









 本文介绍Apache Spark MLlib库中的数据类型,包括LocalVector、LabeledPoint、LocalMatrix等,以及分布式矩阵如RowMatrix、IndexedRowMatrix、CoordinateMatrix和BlockMatrix。这些数据结构支持机器学习算法的有效运行。
本文介绍Apache Spark MLlib库中的数据类型,包括LocalVector、LabeledPoint、LocalMatrix等,以及分布式矩阵如RowMatrix、IndexedRowMatrix、CoordinateMatrix和BlockMatrix。这些数据结构支持机器学习算法的有效运行。
文章目录
spark2.4.8
MLlib支持local vectors 和 matrices 存储在单台机台上,也可以分发matrices 依靠一个或多个RDD. Local vectors 和 local matrices 是简单的数据模型,作用于公共接口. 底层的 linear algebra 操作被 Breeze提供. 在MLlib 的训练例子使用监督学习被称为“labeled point”
Local vector
Local vector 有包含基于 0 的整型过索引和 double 类型的值,存储在单个机器上. MLlib支持两种类型的Local vector: dense 和sparse. dense vector 是被double数组表示它进入值支持, 然而sparse vector 被两个并行数组:索引和值支持.
eg. vector (1.0, 0.0, 3.0)
- dense 格式为
[1.0, 0.0, 3.0] - sparse 格式为
(3, [0, 2], [1.0, 3.0]), 3是vector的长度
local vector 的基类是 Vector, 提供两个实现: DenseVector 和SparseVector. 推荐使用的 Vectors 工厂方法来创建 local vector.
细节参考:Vector Scala 文档和Vectors Scala docs文档中 API.
import org.apache.spark.mllib.linalg.{Vector, Vectors}
// Create a dense vector (1.0, 0.0, 3.0).
val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its indices and values corresponding to nonzero entries.
val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
// Create a sparse vector (1.0, 0.0, 3.0) by specifying its nonzero entries.
val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))
注意:scala默认导入scala.collection.immutable.Vector,需要显示导入org.apache.spark.mllib.linalg.Vector
Labeled point
labeled point为 local vector, 或是dense 或 sparse, 关联一个label/response. 在MLlib labeled points 被用来监控学习算法. 使用double类型来存储label, 这样可以使用labeled points 在regression 和classification中. 对于binary classification, label 应该为0(负)或1(正). 对于多级分类, labels 应该被分类,索引从0开始0, 1, 2, …
labeled point 由case class LabeledPoint表示.
详细API查看 LabeledPoint Scala docs
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
// Create a labeled point with a positive label and a dense feature vector.
val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
// Create a labeled point with a negative label and a sparse feature vector.
val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
Sparse 数组
在实践中很常见用sparse 训练数据. MLlib 支持读训练例子存储为LIBSVM 格式, 默认的格式使用 LIBSVM 和LIBLINEAR. 这是一个文本格式,每行代表labeled sparse特性vector ,使用如下格式.
label index1:value1 index2:value2 ...
索引是从1开始升序的. 加载后,feature 索引转换为从0 开始.
MLUtils.loadLibSVMFile读训练例子存放为LIBSVM 格式.
详情查看 MLUtils Scala y文档
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.rdd.RDD
val examples: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
Local matrix
local matrix有整型的行和列索引和double类型值,存储在单台机器. MLlib支持dense matrices, 它的entry values存储单个double数组在主要在列顺序.例如,下边的dense matrix.
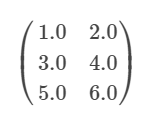
存储为一个维度数组 [1.0, 3.0, 5.0, 2.0, 4.0, 6.0] 带有size(3, 2)
local matrices基类是 Matrix, 并且 提供了两种实现 DenseMatrix 和 SparseMatrix.推荐使用 Matrices中工厂方法来创建 local matrices. 请记住, 在MLlib中 local matrices存储是以列为主.
详细查看 Matrix Scala 和Matrices Scala 文档.
import org.apache.spark.mllib.linalg.{Matrix, Matrices}
// Create a dense matrix ((1.0, 2.0), (3.0, 4.0), (5.0, 6.0))
val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
// Create a sparse matrix ((9.0, 0.0), (0.0, 8.0), (0.0, 6.0))
val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8))
Distributed matrix
Distributed matrix 是long类型行和列索引,double类型值,存储分布在一个或多个RDD.选择正确格式存储Distributed matrix 是非常重要的. 转换Distributed matrix 到不同格式可能需要全局shuffle, 非常耗资源.到目前为至有4种类型Distributed matrix的实现.
基本类型被称为RowMatrix. RowMatrix 面向行distributed matrix 没有意义的行索引. eg. feature vector集合. 它被RDD的行支持,每行是一个local vector. 我们假设一定数据列不是太多行的RowMatrix ,这样单独 local vector 可以与driver 通信,并且也可以存储/操作使用在单台节点. IndexedRowMatrix 类似于RowMatrix只是代有行索引,它可以被用来 定义唯一行并且执行join操作. CoordinateMatrix是distributed matrix存储为coordinate list (COO格式,通过RDD entries(条目)支持. BlockMatrix是distributed matrix通过RDD MatrixBlock支持,它是一个(Int, Int, Matrix) tuple .
注意:
distributed matrix RDD 底层一定是确定的,因为缓存 matrix 大小.一般使用不确定RDD会导致错误.
RowMatrix
RowMatrix是面向行 distributed matrix, 不带有有意义的索引, 通过RDD自己行支持, 每行是一个本地vector. 因为每行代表local vector, 列数量限制在int范围,在实践中他更小.
RowMatrix 可以从RDD[Vector]实例创建. 然后 就可以计算它列统计概要和decompositions. QR decomposition 是一种格式 A = QR ,Q是orthogonal matrix并且R 是一个upper triangular matrix. 对于 singular value decomposition (SVD) 和 principal component analysis (PCA), 请参考Dimensionality reduction.
详情查看 RowMatrix Scala 文档
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.linalg.distributed.RowMatrix
val rows: RDD[Vector] = ... // an RDD of local vectors
// Create a RowMatrix from an RDD[Vector].
val mat: RowMatrix = new RowMatrix(rows)
// Get its size.
val m = mat.numRows()
val n = mat.numCols()
// QR decomposition
val qrResult = mat.tallSkinnyQR(true)
IndexedRowMatrix
IndexedRowMatrix类似于RowMatrix,但是带有有意义的行索引.通过带有行索引的RDD支持,这样每行代表它的索引(long类型)和一个 local vector.
IndexedRowMatrix可以被创建通过RDD[IndexedRow]实例, IndexedRow被包装围通过(Long, Vector). IndexedRowMatrix 可以转换为RowMatrix,通过丢掉行索引.
详情查看 IndexedRowMatrix Scala 文档
import org.apache.spark.mllib.linalg.distributed.{IndexedRow, IndexedRowMatrix, RowMatrix}
val rows: RDD[IndexedRow] = ... // an RDD of indexed rows
// Create an IndexedRowMatrix from an RDD[IndexedRow].
val mat: IndexedRowMatrix = new IndexedRowMatrix(rows)
// Get its size.
val m = mat.numRows()
val n = mat.numCols()
// Drop its row indices.
val rowMat: RowMatrix = mat.toRowMatrix()
CoordinateMatrix
CoordinateMatrix 是 distributed matrix,通过RDD它的entries. 每个entry是一个tuple (i: Long, j: Long, value: Double), i 表示行索引, j表示列索引,值是entry 值. CoordinateMatrix 应该使用仅当matrix dimensions巨大, 并且matrix非常 sparse.
CoordinateMatrix 可以通过 RDD[MatrixEntry]实例创建, MatrixEntry是一个包装通过(Long, Long, Double). CoordinateMatrix 可以转换为IndexedRowMatrix带有一个sparse 行通过调用toIndexedRowMatrix. CoordinateMatrix 其它计算当前不支持
详情查看 CoordinateMatrix Scala
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}
val entries: RDD[MatrixEntry] = ... // an RDD of matrix entries
// Create a CoordinateMatrix from an RDD[MatrixEntry].
val mat: CoordinateMatrix = new CoordinateMatrix(entries)
// Get its size.
val m = mat.numRows()
val n = mat.numCols()
// Convert it to an IndexRowMatrix whose rows are sparse vectors.
val indexedRowMatrix = mat.toIndexedRowMatrix()
BlockMatrix
BlockMatrix 是 distributed matrix, 通过MatrixBlockRDD 支持, MatrixBlock 是一个((Int, Int), Matrix) tuple, (Int, Int) block 索引, 并且Matrix 是给定带索引的sub-matrix ,尺寸为rowsPerBlock x colsPerBlock. BlockMatrix 支持方法像add 和multiply,使用BlockMatrix. BlockMatrix也有帮助函数validate,可以使用检查是否BlockMatrix设置正确.
BlockMatrix 可以非常容易通过IndexedRowMatrix 或CoordinateMatrix 调用toBlockMatrix创建. toBlockMatrix 创建 block 默认尺寸为1024 x 1024. 用户可能改变block 尺寸通过应用值toBlockMatrix(rowsPerBlock, colsPerBlock).
详情查看 BlockMatrix Scala
import org.apache.spark.mllib.linalg.distributed.{BlockMatrix, CoordinateMatrix, MatrixEntry}
val entries: RDD[MatrixEntry] = ... // an RDD of (i, j, v) matrix entries
// Create a CoordinateMatrix from an RDD[MatrixEntry].
val coordMat: CoordinateMatrix = new CoordinateMatrix(entries)
// Transform the CoordinateMatrix to a BlockMatrix
val matA: BlockMatrix = coordMat.toBlockMatrix().cache()
// Validate whether the BlockMatrix is set up properly. Throws an Exception when it is not valid.
// Nothing happens if it is valid.
matA.validate()
// Calculate A^T A.
val ata = matA.transpose.multiply(matA)
https://spark.apache.org/docs/2.4.8/mllib-data-types.html




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











