






YOLOV4:You Only Look Once目标检测模型在pytorch当中的实现
目录
一、所需环境
torch==1.2.0
二、训练步骤
1. 数据集的准备
本文使用VOC格式进行训练,训练前需要自己制作好数据集
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
本文使用的图片处理程序为:labelImg
标注示例如下:

标注后的图片文件存放:

原图存放(jpg格式):
2. 数据集的处理
在完成数据集的摆放之后,我们需要利用voc_annotation.py获得训练用的2007_train.txt和2007_val.txt。
修改voc_annotation.py里面的参数。第一次训练可以仅修改classes_path,classes_path用于指向检测类别所对应的txt。 训练自己的数据集时,可以自己建立一个cls_classes.txt,里面写自己所需要区分的类别。
model_data/cls_classes.txt文件内容为:
eye
ear
nose
mouth
eyebrow修改voc_annotation.py中的classes_path,使其对应cls_classes.txt,并修改annotation_mode,具体如何修改详见代码注释,之后并运行voc_annotation.py。
#------------------------------------------------------------------#
# annotation_mode用于指定该文件运行时计算的内容
# annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
# annotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txt
# annotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt
#-------------------------------------------------------------------#
annotation_mode = 0
#-------------------------------------------------------------------#
# 必须要修改,用于生成2007_train.txt、2007_val.txt的目标信息
# 与训练和预测所用的classes_path一致即可
# 如果生成的2007_train.txt里面没有目标信息
# 那么就是因为classes没有设定正确
# 仅在annotation_mode为0和2的时候有效
#-------------------------------------------------------------------#
classes_path = 'model_data/cls_classes.txt'运行结果:
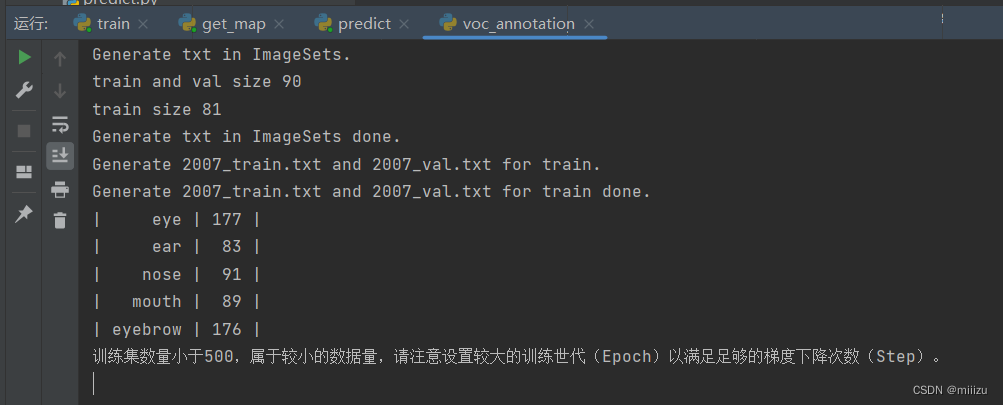
可以看出如果训练集数量较小(我们采用的训练集数量为100),会提示设置较大训练世代(Epoch)以满足足够的梯度下降次数(Step)。
3. 开始网络训练
训练的参数较多,均在train.py中,classes_path用于指向检测类别所对应的txt,这个txt和voc_annotation.py里面的txt一样,训练自己的数据集必须要修改。修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。
在进行训练时遇到了关于无法识别某些包的问题,经检查发现有两种问题可能所在,分别是:1.路径过深;2.pycharm在面对路径下同名文件夹和包名的时候可能会无法识别。这时候需要移动一下项目存放地址,或是将重名的文件夹和包名进行修改即可。
也有第三种解决方式(不一定可以成功),可以利用sys进行绝对路径的导入:
import sys
# 添加模块路径到 sys.path
sys.path.append("路径")
# 从 AAA 包中导入 BBB 模块
from AAA import BBB
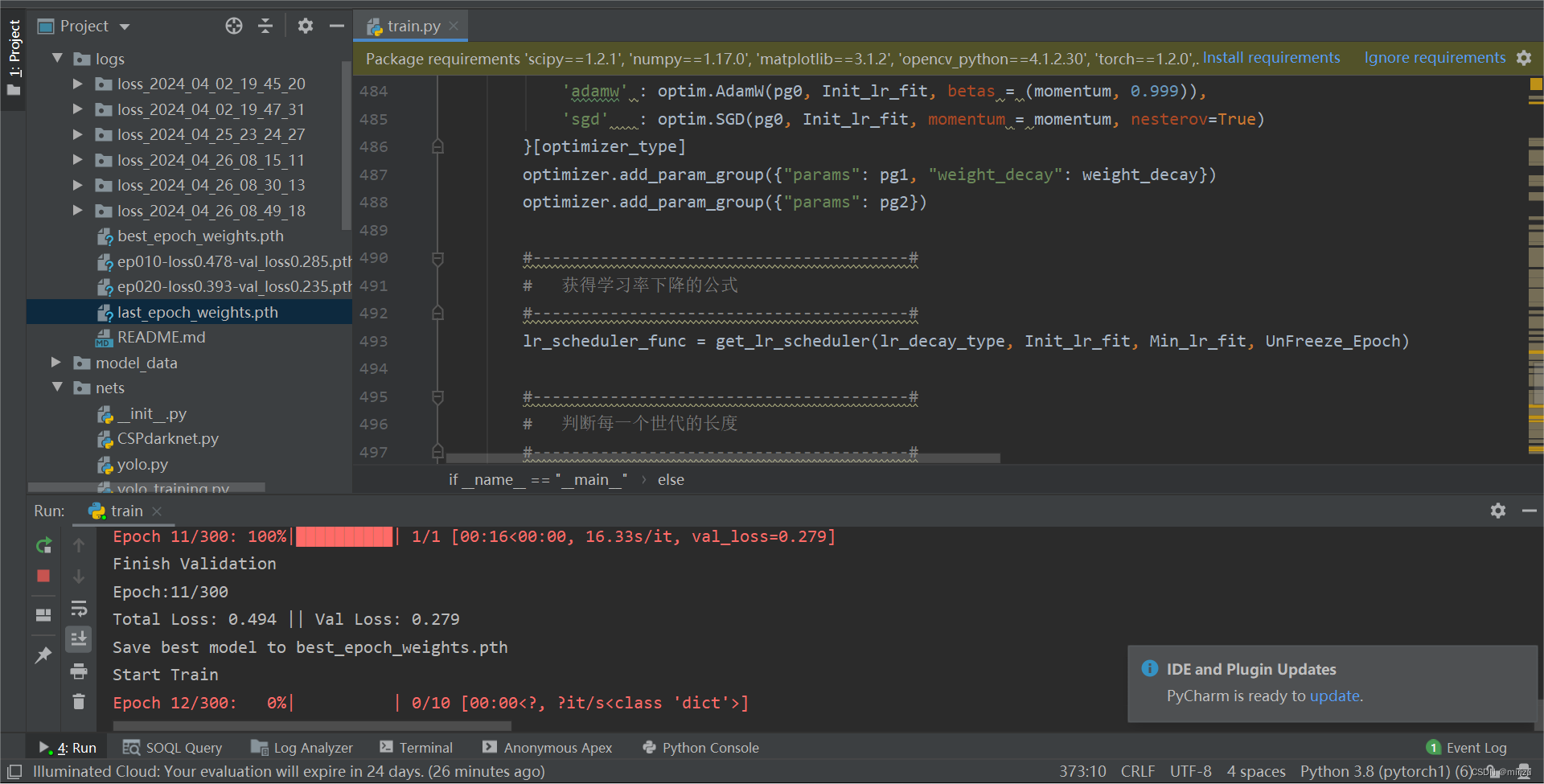
训练开始:
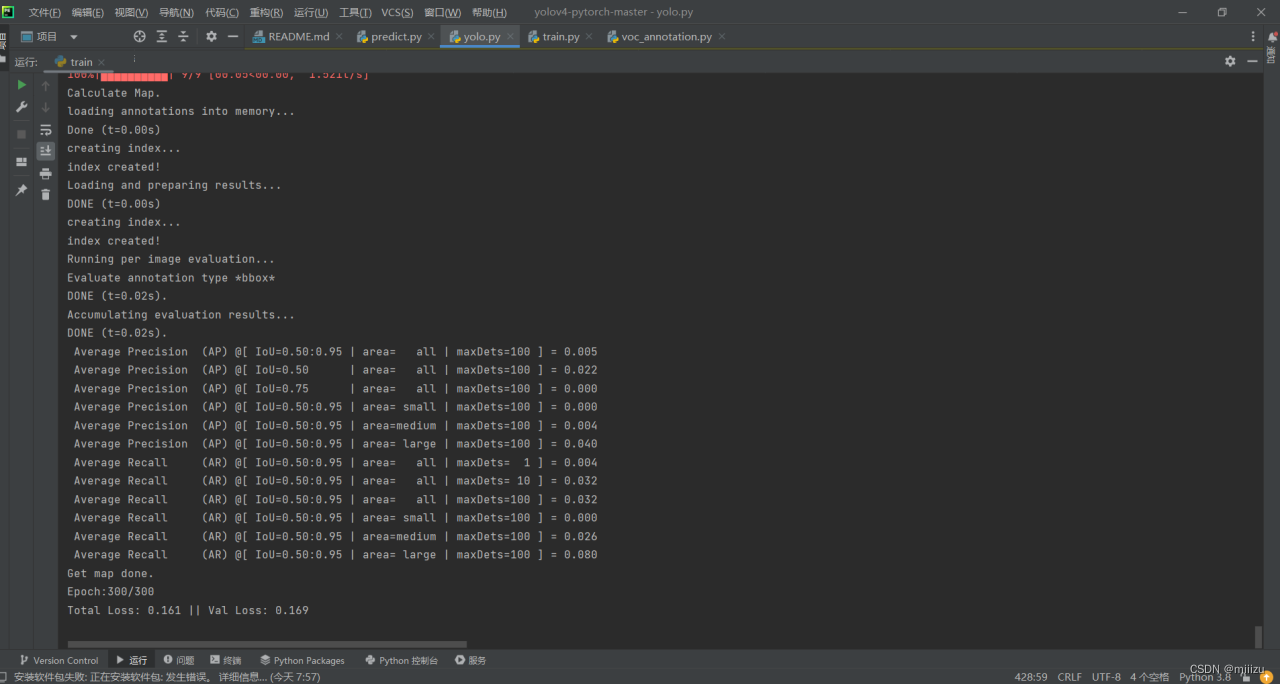
训练完成:
4. 训练结果预测
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。在yolo.py里面修改model_path以及classes_path。
model_path指向训练好的权值文件,在logs文件夹里。 classes_path指向检测类别所对应的txt。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
三、预测步骤
使用自己训练的权重
1. 按照训练步骤训练
2. 在yolo.py文件里面,在如下部分修改model_path和classes_path使其对应训练好的文件;model_path对应logs文件夹下面的权值文件,classes_path是model_path对应分的类。
_defaults = {
#--------------------------------------------------------------------------#
# 使用自己训练好的模型进行预测一定要修改model_path和classes_path!
# model_path指向logs文件夹下的权值文件,classes_path指向model_data下的txt
# 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改
#--------------------------------------------------------------------------#
"model_path" : 'logs/best_epoch_weights.pth',
"classes_path" : 'model_data/coco_classes.txt',
#---------------------------------------------------------------------#
# anchors_path代表先验框对应的txt文件,一般不修改。
# anchors_mask用于帮助代码找到对应的先验框,一般不修改。
#---------------------------------------------------------------------#
"anchors_path" : 'model_data/yolo_anchors.txt',
"anchors_mask" : [[6, 7, 8], [3, 4, 5], [0, 1, 2]],
#---------------------------------------------------------------------#
# 输入图片的大小,必须为32的倍数。
#---------------------------------------------------------------------#
"input_shape" : [416, 416],
#---------------------------------------------------------------------#
# 只有得分大于置信度的预测框会被保留下来
#---------------------------------------------------------------------#
"confidence" : 0.5,
#---------------------------------------------------------------------#
# 非极大抑制所用到的nms_iou大小
#---------------------------------------------------------------------#
"nms_iou" : 0.3,
#---------------------------------------------------------------------#
# 该变量用于控制是否使用letterbox_image对输入图像进行不失真的resize,
# 在多次测试后,发现关闭letterbox_image直接resize的效果更好
#---------------------------------------------------------------------#
"letterbox_image" : False,
#-------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
#-------------------------------#
"cuda" : True,
}如果所用训练集和循环世代太小可能会导致模型精度不足导致最后的输出无法得出结果,此时需要修改confidence和nms_iou的值让其更小才能得出图片的预测结果。
3. 运行predict.py,输入预测图片的路径:

目标检测效果:
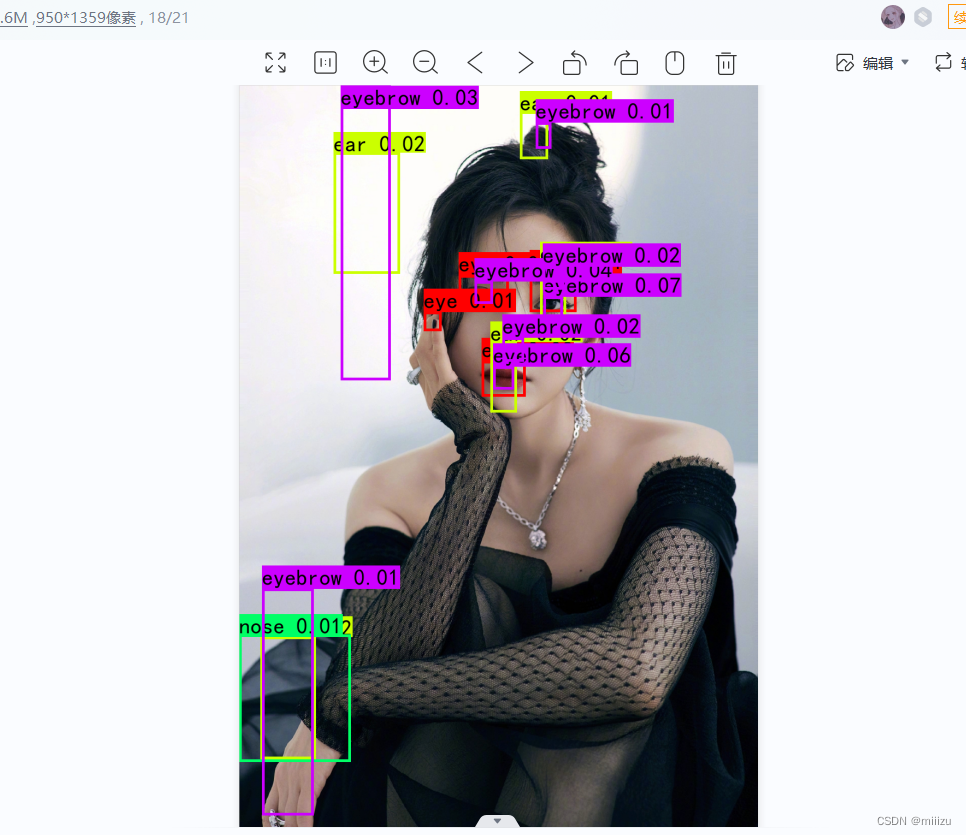
可以看到检测准确率不高,这是因为训练的数据集较小和循环世代较低的原因。
4. 在predict.py里面进行设置可以进行fps测试和video视频检测。
四、评估步骤
评估自己的数据集
1. 本文使用VOC格式进行评估。
2. 如果在训练前已经运行过voc_annotation.py文件,代码会自动将数据集划分成训练集、验证集和测试集。如果想要修改测试集的比例,可以修改voc_annotation.py文件下的trainval_percent。trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1。train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1。
#---------------------------------------------------------------------------------------#
# trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1
# train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1
# 仅在annotation_mode为0和1的时候有效
#---------------------------------------------------------------------------------------#
trainval_percent = 0.9
train_percent = 0.93. 利用voc_annotation.py划分测试集后,前往get_map.py文件修改classes_path,classes_path用于指向检测类别所对应的txt,这个txt和训练时的txt一样。评估自己的数据集必须要修改。
#--------------------------------------------------------------------------------------#
# 此处的classes_path用于指定需要测量VOC_map的类别
# 一般情况下与训练和预测所用的classes_path一致即可
#--------------------------------------------------------------------------------------#
classes_path = 'model_data/cls_classes.txt'4.在yolo.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。
5.运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。
结果如图:
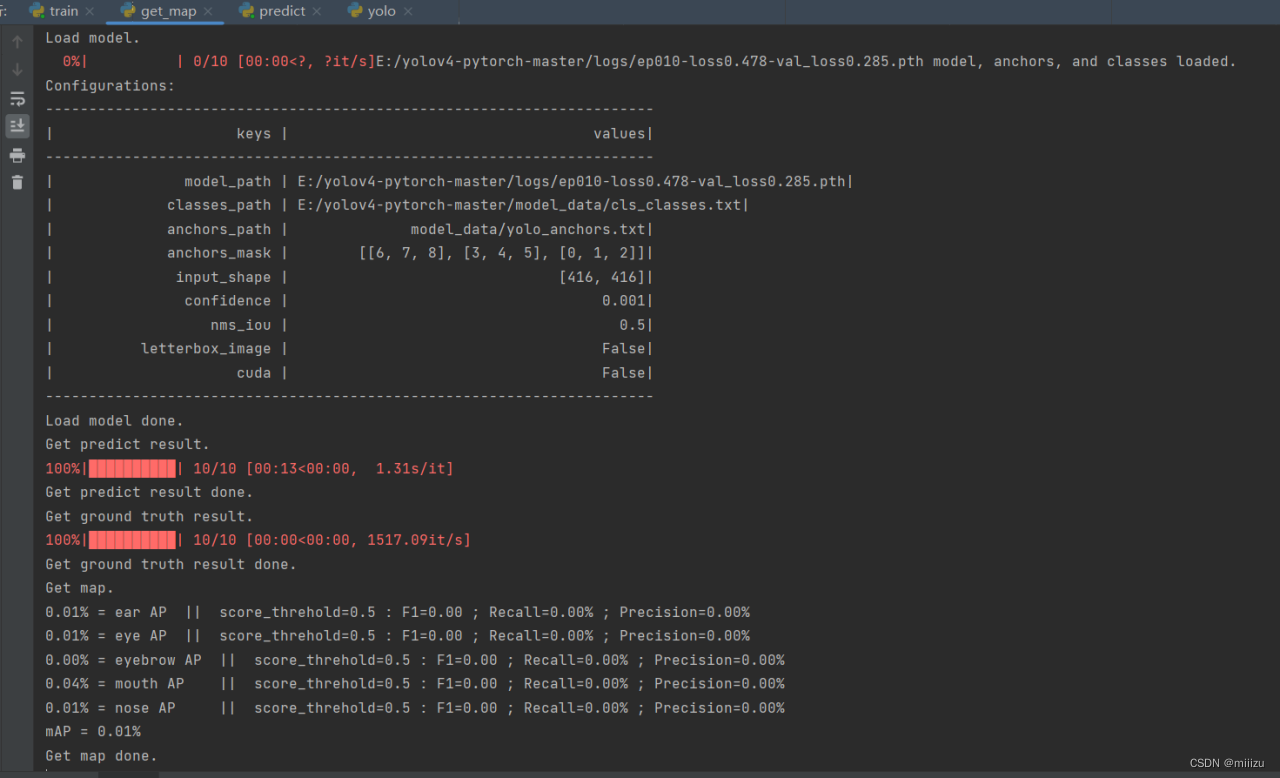
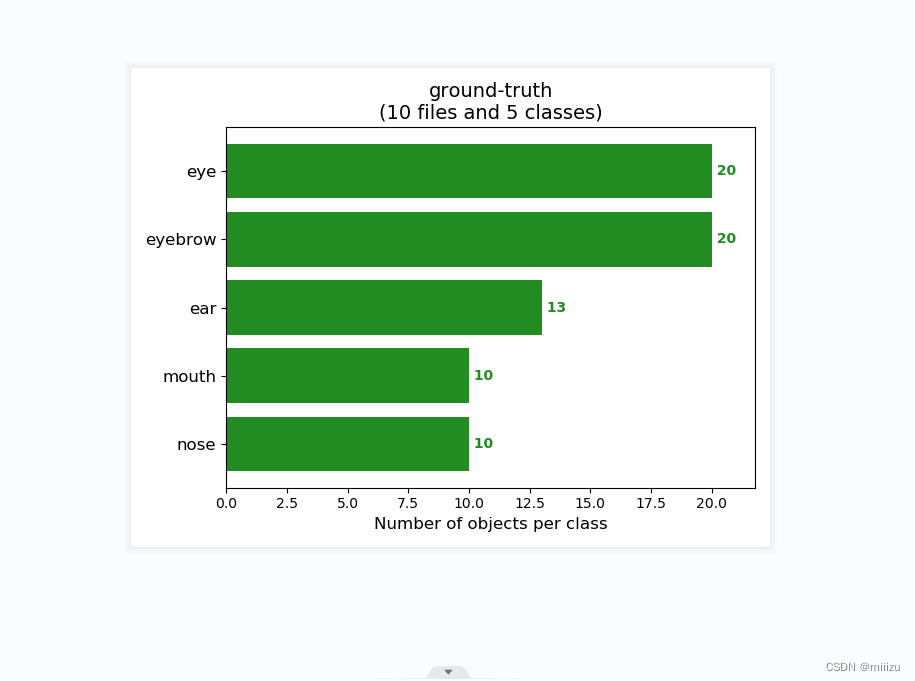
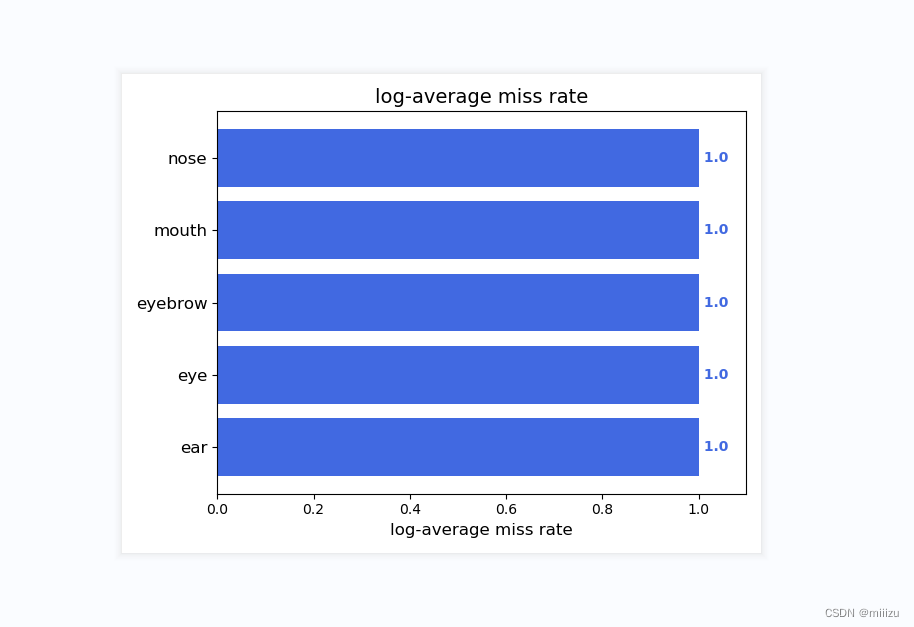

实验感想:
五官识别任务相较于一般的目标检测任务更为复杂,因为五官之间的形状、大小、位置差异较大,且容易受到头部姿态、表情等因素的影响。此外,YOLOv4模型虽然具有出色的性能,但其计算复杂度较高,对硬件资源的需求也较大。因此,在实验过程中,我们需要在保证识别准确率的同时,尽可能地优化模型的性能,减少计算成本。
在实验过程中,我深刻感受到了深度学习技术的强大和灵活性。通过调整模型的超参数、优化网络结构、改进训练策略等手段,我们可以不断提升模型的性能。同时,我也认识到了数据的重要性。一个优秀的模型离不开大量高质量的标注数据。在实验过程中,我们花费了大量时间进行数据预处理和标注工作,以确保模型的训练效果。
此外,我也体验到了团队协作的力量。在实验过程中,我们团队成员相互协作、共同解决问题,不断推动实验进展。这种团队氛围让我感受到了集体的智慧和力量,也让我更加珍惜与团队成员之间的合作机会。
回顾整个实验过程,我深感收获颇丰。通过这次实验,我不仅提升了自己的实践能力和技术水平,还加深了对深度学习技术的理解和认识。同时,我也认识到了自己在技术应用和问题解决方面的不足,这将是我今后努力提升的方向。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









