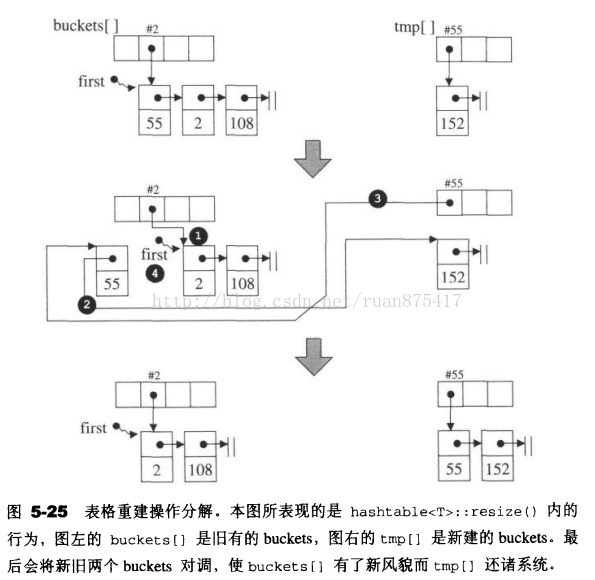
表格重建操作
resize()
{
表格是否需要重建判断原则:拿元素个数和bucket vector的大小来比,如果前者比后者大就重建表格。因此,每个bucket(list)的最大容量和bucket vector的大小相同。
如果要重建,找出下一个质数作为vector的大小,建立新的buckets
处理每一个旧的bucket{
建立一个新节点指向节点所指的串行的起始节点
处理每一个旧bucket所含串行的每一个节点{
找出节点落在哪一个新的bucket内
令旧bucket指向其所指的串行的下一个节点
将当前节点插入到新的bucket内,成为其串行的第一个节点
回到旧bucket所指的待处理串行,准备处理下一个节点
}
}
新旧两个buckets对调,如果双方大小不同,大的会变小,小的会变大
离开时释放temp的内存
}
插入操作
insert_unique(const value_type& obj)//不允许元素重复
{
resize(num_elements+1);//判断是否需要重整表格
return insert_unique_noresize(obj);
}
insert_unique_noresize(obj)
{
计算出obj应位于哪个bucket
令first指向bucket对应的串行的头部
如果bucket已经被占用,检查bucket对应的整个链表
如果发现链表中有相同的元素,就立即返回
否则产生新节点,令新节点为链表的第一个节点,节点个数加1
}
insert_equal(const value_type& obj)//允许元素重复
{
resize(num_elements+1);//判断是否需要重整表格
return insert_equal_noresize(obj);
}
insert_equal_noresize(obj)
{
计算出obj应位于哪个bucket
令first指向bucket对应的串行的头部
如果bucket已经被占用,检查bucket对应的整个链表
如果发现链表中有相同元素,则产生新节点,插入目前节点之后,节点数加1
返回一个迭代器,指向新节点
进行到这里说明没有发现新节点
产生新节点
将新节点插入到链表的头部,节点个数加1
返回一个迭代器,指向新节点
}
10、hash functions
对于字符串,设计了一个转换函数
inline size_t __stl_hash_string(const char* s)
{
unsigned long h = 0;
for ( ; *s; ++s)
h = 5*h + *s;
return size_t(h);
}其他大部分hash functions什么也不做,只是返回原值。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









