







 本文介绍了一种使用Apache Bigtop工具在CentOS 7.8上打包大数据组件的方法。通过在阿里云服务器上安装Docker并运行特定的Bigtop镜像,实现了包括Zookeeper、Hadoop、Spark和Hive等大数据组件的自动化编译与打包。
本文介绍了一种使用Apache Bigtop工具在CentOS 7.8上打包大数据组件的方法。通过在阿里云服务器上安装Docker并运行特定的Bigtop镜像,实现了包括Zookeeper、Hadoop、Spark和Hive等大数据组件的自动化编译与打包。
Apache Bigtop是一个编译、打包、部署开源大数据组件的工具,经过我多方实验,现在将可靠的 Bigtop打包大数据组件的过程与方法写在这里
1. 申请一个虚拟机。我这里用的是阿里云的服务器,centos7.8,建议镜像在印度、硅谷等地区,不建议选国内的

2.登入虚拟机或是服务器,安装docker,用下面的命令安装
curl -fsSL https://get.docker.com | bash -s docker3.拉取bigtop/slaves的镜像,选取跟自己虚拟机或服务器所契合的版本。具体选择可在下面网址进行:https://hub.docker.com/r/bigtop/slaves/tags?page=1&ordering=last_updated
我选取的是版本是trunk-centos-7
docker pull bigtop/slaves:trunk-centos-74. 交互式运行容器
docker run -it bigtop/slaves:trunk-centos-7 /bin/bash5. 执行下面的命令
cd ~ && git clone https://github.com/apache/bigtop.git \
&& cd bigtop && ./gradle zookeeper-rpm hadoop-rpm spark-rpm hive-rpm然后就可以忙其他事情了,因为这个打包过程会十分漫长,一般需要两三个小时。等你喝杯茶,吃完饭过来,看到打包完毕,我们可以查看一下打包的效果
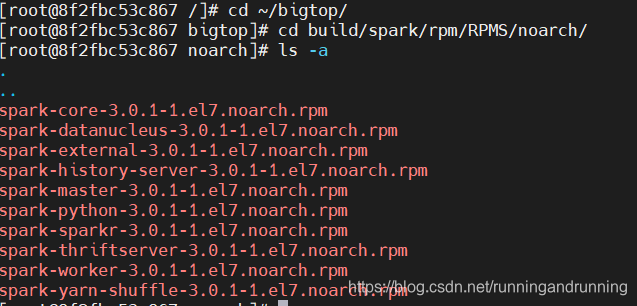
其他组件也看看,打包都完毕之后,就可以把这个docker 容器提交为一个新镜像 ,方便下次使用
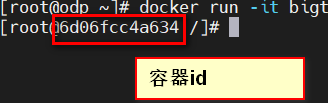
记住这个id,然后退出这个容器
exit根据这个容器id,进行commit,名字、版本请自己定义,我这里定义的是bigtop:v1
docker commit -m 'bigtop编译大数据组件' 6d06fcc4a634 bigtop:v1最后,命令运行完毕之后,我们来确认一下,有没有新的镜像有没有形成

至此,bigtop打包大数据组件的工作已经完成了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









