






------- android培训、java培训、期待与您交流! ----------
第一部分 集合框架中能用到的数据结构
一.数组

二.链表
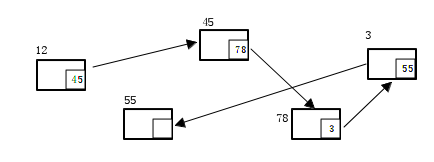
三.哈希表

1.集合框架中的哈希表底层是用对象数组+链表的数据结构实现的。
2.哈希值到索引的映射使用的算法为除模取余法。
3.当产生哈希冲突时(即哈希函数产生了相同的索引时),若内容都不相同则把这个元素插入到此数组索引对应的链表头部,并让数组索引指向这个元素。
4.哈希表确定元素内容是否相同的方式:
1>判断的是两个元素的哈希值是否相同,如果相同在判断两个对象的内容是否相同。
2>判断的哈希值是否相同,其实判断的是对象的hashCode()方法,判断内容是否相同,用的是对象的equals()方法。
注4:如果哈希值不同,是不需要再判断equals()的。
5.当使用hash结构的集合存储自定义对象时,我们要覆盖存储对象的类的hashCode()和equals()方法。
覆盖equals()的要求为:若两个对象内容相同则返回true,否则返回false。
覆盖hashCode()的要求为:若两个对象内容相同返回的哈希值必须相同;若内容不同返回的哈希值要尽量相同。
示例代码:
class Person{
private int age;
private String name;
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (!(obj instanceof Person))
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
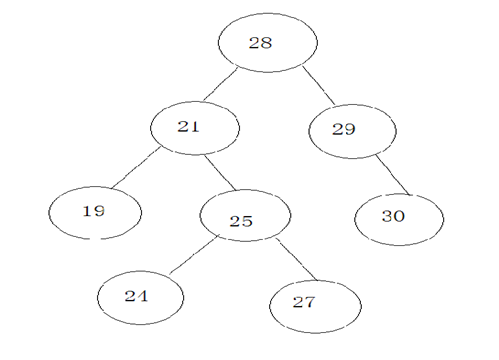
}四.二叉树
第二部分 集合概述
一.集合类的由来
对象用于封装特有数据,对象多了需要存储,如果对象的个数不确定就是用集合容器进行存储。
二.集合特点
1.用于存储对象的容器
2.集合的长度是可变的
3.集合中不可以存储基本数据类型
注二:数组的特点:
1.数组的长度不可变
2.数组既可以存储基本数据类型,也可以存储对象
三.集合框架
集合容器因为内部的数据结构不同,有多种具体容器。
这些容器不断的向上抽取,就形成了集合框架。
集合框架的顶层为Collection接口。
第三部分 Collection
一.概述
Collection是集合框架的顶层接口。其下有两个子接口:List(列表),Set(集)
接口关系:
Collection
|------List //元素可以重复
|------Set //元素不可重复
二.Collection接口中的常见操作
1.添加
boolean add(Object obj);//添加一个元素
boolean addAll(Collection collection);//将指定 collection 中的所有元素都添加到此 collection 中
2.删除
boolean remove(Object obj);//删除指定元素
boolean removeAll(Collection collection);//将两个集合中相同的元素从调用此方法的集合中删除
void clear();//移除此 collection 中的所有元
3.判断
boolean contains(Object o);//判断是否包含指定元素
boolean containsAll(Collection collection);//是否包含collection中的所有元素
boolean isEmpty();//集合是否为
4.获取
int size();//获取元素个数
Iterator iterator();//取出元素的方式:迭代器
5.其他
boolean retainAll(Collection collection);//去交集,保留和指定集合相同的元素而删除不同元素。和removeAll功能正好相反
Object[] toArray();//将集合转成数组
T[] toArray(T[] a);//将集合转成指定类型的数组。例如:String[] y=x.toArray(new String[0]);
三.示例代码:
Collection coll1=new ArrayList();
Collection coll2=new ArrayList();
coll1.add("abc1");
coll1.add("abc2");
coll1.add("abc3");
coll1.add("abc4");
coll2.add("abc2");
coll2.add("abc5");
coll2.add("abc6");
coll1.retainAll(coll2);//运行结果为 abc2<span style="color: rgb(63, 127, 95); font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);"> </span>第四部分 遍历
一.Iterator
1.概述
迭代是取出集合中元素的一种方式。
当不足以用一个函数来描述,需要用多个功能来体现,所以就将取出这个动作封装成一个对象来描述。就把取出方式定义在集合的内部,这样取出方式就可以直接访问集合内部的元素。
每个集合的子类的iterator方法返回的迭代器对象所对应的类都是内部类。
而每一个容器的数据结构不同,所以取出的动作细节也不一样。但是都具有共性内容: 判断和取出。那么就可以将这些共性抽取。
那么这些内部类都符合一个规则(或者说都抽取出来一个规则)。该规则就是Iterator。通过一个对外提供的方法:iterator();,来获取集合的取出对象。
因为Collection中有iterator方法,所以每一个子类集合对象都具备迭代器。
2.迭代的常见操作
hasNext();//有下一个元素,返回真
next();//取出下一个元素,当取到最后一个元素再调用时会发生异常
remove();//移除,
注2:在迭代时循环中next调用一次,就要hasNext判断一次。
3.使用:
1>获取迭代器对象
Collection coll=new ArrayList();
Iterator it=coll.iterator();//获取一个迭代器,用于取出集合中的元素。
2>取出集合元素
方式一:在取完集合中的元素后释放迭代器,建议使用
for(Iterator it = coll.iterator();it.hasNext(); ){
System.out.println(it.next());
}
方式二:在取完集合中的元素后迭代器让然可用
Iterator it = coll.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
4.迭代注意事项
1>迭代器在Collcection接口中是通用的,它替代了Vector类中的Enumeration(枚举)。
2>迭代器的next方法是自动向下取元素,要避免出现NoSuchElementException。 3>迭代器的next方法返回值类型是Object,所以要记得类型转换。
4>在迭代过程中,如果集合对元素进行了操作,会引发并发修改异常:
并发修改异常代码示例:
Iterator<String> it= sets.iterator();
while(it.hasNext()){
String obj=it.next();
if(obj.equals("abc3")){
it.remove();
}
}二.ListIterator
1.概述
ListIterator是List集合特有的迭代器,是Iterator的子接口。
在使用迭代器的迭代还没完成时,如果使用集合的方法对所迭代的集合进行修改操作,会引发并发修改异常ConcurrentModificationException。
所以此时只有使用迭代器的方法来进行操作才不会引发异常。但是Itrator的方法是有限的,只能进行判断、取出和删除的操作。
如果想要进行更多其他的操作,就需要使用其子接口:ListIterrator。该接口只能通过List集合的ListIterator方法获取。
此外,ListIterator还能按任一方向遍历列表、迭代期间修改列表,并获得迭代器在列表中的当前位置。ListIterator 没有当前元素;它的光标位置 始终位于调用 previous() 所返回的元素和调用 next() 所返回的元素之间。
2.ListIterator的方法
1>添加:
void add(Object obj);//将指定的元素插入列表
2>删除:
void remove();//用指定元素替换 next 或 previous 返回的最后一个元素
3>修改:
void set(Object obj);//用指定元素替换 next 或 previous 返回的最后一个元素
4>判断:
boolean hasNext();//逆向遍历列表,列表迭代器有多个元素,则返回 true
boolean hasPrevious();//逆向遍历列表,列表迭代器有多个元素,则返回 true
5>获取元素:
Object next();//返回列表中的前一个元素
Object previous();//返回列表中的前一个元素
6>获取索引:
int nextIndex();//返回对 previous 的后续调用所返回元素的索引
int previousIndex();//返回对 previous 的后续调用所返回元素的索引
注2:示例代码:在迭代的过程中,使用迭代器自己的方法对元素进行操作不会引发异常:
Iterator<String> it= sets.iterator();
while(it.hasNext()){
String obj=it.next();
if(obj.equals("abc3")){
it.remove();
}
}三.Enumeration
1.概述
这是Vector和Hashtable特有的取出方式。
其实枚举和迭代是一样的。因为枚举的名称以及方法的名称都过长。所以被迭代器 取代了。
2.操作方法
boolean hasMoreElements();//测试枚举重是否还有元素
Object nextElement();//返回枚举的下一个元素
3.获取枚举的方式
Enumeration elements();//此方法只有Vector和Hashtable有
第五部分 List
一.概述
List通常允许重复的元素。
List是有序的 collection,这里的有序指的是插入时的顺序。
此接口可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引访问元素,并搜索列表中的元素。
List
|--ArrayList:底层的数据结构使用的是数组结构。特点:查询速度很快。但是增删稍慢。线程不同步。
|--LinkedList:底层使用的是链表数据结构。特点:增删速度很快,查询稍慢。
|--Vector:底层是数组数据结构。线程同步。被ArrayList替代了。
二.List的特有常见方法:有一个共性就是可以操作索引
1.添加:
void add(index,elementt);//在列表的指定位置插入指定元素
boolean addAll(index,collection);//将指定 collection 中的所有元素都插入到列表中的指定位置
2.删除:
Object remove(index);//移除列表中指定位置的元素
3.修改:
Object set(index,element);//用指定元素替换列表中指定位置的元素
4.获取:
Object get(index);//返回列表中指定位置的元素
int indexOf(object);//返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1
int lastIndexOf(object);//返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1
List subList(from,to);//获取列表;包括from,不包括to
ListIterator listIterator();//获取列表迭代器
ListIterator listIterator(index);//获取从指定位置开始的列表迭代器
注二:List特有的取出方式之一:
<pre name="code" class="java">for(int i=0;i<list.size();i++){
list.get(i);
}List特有的取出方式之二:
ListIterator lit=list.listItertor();
while(lit.hasNext()){
System.out.println(lit.next());
}三.Vector
1.概述
Vector 类可以实现可增长的对象数组,可以使用整数索引进行访问,Vector 的大小可以根据需要增大或缩小。
每个向量会通过维护 capacity 和 capacityIncrement 来优化存储管理。capacity 大于或等于向量的大小;这个值通常比后者大些,因为随着将元素添加到向量中,其存储将按 capacityIncrement 的大小增加存储块。应用程序可以在插入大量元素前增加向量的容量,这样就减少了增加的重分配的量。
2.特有方法:
1>添加
void addElement(Object obj);//将指定的元素添加到此向量的末尾
void insertElementAt(Object obj, int index);//将指定对象插入到指定索引处
2>删除
boolean removeElement(Object obj);//移除变量的第一个(索引最小的)匹配项
void removeElementAt(int index);//删除指定索引处的元素
void removeAllElements();//移除全部元素
3>修改
void setElementAt(Object obj, int index);//将index 处的元素设置为指定对象
4>获取
Object elementAt(int index);//返回指定索引处的元素
Object firstElement();//返回此向量的第一个元素
Object lastElement();//返回此向量的最后一个组件
Enumeration elements();//获取此向量的枚举对象
int capacity();// 获取此向量的当前容量
四.LinkedList
1.概述
LinkedList除了实现 List 接口外,LinkedList 类还为在列表的开头及结尾 get、remove 和 insert 元素提供了统一的命名方法。这些操作允许将链接列表用作堆栈、队列或双端队列。
此类实现 Deque 接口,为 add、poll 提供先进先出队列操作,以及其他堆栈和双端队列操作。
2.特有方法
1>添加
void addFirst(E e);//将指定元素插入此列表的开头。
void addLast(E e);//将指定元素添加到此列表的结尾。
boolean offer(E e);//将指定元素添加到此列表的末尾。
boolean offerFirst(E e);//在此列表的开头插入指定的元素。
boolean offerLast(E e);//在此列表末尾插入指定的元素。
2>删除
E removeFirst();//移除并返回此列表的第一个元素。
E removeLast();//移除并返回此列表的最后一个元素。
boolean removeFirstOccurrence(Object o);//从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表时)。
boolean removeLastOccurrence(Object o);//从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表时)。
E poll();//获取并移除此列表的头(第一个元素)
E pollFirst();//获取并移除此列表的第一个元素;如果此列表为空,则返回 null。
E pollLast()获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。
3>获取元素
E getFirst();//返回此列表的第一个元素。
E getLast();//返回此列表的最后一个元素。
E peek();//获取但不移除此列表的头(第一个元素)。
E peekFirst();//获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。
E peekLast();//获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。
E element();//获取但不移除此列表的头(第一个元素)。
4>获取迭代器
Iterator<E> descendingIterator();//返回以逆向顺序在此双端队列的元素上进行迭代的迭代器。
5>堆栈操作
E pop();//从此列表所表示的堆栈处弹出一个元素。
void push(E e);//将元素推入此列表所表示的堆栈。
五.ArrayList
1.概述
ArrayList除了实现 List 接口外,还提供一些方法来操作内部用来存储列表的数组的大小。
在添加大量元素前,应用程序可以使用 ensureCapacity 操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。
2.特有方法:
Object clone();//返回此 ArrayList 实例的浅表副本。
void ensureCapacity(int minCapacity);//增加此 ArrayList 实例的容量,以确保它至少能够容纳minCapacity所指定的元素数。
void removeRange(int fromIndex, int toIndex);//移除列表中索引在fromIndex(包括)和toIndex(不包括)之间的所有元素。
void trimToSize();//将此 ArrayList 实例的容量调整为列表的当前大小。
第六部分 Set
一.Set概述
Set:是一个不包含重复元素的 collection
|--HashSet:底层数据结构是哈希表。线程不同步。是无序的。
|--TreeSet:底层数据结构是二叉树。线程不同步。是有序,自定义顺序。
Set接口中的方法和Collection一致。
二.HashSet
保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true。
HashSet的方法和Set一致。
使用HashSet必须覆盖hashCode()和equals()方法。
三.LinkedHashSet
1.LinkedHashSet是迭代时有序的Set接口的哈希表和链表的实现。
LinkedHashSet维护者一个运行于所有条目的双重链表。次链表定义了迭代顺序为插入顺序。插入顺序不受在Set中重新插入的元素的影响。
2.使用方式为:
1>LinkedHashSet lhs=new LinkedHashSet();
2>HashSet hs=new LinkedHashSet();
这两种方式都可实现有序。
四.TreeSet
1.TreeSet有指定顺序(如按照字典顺序)
使用元素的自然顺序对元素进行排序,或根据创建Set时提供的Comparator进行排序。
TreeSet使用Comparable的compareTo或Comparator的compare方法对所有的元素进行比较。即使equals()方法不准确也不会影响结果。
TreeSet判断元素唯一性的方式就是根据compare方法的返回结果是否是0,是0就相同,不存。
2.TreeSet使用的底层数据结构是二叉树,更具体来说是平衡二叉树(又叫红黑树)。
3.TreeSet对元素进行排序:
1>方式一:
让元素自身具备比较功能,元素就需要实现Comparable接口,覆盖compareTo()方法。
public class Person implements Comparable {
public int compareTo(Object o) {
.................
}
}2>方式二:
如果不想按照对象中应经具备的自然顺序进行排序,或者对象中不具备自然顺序。
此时,要让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare()方法,再将该类对象作为参数传递给TreeSet集合的构造方法。
public TreeSet(Comparator comparator);
传入的比较器实现Comparator的compare()方法,
public class PersonComparator implements Comparator {
public int compare(Object o1, Object o2) {
.....................
}
}第七部分 比较和排序
一.Comparable
1.Comparable接口对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。
因此,要想对存储的在集合中的对象进行排序,可以实现Comparable接口,并且覆盖它的compareTo方法,此方法用于实现大小比较。
2.实现compareTo()方法时要完成的功能
比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
3.示例代码:先按照年龄排序再按照姓名的字典顺序排序
class Person implements Comparable{
private String name;
private int age;
public int compareTo(Object o) {
//如果传入的是同一对象,则this和o必然相等
if (this == o)
return 0;
//如果没传入对象抛出空指针异常
if(o==null)
throw new NullPointerException("传入的对象为空");
//如果传入的对象与本对象类型不一致抛出
if(getClass() != o.getClass())
new InputMismatchException("输入的类型不匹配");
//把出入对象转换为Person类型
Person p=(Person) o;
//先判断主要条件,如果住条件相等再判断辅助条件
int temp=this.age-p.age;
return temp==0?this.name.compareTo(p.name):temp;
}
}二.Comparator
1.Comparator提供对某个对象collection进行整体排序的比较函数。可以将Comparator传递给:
Collection.sort()方法,实现对List排序进行精确控制
Arrays.sort()方法,实现对数组排序进行精确控制
TreeSet的构造函数,实现对TreeSet集合进行精确控制
TreeMap的构造函数,实现对TreeMap进行精确控制。
传入的Comparator对象必须覆盖compare方法。
2.compare方法
int compare(Object o1, Object o2)方法用作比较用来排序的两个参数。根据第一个参数小于、等于或大于第二个参数分别返回负整数、零或正整数。
3.示例代码:
public class PersonComparator implements Comparator {
public int compare(Object o1, Object o2) {
// 如果传入的是同一对象,则this和o必然相等
if (o1 == o2)
return 0;
// 如果没传入对象抛出空指针异常
if (o1 == null ||o2==null)
throw new NullPointerException("传入的对象为空");
// 如果传入的对象与本对象类型不一致抛出
if (o1.getClass() != o2.getClass())
new InputMismatchException("输入的类型不匹配");
// 把出入对象转换为Person类型
Person p1 = (Person) o1;
Person p2 = (Person) o2;
int temp=p1.getAge()-p1.getAge();
return temp==0?p1.getName().compareTo(p2.getName()):temp;
}
}三.Collections.sort()
1.Collections.sort(List list)
根据元素的自然顺序 对指定列表按升序进行排序。列表中的所有元素都必须实现 Comparable 接口。此外,列表中的所有元素都必须是可相互比较的,即覆盖了compareTo方法。
2.Collections.sort(List list,Comparator c)
根据指定比较器产生的顺序对指定列表进行排序。此列表内的所有元素都必须可使用指定比较器相互比较,通过覆盖compare方法。
四.Arrays.sort()
1.Arrays.sort(Object[] a)
根据元素的自然顺序对指定对象数组按升序进行排序。数组中的所有元素都必须实现 Comparable 接口。此外,数组中的所有元素都必须是可相互比较的,即覆盖了compareTo方法。
2.Arrays.sort(T[] a, Comparator c)
根据指定比较器产生的顺序对指定对象数组进行排序。数组中的所有元素都必须是通过指定比较器可相互比较的,通过覆盖compare方法。
第八部分 Map
一.概述
1.简述:
一次添加一对元素。
Map是双列集合。
其实Map集合中存储的是键值对。
Map集合中必须保证键的唯一性。
3.Map集合的子类
Map
|--Hashtable:内部结构是哈希表,是同步的,键和值都不可为null。
|--Properties:用来存储键值对型的配置文件信息,可以和IO结合使用。
|--HashMap:内部结构是哈希表,不是同步的,允许使用null键null值。
|--LinkedHashMap:内部结构是哈希表和链表实现,迭代顺序为插入顺序。
|--TreeMap:内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
二.Map集合的常用方法
1.添加
V put(K key,V value);//返回前一个和key关联的值,如果没有返回null。存在相同键值会覆盖
void putAll(Map map);//添加一个集合
2.删除
void clear();//清空map集合
V remove(Object key);//根据指定的key,删除这个键值对
3.判断
boolean containsKey(Object key);//判断键是否存在
boolean containsValue(Object value)//判断值是否存在
boolean isEmpty();//判断是否为空
4.获取
V get(Object key);//通过键获取值,如果没有该键,返回null。当然可以通过返回null,来判断是否包含指定键
int size();//获取键值对的长度
Collection<V> values();//获取Map集合中所有的值,返回一个Collection集合
Set<Map.Entry<K,V>> entrySet();//获取集合键值对映射关系的Set
Set<K> keySet();//获取键的Set
三.Map集合的方法操作
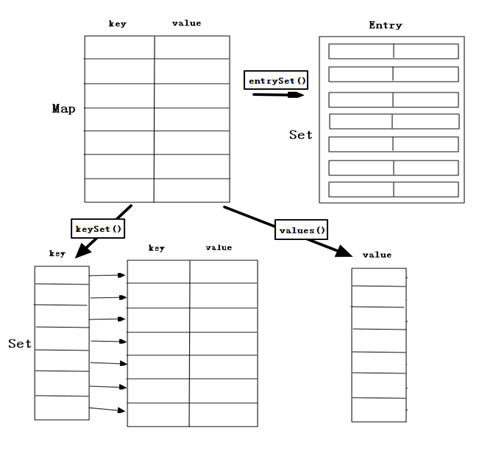
创建一个Map<Integer,String>类型的对象,并向其中插入元素,用于以下操作:
1.取出Map中的所有元素:
1>方式一:
原理:通过通过keySet方法获取map中所有键所在的Set集合,通过Set的迭代器取到每一个键,在对每个键通过map集合的get方法获取对应的值即可。
Set<Integer> keySet=map.keySet();
Iterator<Integer> it=keySet.iterator();
while(it.hasNext()){
Integer key=it.next();
String value=map.get(key);
}2>方式二:
原理:通过entrySet方法将键和值的映射关系作为对象存储到了Set集合中。而这个映射关系类型就是Map.Entry类型。其实,Entry也是一个接口,它是Map接口中的一个内部接口。
<span style="white-space:pre"> </span>Set<Map.Entry<Integer, String>> entrys = map.entrySet();
Iterator<Map.Entry<Integer, String>> it = entrys.iterator();
while(it.hasNext()){
Map.Entry<Integer, String> entry=it.next();
Integer key=entry.getKey();
String value=entry.getValue();
}2.直接获取Map中的所有值:
通过Map的values方法获取所有值的Collection对象。
<span style="white-space:pre"> </span>Collection<String> values=map.values();
Iterator<String> it=values.iterator();
while(it.hasNext()){
String value=it.next();
<span style="white-space:pre"> </span>}四.子类的使用注意:
1.HashMap、Hashtable和LinkedHashMap
对于上面的三个容器,若使用自定义对象作为键时,应该覆盖它们的hashCodehe equals方法。
2.TreeMap
对于TreeMap,若使用自定义对象作为键时,应该让自定义对象实现comparable接口并覆盖compareTo方法,或者传入一个实现了Comparator接口并覆盖compare方法的比较器对象作为TreeMap的构造方法的参数。















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









