第一章 Java性能调优概述
1.1 性能概述
1、性能指标:执行时间、CPU时间、内存分配、磁盘吞吐量、网络吞吐量、响应时间;切记木桶原理
2、Amdahl定理:它定义了串行系统并行化后加速比的计算公式和理论上限
加速比 = 优化前系统耗时/优化后系统耗时
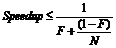
1.2 性能调优层次
1、设计调优(设计方法、设计模式、性能组件)、代码优化(API、算法、数据结构)、JVM调优(JVM启动参数、堆内存)、数据库调优(SQL语句、数据库表结构、索引、数据库性能参数)、操作系统调优(虚拟内存)
第二章 设计优化
2.1 善用设计模式
1、单例模式
应用最广泛,确保一个类只产生一个实例,这样有两大好处:(1)对于频繁使用的对象,省去了创建对象所花费的时间,特别对于重量级对象而言,这是一笔非常可观的系统开销;(2)由于new操作的减少,对于系统内存使用频率也会降低,这将减轻GC压力,缩短GC停顿时间。
单例模式的几种实现比较:
实现一:
public class Singleton {
private Singleton(){
System.out.println("Singleton is created");
}
private static Singleton instance = new Singleton();
public static Singleton getInstance(){
return instance;
}
}
通过定义构造函数为private,instance成员变量和getInstance方法为static,该单例类非常可靠,但是无法做到延迟加载,加入创建过程较慢,会影响使用者的响应速度。所以有了实现二:
public class LazySingleton{
private LazySingleton(){
System.out.println("LazySingleton is created");
}
private static LazySingleton instance = null;
public static synchronized Lazysingleton getInstance(){
if(instance==null){
instance = new LazySingleton();
}
return instance;
}
}
这一实现中给instance一开始赋值null,所以只有在调用getInstance方法时才会真正创建对象,考虑到多线程的情况,加入了同步关键字,但是这也牺牲了性能。改进如实现三:
public class StaticSingleton{
private StaticSingleton(){
System.out.println("StaticSingleton is created");
}
private static class SingletonHolder{
private static StaticSingleton instance = new StaticSingleton();
}
public static StaticSingleton getInstance(){
return SingletonHolder.instance;
}
}
这个实现中,单例模式使用内部类来维护单例的实例,当StaticSingleton被加载时其内部类不会被初始化,而当getInstance被调用时,才会加载SingletonHolder,从而初始化instance。同时,由于实例的建立是在类加载时完成,故天生对线程友好,getInstance()不需要加同步关键字。因此使用内部类的方法来实现单例,既可以做到延迟加载,又不必使用同步关键字。
2、代理模式
代理模式的使用一方面是出于安全问题的考虑,另一方面也是为了提升性能,达到延迟加载的目的。
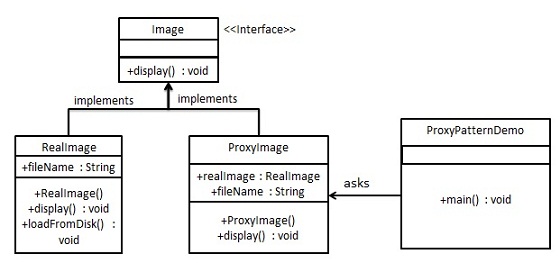
我们将创建一个 Image 接口和实现了 Image 接口的实体类。ProxyImage 是一个代理类,减少 RealImage 对象加载的内存占用。
ProxyPatternDemo,我们的演示类使用 ProxyImage 来获取要加载的 Image 对象,并按照需求进行显示。
步骤 1
创建一个接口。
Image.java
public interface Image {
void display();
}
步骤 2
创建实现接口的实体类。
RealImage.java
public class RealImage implements Image {
private String fileName;
public RealImage(String fileName){
this.fileName = fileName;
loadFromDisk(fileName);
}
@Override
public void display() {
System.out.println("Displaying " + fileName);
}
private void loadFromDisk(String fileName){
System.out.println("Loading " + fileName);
}
}
ProxyImage.java
public class ProxyImage implements Image{
private RealImage realImage;
private String fileName;
public ProxyImage(String fileName){
this.fileName = fileName;
}
@Override
public void display() {
if(realImage == null){
realImage = new RealImage(fileName);
}
realImage.display();
}
}
步骤 3
当被请求时,使用 ProxyImage 来获取 RealImage 类的对象。
ProxyPatternDemo.java
public class ProxyPatternDemo {
public static void main(String[] args) {
Image image = new ProxyImage("test_10mb.jpg");
//图像将从磁盘加载
image.display();
System.out.println("");
//图像将无法从磁盘加载
image.display();
}
}
步骤 4
验证输出。
Loading test_10mb.jpg
Displaying test_10mb.jpg
Displaying test_10mb.jpg
像Hibernate中,对于实体bean的加载就不是一次性将所有数据都进行加载,默认情况下它会采用延迟加载的机制,使用动态代理对于属性进行延迟加载,在调用get方法之前并不载入属性。
3、享元模式
享元模式是以提高性能为目的的设计模式,它的核心思想是:如果一个系统中存在多个相同的对象,那么只需要共享一份对象的拷贝,而不必多次创建新对象。这样既节省了内存空间,也省去了很多创建对象的时间开销。
享元模式的核心在于享元工厂,它对于每个不同类型维护一个对象。这区别于对象池,对象池中的对象都是等价的。它的实现如下:
public interface IReportManager{
public String createReport();
}
public class FinancialReportManager implements IReportManager{
protected String tenantId = null;
public FinancialReportManager(String tenantId){
this.tenantId = tenantId;
}
@Override
public String createReport(){
return "This is a financial report";
}
}
public class EmployeeReportManager implements IReportManager{
protected String tenantId = null;
public FinancialReportManager(String tenantId){
this.tenantId = tenantId;
}
@Override
public String createReport(){
return "This is a employee report";
}
}
public class ReportManagerFactory{
Map
financialReportManager = new HashMap
();
Map
employeeReportManager = new HashMap
();
IReportManager getFinancialReportManager(String tenantId){
IReportManger r = financialReportManager.get(tenantId);
if(r==null){
r=new FinancialReportManager(tenantId);
financialReportManager.put(tenantId,r);
}
return r;
}
IReportManager getEmployeeReportManager(String tenantId){
IReportManger r = employeeReportManager.get(tenantId);
if(r==null){
r=new EmployeeReportManager(tenantId);
employeeReportManager.put(tenantId,r);
}
return r;
}
}
public static void main(String[] args){
ReportManagerFactory factory = new ReportMangerFactory();
IReportManager rm = factory.getFinancialManager("A");
System.out.println(rm.createReport());
}
4、装饰者模式
在基本的设计原则中,有一条叫做合成/聚合原则,根据该原则思想,代码复用应该尽可能使用委托而不是继承,因为继承意味着紧耦合。装饰者模式就是运用了这种思想,通过委托机制复用多个组件,在运行时将这些功能组件进行叠加,从而构造一个超级对象。
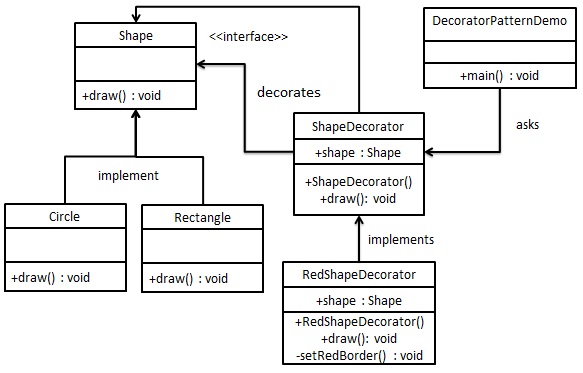
我们将创建一个 Shape 接口和实现了 Shape 接口的实体类。然后我们创建一个实现了 Shape 接口的抽象装饰类 ShapeDecorator,并把 Shape 对象作为它的实例变量。
RedShapeDecorator 是实现了 ShapeDecorator 的实体类。
DecoratorPatternDemo,我们的演示类使用 RedShapeDecorator 来装饰 Shape 对象。
步骤 1
创建一个接口。
Shape.java
public interface Shape {
void draw();
}
步骤 2
创建实现接口的实体类。
Rectangle.java
public class Rectangle implements Shape {
@Override
public void draw() {
System.out.println("Shape: Rectangle");
}
}
Circle.java
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Shape: Circle");
}
}
步骤 3
创建实现了 Shape 接口的抽象装饰类。
ShapeDecorator.java
public abstract class ShapeDecorator implements Shape {
protected Shape decoratedShape;
public ShapeDecorator(Shape decoratedShape){
this.decoratedShape = decoratedShape;
}
public void draw(){
decoratedShape.draw();
}
}
步骤 4
创建扩展了 ShapeDecorator 类的实体装饰类。
RedShapeDecorator.java
public class RedShapeDecorator extends ShapeDecorator {
public RedShapeDecorator(Shape decoratedShape) {
super(decoratedShape);
}
@Override
public void draw() {
decoratedShape.draw();
setRedBorder(decoratedShape);
}
private void setRedBorder(Shape decoratedShape){
System.out.println("Border Color: Red");
}
}
步骤 5
使用 RedShapeDecorator 来装饰 Shape 对象。
DecoratorPatternDemo.java
public class DecoratorPatternDemo {
public static void main(String[] args) {
Shape circle = new Circle();
Shape redCircle = new RedShapeDecorator(new Circle());
Shape redRectangle = new RedShapeDecorator(new Rectangle());
System.out.println("Circle with normal border");
circle.draw();
System.out.println("\nCircle of red border");
redCircle.draw();
System.out.println("\nRectangle of red border");
redRectangle.draw();
}
}
步骤 6
验证输出。
Circle with normal border
Shape: Circle
Circle of red border
Shape: Circle
Border Color: Red
Rectangle of red border
Shape: Rectangle
Border Color: Red
在JDK中,OutputStream和InputStream类族就是典型的例子。
5、观察者模式
观察者模式解决状态依赖问题,如果不使用观察者模式,则需要在另一个线程中不断监听状态。这对于复杂系统是性能的负担。

步骤 1
创建 Subject 类。
Subject.java
import java.util.ArrayList;
import java.util.List;
public class Subject {
private List<Observer> observers
= new ArrayList<Observer>();
private int state;
public int getState() {
return state;
}
public void setState(int state) {
this.state = state;
notifyAllObservers();
}
public void attach(Observer observer){
observers.add(observer);
}
public void notifyAllObservers(){
for (Observer observer : observers) {
observer.update();
}
}
}
步骤 2
创建 Observer 类。
Observer.java
public abstract class Observer {
protected Subject subject;
public abstract void update();
}
步骤 3
创建实体观察者类。
BinaryObserver.java
public class BinaryObserver extends Observer{
public BinaryObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
@Override
public void update() {
System.out.println( "Binary String: "
+ Integer.toBinaryString( subject.getState() ) );
}
}
OctalObserver.java
public class OctalObserver extends Observer{
public OctalObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
@Override
public void update() {
System.out.println( "Octal String: "
+ Integer.toOctalString( subject.getState() ) );
}
}
HexaObserver.java
public class HexaObserver extends Observer{
public HexaObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
@Override
public void update() {
System.out.println( "Hex String: "
+ Integer.toHexString( subject.getState() ).toUpperCase() );
}
}
步骤 4
使用 Subject 和实体观察者对象。
ObserverPatternDemo.java
public class ObserverPatternDemo {
public static void main(String[] args) {
Subject subject = new Subject();
new HexaObserver(subject);
new OctalObserver(subject);
new BinaryObserver(subject);
System.out.println("First state change: 15");
subject.setState(15);
System.out.println("Second state change: 10");
subject.setState(10);
}
}
步骤 5
验证输出。
First state change: 15
Hex String: F
Octal String: 17
Binary String: 1111
Second state change: 10
Hex String: A
Octal String: 12
Binary String: 1010
JDK中,java.util.Observable类已经实现了主要的功能,如增加观察者、删除观察者和通知观察者,java.util.Observer接口是观察者接口,它的updata()方法会被Observable中的notifyObservrs()方法回调,已获得最新状态变化。对于观察者模式,Observer接口总是核心扩展对象,具体的业务逻辑总是被封装在update()方法中。
6、Value Object模式
其核心思想是对一个对象的各个属性进行封装,将封装后的对象进行传输,这样避免了对不同属性进行多次请求。
7、业务代理模式
2.2 常用优化组件和方法
1、缓冲
缓冲区的作用是缓解应用上下层之间的性能差异,可以想象一个漏斗的作用。缓冲区最适用的场景就是I/O操作,后者经常成为性能瓶颈。
2、缓存
缓存的作用是暂存数据或者处理结果,供下一次访问使用。最简单的缓存是HashMap,但会有清理数据和内存溢出等问题。对于一个频繁使用的且重负载的函数实现中,加入缓存可以提高它的调用性能。
3、对象复用——池
对象池化的核心思想是,如果一个类被频繁请求使用,那么不必每一次都创建一个新实例,可以将这个类的一些实例保存在一个“池”中,待需要使用时直接从池中获取使用。实现细节上,可以是一个数组或者链表或其它集合类。对象池最典型的例子就是线程池和数据库连接池。
4、并行替代串行
5、负载均衡
Apache服务器作为负载分配器,将请求转向各个Tomcat服务器,从而实现负载均衡。
在使用Tomcat集群时,有两种基本的Session共享模式,黏性Session模式和复制Session模式。黏性Session模式下,所有的Session信息被平均分到各个服务器,如果某个节点宕机,其它节点也不会保存这个用户信息,不具备高可用性;复制Session模式下,使用广播的方式将一个节点的Session变化通知所有节点。但是可能造成网络繁忙。Terrocotta是一个解决Session共享的解决方案。
6、空间换时间:缓存
7、时间换空间:
第三章 Java程序优化
3.1 字符串优化处理
1、首先要了解字符串的本质。String对象不是基本的数据类型,它是一个类,可以理解为char数组的延伸和进一步封装,它的内部结构由3部分构成,char数组、偏移量、长度。
同时,String对象有三个基本特点:
不变性:所谓的不变性是指引用的对象实例的是不可以改变的,但是可以改变引用地址,所以通过改变引用地址就可以改变值了。
在并行开发过程中,为确保数据的一致性和正确性,又必要对对象进行同步,但是同步操作对系统性能有相当的损耗。因此可以使用一种不可改变的对象,依靠其不变形来确保并行操作在没有同步的情况下依旧保持一致性和正确性。
不变模式的使用场景主要包括两个条件:
a. 当对象创建后,其内部状态和数据不再发生任何改变;
b.对象需求被共享、被多线程频繁访问。
针对常量池的优化:当两个String对象拥有相同的值时,它们只是引用常量池(在方法区)中的同一个拷贝;
类的final定义:作为final类的String对象在系统中不可能有任何子类,这是对系统安全性的保护;
2、subString()方法的内存泄漏
Java中,String类有两个获取字串的方法,subString(int beginIndex)和subString(int beginIndex, int endIndex)。观察它的源码,结合String的结构,我们就知道取子串实质是复用了String内的char数组,只是给了新的offset和count。(new String(offset+beginIndex,endIndex-beginIndex, value))
但是,当原始字符串数组很大,每次截取的范围很小,这种做法虽然提高了运行速度,但是牺牲了大量的内存空间。可以说,String的这个构造函数是使用了以空间换时间的策略。虽然上述的这个构造方法是String类的private方法,我们并不会直接使用,但是还是得了解String内哪些方法由于使用了它而存在内存泄漏的风险。例如toString,concat,replace,substring,toLowerCase,toUpperCase,valueOf。
3、字符串分割与查找
(1)String类提供了split()方法:public String[] split(String regex),但是性能不是很出色,1w次调用3703ms
(2)JDK提供StringTokenizer: public StringTokenizer(String str, String delim):
StringTokenizer st = new StringTokenizer(str,";");
for(int i = 0;i<10000;i++){
if(st.hasNextTokenizer()){
st.nextTokenizer();
}
st = new StringTokenizer(str,";");
}
1w次调用2704ms
(3)使用indexOf+subString的方法自己分割,indexOf很快,前面提到subString的执行速度也很优秀,因此该方法执行1w次671ms
可以看到,前三种方法的功能类似,但是性能依次提高,代码复杂度也提高,具体用哪一种方法视情况而定。
(4)高效率的charAt()方法
我们经常使用startWith和endWith方法,但是有时候如果高频调用且对效率要求较高的情况下,也可以用charAt()来取代,这样性能几乎可以翻倍提升。
4、StringBuffer和StringBuilder
对于一个String要进行多次累加的情况,我们会选择StringBuffer或者StringBuilder的append方法来实现,因为如果用String加法来做拼接的话,会不断创建新的String对象。
StringBuffer和StringBuilder都继承了AbstractStringBuilder这个抽象类,拥有几乎相同的对外接口,最大不同在于StringBuffer对几乎所有的方法做了同步,StringBuilder没有做任何同步。因此,StringBuilder的性能更出众,但是非线程安全的。
这两个类都有带容量的构造函数,不指定容量时,默认16字节,如果需要的容量超过了初始化的数组长度,那么需要进行扩容,扩容时就将原有的容量大小翻倍,申请新的连续空间,并将原数组的内容复制到这个新的数组,因此,如果频繁进行扩容操作,会浪费性能开销,如果能够预估的话,一开始指定容量是正确的做法。
3.2 核心数据结构
1、List接口
最常见的三种List实现是ArrayList,Vector,LinkedList都是实现了List接口。
ArrayList和Vector使用了数组实现,可以认为是封装了内部数组的增删改等操作,两者的区别仅在于Vector对绝大部分方法做了同步,理论上ArrayList性能更优,但实际差距不明显。
LinkedList是使用了双向链表的数据结构,链表内有个header表项,它的后继是第一个元素,前继是最后一个元素。
接下来是ArrayList和LinkedList各种操作的性能比较:
(1)增加元素到列表尾端
ArrayList首先判断数组大小够不够,足够的话直接赋值,不够的话扩容,扩容时会取当前大小的1.5倍和最小需求容量的较大值,然后再进行原值的搬移,再增加新元素;
LinkedList则直接在header前加入新节点;
性能方面,直觉上LinkedList简单许多,但是经过测试发现,当执行5万次时,LinkedList确实明显更优,但是当执行50万次,ArrayList耗时更少。这可能是当数组规模上去后,ArrayList需要扩容的次数越来越少,而LinkedList每次都得创建新对象。因此性能这东西视情况而定。
(2)增加元素到列表任意位置
ArrayList由于是连续空间,在任意位置插入元素后,其后面的元素都得重排,等于每次插入都会调用一次System.arraycopy,相比在尾部插入只有容量不够时才调用性能差了很多。
LinkedList则因为不是连续空间,性能消耗与前者无异。
(3)删除任意位置元素
ArrayList的这个操作其实类似于任意位置增加的操作,也是得重排,意味着每次都需要复制数组,其耗时多少取决于删除的位置。
LinkedList的删除任意位置元素操作也和增加类似,主要耗时在遍历上。
性能方面,这两种操作理应类似。如果在列表头进行增加或删除,LinkedList远远优于ArrayList;如果在列表中间,LinkedList甚至还会差一些;如果在列表尾部,两者性能相差无几。
(4)容量参数
ArrayList的初始容量大小为10,每次扩容将新数组大小设为当前的1.5倍。
推荐如果列表大小是可以预计的,给定初始大小。
(5)列表的遍历
ForEach、迭代器、for循环,对于100万数据量的列表测试它们的遍历性能
String tmp;
long start = System.currentTimeMillis();
for(String s:list){
tmp = s;
}
System.out.println(System.currentTimeMillis()-start);
start = System.currentTimeMillis();
for(Iterator
it = list.iterator();it.hasNext();){
tmp = it.next();
}
System.out.println(System.currentTimeMillis()-start);
start = System.currentTimeMillis();
for(int i = 0;i
| List类型 | ForEach | Iterator | for循环 |
| ArrayList | 63ms | 47ms | 31ms |
| LinkedList | 63ms | 47ms | 无穷 |
使用Iterator比较稳妥,对于ArrayList可以放心使用for循环,LinkedList则绝不可以。 总的来说,ArrayList的随机访问性能更优,LinkedList的优势仅体现在对于列表前半部进行任意位置增删时。
2、Map接口
Map接口的最主要实现类有Hashtable,HashMap,LinkedHashMap和TreeHashMap。
其中Hashtable和HashMap在实现功能上类似,但是内部有些差异:
(i)Hashtable对于大多数方法加入了同步,在方法级加入了synchronized关键字;
(ii)Hashtable不允许key或者value为null,而HashMap可以。以put方法为例,Hashtable会判断value是否为null,为null抛空指针异常,对于key会取它的hash,所以当key为null也会抛异常,而HashMap这边,没有对于value的判断,对key为null的情况调用特别的put方法,直接遍历table[0]的链表,如果存在key为null的节点,替换值,否则新加入节点;
(iii)内部算法上,他们对于key的hash算法和hash值到内存索引的映射算法不同。
容量参数
HashMap除了数组大小initialCapacity还有个负载因子loadFactor,HashMap会使用大于等于initialCapacity的且是2的指数次幂的最小整数作为数组大小,负载因子又叫做填充比,=元素大小/内部数组总大小。默认情况,initialCapacity=16,loadFactor=0.75。当当前数组的元素个数达到阈值后,hashmap会进行扩容和数据搬移,这个操作会遍历整个HashMap。
3、Set接口
| Set类型 | 对应Map | 特点 |
| HashSet | HashMap | 基于Hash的快速元素插入,元素间无顺序 |
| LinkedHashSet | LinkedHashMap | 基于Hash的快速元素插入,同时维护着元素插入集合时的顺序。遍历集合时,总是按照先进先出的顺序排序 |
| TreeSet | TreeMap | 基于红黑树的实现,有着高效的基于key的排序算法 |
3.3 使用NIO提升性能
I/O肯定不及内存速度快,因此经常成为系统的性能瓶颈。InputStream和OutputStream是基于流的I/O实现,它们以字节为单位处理数据。NIO是New I/O的简称,从Java 1.4开始引入,特点如下:
(1)为所有原始类型提供Buffer;
(2)使用Java.nio.charset.Charset作为字符集编解码方案;
(3)增加Channel对象,作为新的原始I/O抽象;
(4)支持锁和内存映射文件的文件访问接口;
(5)提供了基于Selector的异步文件I/O
NIO是基于块的,它以块为基本单位处理数据。
这边简单罗列NIO和IO的区别,具体应用以后补上:
| IO | NIO |
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |
3.4 引用类型
强引用:普通的应用方式,类似StringBuffer str = new StringBuffer("hello world");强引用可以直接访问对象,且所引用对象不会被GC回收,不过可能导致内存泄漏。
软引用:可以通过java.lang.ref.SoftReference来使用软引用,一个被软引用的对象不会被JVM很快回收,JVM在发现堆使用达到阈值时,才会回收软引用对象。
弱引用:在GC时,只要发现弱引用,不管对空间是否足够,都会对该对象进行回收。
虚引用:被虚引用的对象和没有被引用是差不多的,随时都可能被GC回收,当试图调用虚引用的get()方法获取强引用时,总是会失败。
3.5 有助于改善性能的技巧
(1) 慎用异常:异常捕获也是要消耗性能的,尽量避免在循环内部try-catch
(2) 使用局部变量:局部变量保存在栈中,而静态变量、实例变量等都存储在堆中,因此如果是循环中使用的变量,或者频繁调用的变量,尽量使用局部变量代替静态变量。
(3) 位运算代替乘除法
(4) 替换switch:有时候可以尝试用数组替换switch
(5) 一维数组代替二维数组:即使完全等价,二维数组性能也更差。
(6) 提取表达式:对于循环中多次使用到的表达式公共部分进行提取。
(7) 展开循环:我们可以换一种思路,一个循环中能不能不只做一件事,这样可以减少循环次数
for(int i = 0;i<999;i++){
arr[i] = i;
}
for(int i = 0;i<999;i+=3){
arr[i] = i;
arr[i+1] = i+1;
arr[i+2] = i+2;
}
(8) 布尔运算代替位运算:之前提到了位运算远远优于算术运算,但是注意在作为判断条件时要使用布尔运算,因为像&&和||都会有优化,不会进行多余运算。 (9) 使用arrayCopy():数组复制使用频率很高,jdk中有个native方法arrayCopy(),性能可以比一般方法快上8倍。
(10) 使用Buffer进行IO操作:直接使用FileInputStream和FileOutputStream或直接使用FileReader和FileWriter,性能要差于套上Buffer。简单来说
DataOutputStream dos = new DataOutputStream(new FileOutputStream("C:\\test.txt"));
DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("C:\\test.txt")));
DataInputStream ios = new DataInputStream(new FileInputStream("C:\\test.txt"));
DataInputStream ios = new DataInputStream(new BufferedInputStream(new FileInputStream("C:\\test.txt")));
FileWriter fw = new FileWriter("C:\\test.txt"));
FileWriter fw = new BuffereFileWriter(new FileWriter("C:\\test.txt")));
FileReader fr = new FileReader("C:\\test.txt"));
FileReader fr = new BuffereFileReader(new FileReader("C:\\test.txt")));
(11) 使用clone()代替new():Object.clone()方法可以绕过对象构造函数,快速复制一个对象实例,默认情况下,clone()只是生成原对象的浅拷贝,如果需要深拷贝,需要重新实现clone()方法。























 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









