






背景
相信大家在工作中都用过消息队列,特别是 Kafka 使用得更是普遍,业务工程师在使用 Kafka 的时候除了担忧 kafka 服务端宕机外,其实最怕如下这样两件事。
- 消息丢失。下游系统没收到上游系统发送的消息,造成系统间数据不一致。比如,订单系统没有把成功状态的订单消息成功发送到消息队列里,造成下游的统计系统没有收到下单成功订单的消息,于是造成系统间数据的不一致,从而引起用户查看个人订单列表时跟实际不相符的问题。
- 消息重复。相同的消息重复发送会造成消费者消费两次同样的消息,同样会造成系统间数据的不一致。比如,订单支付成功后会通过消息队列给支付系统发送需要扣款的金额,如果发送两次一样的扣款消息,而订单只支付了一次,而且还造成给用户余额多扣款的问题。
总结来说,这两个问题直接影响到业务系统间的数据一致性。那到底该如何避免这两个问题的发生呢?Kafka 针对这两个问题有系统的解决方案,需要服务端、客户端做相应的配置以及采取一些补偿方案。
因此,我会从生产端、服务端、消费端三个角度讲解 Kafka 是如何做到消息不丢或消息不重复的。当然,在这个过程中,为了有利于你更好的理解,在介绍的过程中我也会简单介绍一些 Kafka 的工作原理。
三种消息语义及场景
首先我要介绍一下“消息语义”的概念,这是理论基础,会有利于你更好地抓住下面解决方案的要点。
消息语义有三种,分别是:消息最多传递一次、消息最少传递一次、消息有且仅有一次传递,这三种语义分别对应:消息不重复、消息不丢、消息既不丢失也不重复。
这里的“消息传递一次”是指生产者生产消息成功,Broker 接收和保存消息成功,消费者消费消息成功。对一个消息来说,这三个要同时满足才算是“消息传递一次”。上面所说的那三种消息语义可梳理为如下。
- 最多一次(At most once):对应消息不重复。消息最多传递一次,消息有可能会丢,但不会重复。一般运用于高并发量、高吞吐,但是对于消息的丢失不是很敏感的场景。
- 最少一次(At least once):对应消息不丢。消息最少传递一次,消息不会丢,但有可能重复。一般用于并发量一般,对于消息重复传递不敏感的场景。
- 有且仅有一次(Exactly once):每条消息只会被传递一次,消息不会丢,也不会重复。 用于对消息可靠性要求高,且对吞吐量要求不高的场景。
为便于你更好地对比理解和记忆,我汇总了如下一张表格:
三种消息语义各项对比表
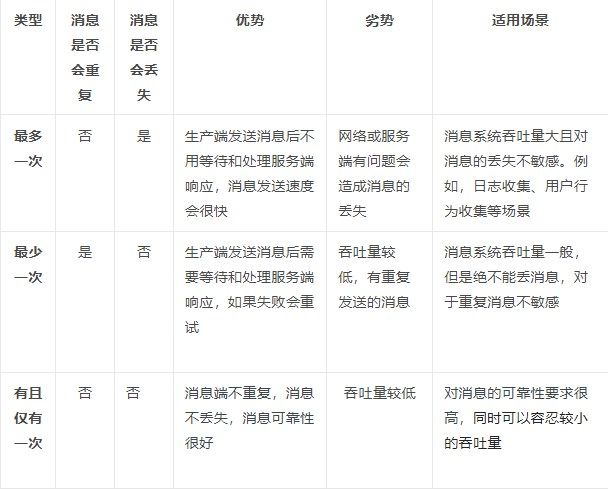
到这里,三种消息语义的定义和相关特点就介绍完了,接下来我们正式开始分析 Kafka 是如何做到消息不丢或消息不重的。
Kafka 如何做到消息不丢失?
我们先来讨论一下 Kafka 是如何做到消息不丢失的,也就是:生产者不少生产消息,服务端不丢消息,消费者也不能少消费消息。
那怎么实现这kafka不丢失消息呢?就需要生产端、服务端和消费端做好以下配置
生产端:不少生产消息
以下是为了保证消息不丢失,生产端需要配置的参数和相关使用方法。
第一个,要使用带回调方法的 API,具体 API 方法如下:
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)使用带有回调方法的 API 时,我们可以根据回调函数得知消息是否发送成功,如果发送失败了,我们要进行异常处理,比如把失败消息存储到本地硬盘或远程数据库,等应用正常了再发送,这样才能保证消息不丢失。
第二个,设置参数 acks=-1。acks 这个参数是指有多少分区副本收到消息后,生产者才认为消息发送成功了,可选的参数值是 0、1 和 -1。
- acks=0,表示生产者不等待任何服务器节点的响应,只要发送消息就认为成功。
- acks=1,表示生产者收到 leader 分区的响应就认为发送成功。
- acks=-1 ,表示只有当 ISR(ISR的含义文章下面会给大家介绍) 中的副本全部收到消息时,生产者才会认为消息生产成功了。这种配置是最安全的,因为如果leader 副本挂了,当follower副本被选为leader副本时,消息也不会丢失。但是系统吞吐量会降低,因为生产者要等待所有副本都收到消息才能再次发送消息。
第三个,设置参数 retries=3。参数 retries 表示生产者生产消息的重试次数。 retries=3是一个建议值,一般情况下能满足足够的重试次数以至于能重试成功。但是如果重试失败了,对异常处理时就可以把消息保存到其他可靠的地方,如磁盘、数据库、远程缓存等,然后等到服务正常了再继续发送消息。
第四个,设置参数 retry.backoff.ms=300。retry.backoff.ms 指消息生产超时或失败后重试的间隔时间,单位是毫秒。如果重试时间太短,会出现系统还没恢复就开始重试的情况,进而导致再次失败,如果时间太长会造成。结合我个人经验来说,300 毫秒还是比较合适的。
只要上面四个要点配置对了,就基本可以保证生产端的生产者不少生产消息了
服务端:不丢消息
以下是为了保证服务端不丢消息,服务端需要配置的参数。
第一个,设置 replication.factor >1。replication.factor 这个参数表示分区副本的个数,这里我们要将其设置为大于 1 的数,这样当 leader 副本挂了,follower 副本还能被选为 leader 副本继续接收消息。
第二个,设置 min.insync.replicas >1。
min.insync.replicas指ISR 最少的副本数量,原理同上,也需要大于 1 的副本数量保证消息不丢。
这里我们简单介绍下 ISR。ISR 集合一个分区的副本的集合,每个分区都有自己的一个 ISR 集合。但不是所有的副本都会在这个集合里。首先 leader 副本是在 ISR 集合里的,以及如果一个follower副本的消息没落后leader副本太长时间,这个follower副本也在ISR集合里,同时如果有一个follower副本落后leader副本太长时间就从 ISR 集合里淘汰出去。也就是说ISR里的副本数量是小于等于分区的副本数量的。
第三个,设置 unclean.leader.election.enable = false。unclean.leader.election.enable 指是否能把非 ISR 集合中的副本选举为 leader 副本。unclean.leader.election.enable = true,也就是说允许非 ISR 集合中的 follower 副本成为 leader 副本。如果设置成这样会有什么问题呢?下面我结合几个示意图来为你详细分析下这个问题。
假设 ISR 集合内的 follower1 副本和 ISR 集合外的 follower2 副本向 leader 副本拉取消息(如下图 1),也就是说这时 ISR 集合中就有两个副本,一个是 leader 副本,另一个是 follower1 副本,而follower2 副本由于网络或自身机器的原因已经落后 leader 副本很长时间,已经被踢出 ISR 集合。
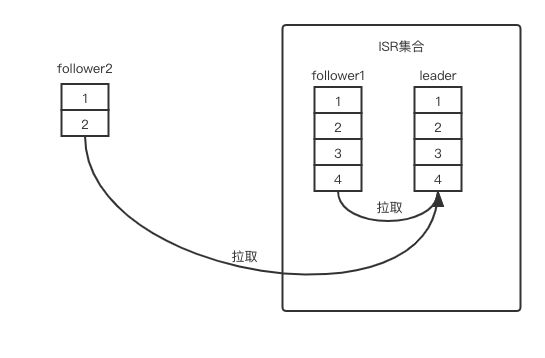
图 1:ISR 集合内外两个follower 副本拉取消息
突然 leader 和 follower1 这两个节点挂了(如图 2),会导致什么样的结果出现呢?
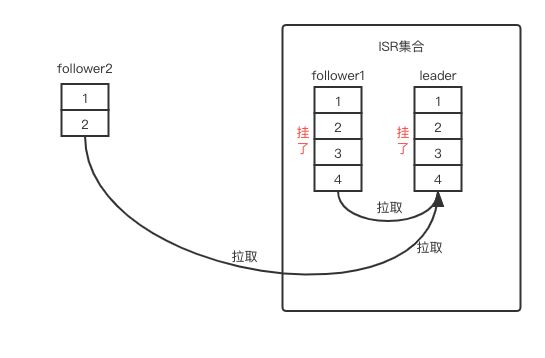
图 2:ISR 集合内两个副本挂掉了
由于 unclean.leader.election.enable = true,而现在分区的副本能正常工作的仅仅剩下 follower2 副本,所以 follower2 最终会被选为新的 leader 副本并继续接收生产者发送的消息,如下图我们可以看到它接收了一个新的消息 5。
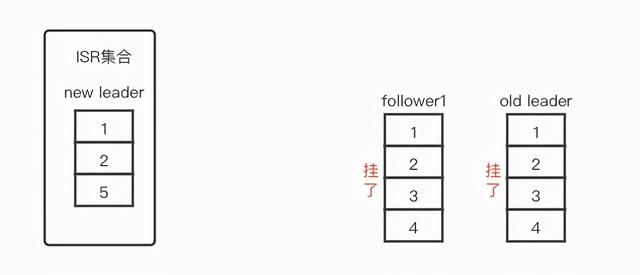
图 3:follower2 副本被选为新的 leader 副本
如果这时 follower1 副本的服务恢复,又会发生什么情况呢?由于 follower 副本要拉取 leader 副本同步数据,首先要获取 leader 副本的信息,并感知到现在的 leader 副本的 LEO 比自己的还小,于是做了截断操作,这时 4 这个消息就丢了,这就造成了消息的丢失。
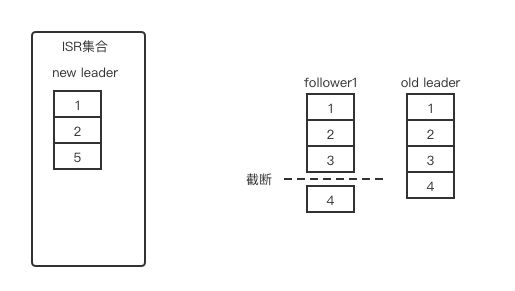
图 4:follower1 副本服务恢复,消息 4 丢失
因此,我们一定要把 unclean.leader.election.enable 设置为 false,只有这样非 ISR 集合的副本才不会被选为分区的 leader 副本。但是这样做也降低了可用性,因为这个分区的副本没有 leader,就无法收发消息了,但是消息会发送到别的分区 leader 副本,也就是说分区的数量实际上减少了。
消费端:不能少消费消息
为了保证不丢失消息,消费者就不能少消费消息,该如何去实现呢?消费端需要做好如下的配置。
第一个,设置 enable.auto.commit=false。enable.auto.commit 这个参数表示是否自动提交,如果是自动提交会导致什么问题出现呢?
消费者消费消息是有两个步骤的,首先拉取消息,然后再处理消息。向服务端提交消息偏移量可以手动提交也可以自动提交。如果把参数enable.auto.commit设置为true指消息偏移量是由消费端的自动提交,由异步线程去完成的,业务线程无法控制。如果刚拉取了消息之后,业务处理还没进行完,这时提交了消息偏移量但是这时消费者挂了,这就造成还没进行完业务处理的消息的位移被提交了,下次再消费就消费不到这些消息,造成消息的丢失。因此,一定要设置 enable.auto.commit=false。 也就是手动提交消息偏移量。
第二步,手动提交偏移量的正确步骤。但是enable.auto.commit=false还不能完全满足消费端消息不丢的条件,还要有正确的手动提交偏移量的过程。具体如何操作呢?这里我们同样结合一个示意图来讲解,如下所示:
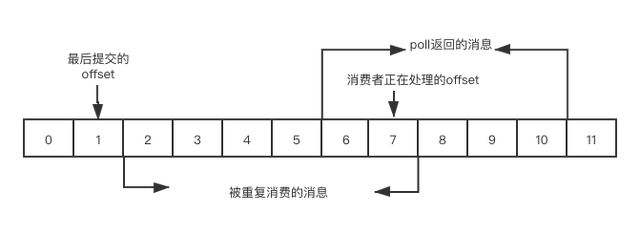
避免少消费消息的偏移量提交方案
表示业务逻辑先对消息进行处理,再提交 offset。这种模式如果消费者在处理完消息后,提交 offset 前出现宕机,待消费者再上线时,还会处理未提交的那部分消息(这里是 2~7 这部分消息),但是这部分已经被消费者处理过了,也就是说这样做虽然避免了丢消息,但是会有重复消费的情况。
具体代码需要这么写:
processMsg(messages);
consumer.commitOffset();
Kafka 如何做到消息不重复?
接下来我们讨论 Kafka 又是如何做到消息不重复的,同样也是生产端重复生产消息,服务端重复存储消息,消费者也不能重复消费消息
生产端:
生产端发送消息后,假如遇到网络问题,无法获得响应,生产端就无法判断该消息是否成功提交到了 Kafka,而我们一般会配置重试次数,但这样会引发生产端重新发送同一条消息,从而造成消息重复的发送。
对于这个问题,Kafka 0.11.0 的版本之前并没有什么解决方案,不过从 0.11.0 的版本开始,Kafka 给每个 producer 一个唯一 ID,并且在每条消息中生成一个 sequence num,sequence num是递增且唯一的这样就能对消息去重,达到 一个生产端不重复发送一条消息。但是这个方法是有局限性的,只在一个 生产端 内生产的消息有效,如果一个消息分别在两个 producer 发送就不行了,还是会造成消息的重复发送。但是这种可能性比较小,因为消息的重试一般会在一个生产端内进行。当然,对应一个消息分别在两个 producer 发送的请求我们也有方案,只是多做一些补偿的工作,我们可以为每一个消息分配一个全局id,并把全局id存放在远程缓存或关系型数据库里。这样在发送前判断一下是否已经发送过。
服务端:
服务端不会重复的存储消息,如果有重复消息也应该是生产端重复发送造成的,所以无需特别的配置。
消费端:
第一步,enable.auto.commit=false:
同样要避免自动提交偏移量,大家可以想象一种情况,消费端拉取消息和处理消息都完成了,但是自动提交偏移量还没提交这时消费端挂了,这时候kakfa消费组开始重平衡并把分区分给了另一个消费者,由于偏移量没提交新的消费者会重复拉取消息,最终造成重复消费消息。
第二步,单纯配成手动提交同样不能避免重复消费,需要消费端用正确姿势消费。先看下图这种情况:
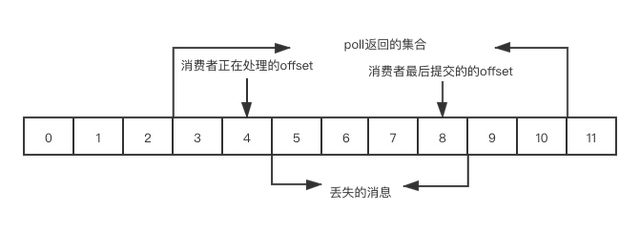
避免重复消费的偏移量提交方案
消费者拉取消息后,先提交 offset 后再处理消息。在提交 offset 之后,业务逻辑处理消息之前出现宕机,待消费者重新上线时,就无法读到刚刚已经提交而未处理的这部分消息(这里对应图中 5~8 这部分消息),这就对应了不重复消费消息但是会有丢失消息的情况。
具体代码如下:
List<String> messages = consumer.poll();consumer.commitOffset();processMsg(messages);总结
最后这里我也简单总结下这一讲分享的主要内容。首先我们介绍了消息的三个语义及其场景,接下来我们从 Kafka 生产端、服务端和消费端三个方面具体讲解了我们到底该如何配置才能实现消息不丢失以及消息不重复。在这个过程中,我们也同步解释了一些 Kafka 的原理知识,这样能你才能知其然并知其所以然。
Kafka 中消息不丢失、不重复很重要,就我个人经验来讲,我是公司专门负责消息队列的架构师,业务的同学除了消息队列服务端宕机外,对消息的丢失和重复消息非常敏感,因为直接影响到了业务。














 2338
2338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









