







1个master节点, 16个slave节点: CPU:8GHZ , 内存: 2G
网络:局域网
二、实验描述
通过Hadoop自带的Terasort排序程序,测试不同的map task和reduce task数量,对Hadoop性能的影响。
实验数据由程序中的teragen程序生成,数据量为1GB和10GB。
通过设置mapred.min.split.size,从而调节map task的数量;设置mapred.reduce.tasks,从而调节reduce task的数量;
dfs.replication的值设为3,其它参数默认。
三、实验结果与分析
Ø 实验一
表1、改变reduce task(数据量为1GB)
| Maptask = 16 | ||||||||||
| Reduce task | 1 | 5 | 10 | 15 | 16 | 20 | 25 | 30 | 45 | 60 |
| 总时间 | 892 | 146 | 110 | 92 | 88 | 100 | 128 | 101 | 145 | 104 |
| Map 时间 | 24 | 21 | 25 | 50 | 21 | 40 | 24 | 48 | 109 | 25 |
| Reduce时间 | 875 | 125 | 88 | 71 | 67 | 76 | 102 | 80 | 98 | 83 |
| Killed map/reduce Task Attempts | 0/0 | 0/2 | 0/2 | 0/5 | 0/4 | 0/9 | 0/9 | 0/8 | 1/7 | 0/17 |
结果分析:
1) 当reduce task的值小于15时,总时间和Reduce时间都与Reduce task数量成反比关系。当reduce task的值大于15时,总时间和reduce时间基本保持恒定。Reduce task的数量应该设置为接近slave节点数量,或者适当大于节点数,不宜设置为比节点数量小太多。
2) Map时间与Reduce task之间没有明显的关系。
3) Killedmap Task Attempts的值对Map的时间影响很大,表1中当reduce task = 45时,Killed map Task Attempts的值为1,此时Map的时间很长,从图1可看出,map的时间主要集中在map 99%的最后阶段。
4) job运行过程中产生Killed Task Attempts的原因:这是因为hadoop里面对task的speculative机制。简单来说就是hadoop觉得有些task运行过慢,所以它在其它tasktracker上同时再运行同样的任务,当其中一个完成后,其余同样的任务就会被kill掉。这就造成有多个被kill的taskattempt。可以通过设置mapred.map.tasks.speculative.execution为false来禁止hadoop的这种行为,这样可以提高效率,因为每个speculative都是占用task的slot的。
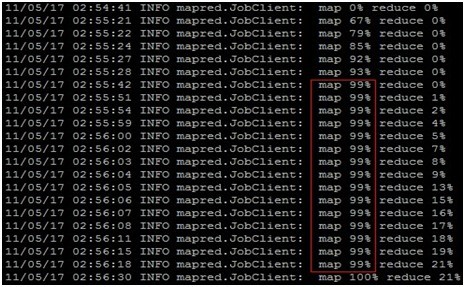
图1、表1中当reduce task = 45的执行过程
Ø 实验二
表2 改变reduce task(数据量为1GB)
| Reduce task = 15 | ||||
| Map task | 2 | 4 | 8 | 16 |
| Input Split Size | 512 | 256 | 128 | 64 |
| 总时间 | 372 | 181 | 120 | 120 |
| 平均 Map 时间 | 287 | 63 | 38 | 26 |
| Map结束时间 | 292 | 49 | 35 | 36 |
| 平均Shuffle时间 | 12 | 42 | 28 | 45 |
| Shuffle结束时间 | 308 | 103 | 63 | 67 |
| 平均Reduce时间 | 30 | 34 | 37 | 28 |
| Reduce结束时间 | 343 | 154 | 113 | 100 |
| Killed map/reduce Task Attempts | 0/4 | 0/5 | 0/3 | 0/5 |

图2、 1G数据性能对比
表3 改变map task(数据量为10GB)
| Reduce task = 15 | ||||
| Map task | 20 | 38 | 76 | 150 |
| Input Split Size | 512 | 256 | 128 | 64 |
| 总时间 | 3044 | 2464 | 2189 | 2362 |
| 平均 Map 时间 | 1274 | 825 | 403 | 231 |
| Map结束时间 | 1712 | 1409 | 1061 | 1268 |
| 平均Map时间 | 1800 | 1300 | 1144 | 1198 |
| Shuffle结束时间 | 2271 | 2236 | 1804 | 2059 |
| 平均Reduce时间 | 515 | 450 | 548 | 644 |
| Reduce结束时间 | 2624 | 2453 | 2181 | 2348 |
| Map Failed/Killed Task Attempts | 4/8 | 5/7 | 6/7 | 7/8 |
| Reduce Failed/Killed Task Attempts | 2/3 | 3/1 | 3/1 | 2/1 |
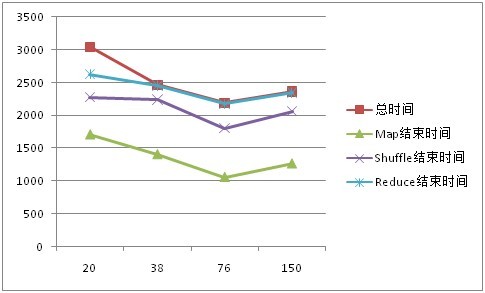
图2、 10G数据性能对比
结果分析:
1) MapTask数量对系统性能有很大影响。1G数据时,最差性能(372秒)比最好性能(120秒)低三倍,10G数据时,最差性能(3044秒)比最好性能(2189秒)多了大约14分钟。
2) 当数据量为1G和10时,总时间、Map时间、Shuffle时间、Reduce时间随着Map task数量的增大,总体上均呈现先减小后增大的变化趋势;
3) 当数据量为1G和10G时,把Input Split Size设置为128M(此时,1G数据Map task=8, 10G数据Map task =76),系统性能最佳;
当数据量为1G时,Failed的task数量一直都是0,然而当数据量为10G时,Failed task的数量变大很多,分析后发现是,数据量增大后,因为某些节点硬盘剩余容量较小,导致Fail。
四、Hadoop参数性能调优-Map and Reduce tasks数量
根据yahoo架构师Milind Bhandarkar在《Hadoop Application Performance Tuning》中的阐述,
Hadoop的性能调优主要分为以下六个方面:
• Changing number of Map and Reduce tasks
• Decrease Intermediate data size using combiner
• Decrease map-side disk spill
• Decrease intermediate data size by compressing map output
• Decrease Reduce-side disk spill
• Increase Slots per node
adoop wiki(http://wiki.apache.org/hadoop/HowManyMapsAndReduces)对这个问题有较详细的解释,大致有以下几个观点:
- 增加task的数量,一方面增加了系统的开销,另一方面增加了负载平衡和减小了任务失败的代价;
- map task的数量即mapred.map.tasks的参数值,用户不能直接设置这个参数。Input Split的大小,决定了一个Job拥有多少个map。默认input split的大小是64M(与dfs.block.size的默认值相同)。然而,如果输入的数据量巨大,那么默认的64M的block会有几万甚至几十万的Map Task,集群的网络传输会很大,最严重的是给Job Tracker的调度、队列、内存都会带来很大压力。mapred.min.split.size这个配置项决定了每个 Input Split的最小值,用户可以修改这个参数,从而改变map task的数量。
- 一个恰当的map并行度是大约每个节点10-100个map,且最好每个map的执行时间至少一分钟。
- reduce task的数量由mapred.reduce.tasks这个参数设定,默认值是1。
- 合适的reduce task数量是0.95或者0.75*(nodes * mapred.tasktracker.reduce.tasks.maximum), 其中,mapred.tasktracker.tasks.reduce.maximum的数量一般设置为各节点cpu core数量,即能同时计算的slot数量。对于0.95,当map结束时,所有的reduce能够立即启动;对于1.75,较快的节点结束第一轮reduce后,可以开始第二轮的reduce任务,从而提高负载均衡。
转自http://blog.csdn.net/xiejava/archive/2011/05/19/6432095.aspx















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









