






项目中进行接口压测,发现批量插入的速度有点超出预期,感觉很奇怪,经过定位后发现mybatise-plus批量保存的处理十分缓慢,使用的是saveBatch方法,这点有点想不通。于是就进行了相关内容分析。
根据mybatise-plus中saveBatch的方法进行源码查看:

继续跟踪逻辑,从代码上看,确实是一条条执行了sqlSession.insert(sqlStatement, entity) 方法。

继续跟踪,下面的consumer执行的就是上面的sqlSession.insert方法:
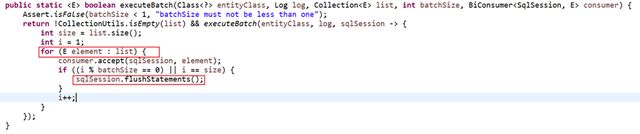
具体执行逻辑中是累计到 一定数量后,一批数据进行flush。
其实,从上述的代码实现上看,整个实现机制跟我们预想的差不多,基本上是批量的实现思路。这种批量的处理肯定比一条条的insert要快。
但是,为什么还是如此的缓慢。
下面我们就进行一个粗略的实验,来对比一波。现在使用4种方式进行比较:
1、批量数据单条执行,调用myBatise方法save
2、批量执行调用myBatise方法saveBatch
3、通过xml手写sql批量插入
4、JDBC方式批量插入开始进行实验
1、1000条数据,一条条的插入
执行结果为:

可以看到,执行一批1000条点的数据,耗费时间为1173毫秒。
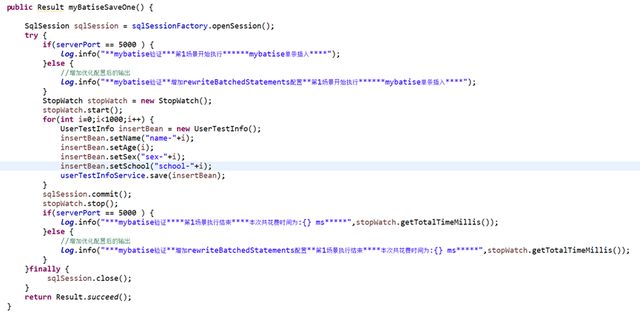
2、1000条数据,使用mybatise-plus的saveBatch插入

执行结果为:

可以看到,本次总的耗时为289毫秒,比一条条的插入快了大约4倍,效率还是可以的。
3、通过xml手写sql批量插入。
Xml中拼接内容为:

Java代码内容为:

执行程序看下性能如何:

本次耗时只有34毫秒,性能比saveBatch提高了7倍
4、JDBC方式批量插入开始进行实验
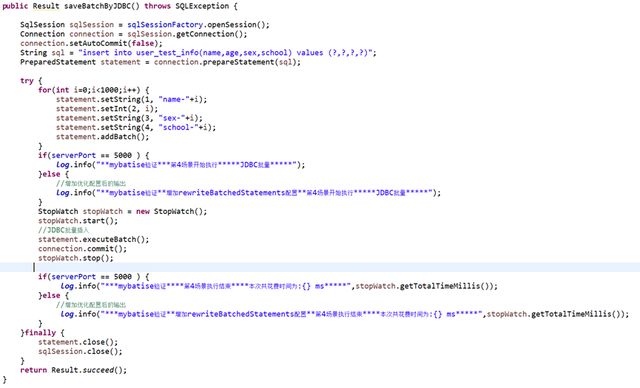
执行情况:

本次耗时142毫秒,
执行效率比saveBatch要快,比手动拼接方式要慢,
综上所述,手动拼接sql的方式是批量保存效率最佳。
5、结论
整个执行结果跟预期的不一样,这里我们直接说结论,因为mybatise-plus的saveBatch方法会继续调用mysql驱动中的实现,
在Mysql的驱动jar中,ClientPreparedStatement.java中executeBatchInternal()方法中
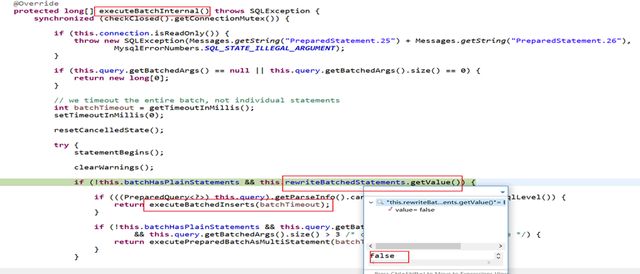
就是这个叫 rewriteBatchedStatements 的属性,从名字来看是要重写批操作的 Statement,前面batchHasPlainStatements 已经是 false,取反肯定是 true,所以只要这参数是 true 就会进行一波操作。
属性默认是 false。
可以直接将 jdbcurl 加上了这个参数:
看下 executeBatchedInserts 究竟干了什么,在上面基础上继续执行逻辑,
果然,sql语句倍rewrite了:
对于插入而言,所谓的rewrite其实就是将一批插入拼接成insert into XXX values(a),(b)…
这样的一条语句形式后再执行,这样一来跟拼接sql的效果是一样的。
那么,为什么默认不给这个rewriteBatchedStatements属性设置为true,
原来有如下原因:
看下 executeBatchedInserts 究竟干了什么:
1. 如果批量语句中的某些语句失败,则默认重写会导致所有语句都失败。
2. 批量语句的某些语句参数不一样,则默认重写会使得查询缓存未命中。
看起来影响不大,所以我给我的项目设置上了这个参数!
最后我稍微总结下粗略的对比:大家如果想要更准确的实现,可以自己进行更多组数据测试:
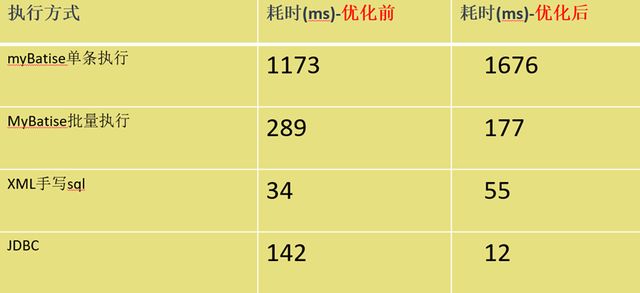
以如果有使用 jdbc 的 Batch 性能方面的需求,要将 rewriteBatchedStatements 设置为 true,这样能提高很多性能。
然后如果喜欢手动拼接 sql 要注意一次拼接的数量,分批处理。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









