






您可能会想,为什么要抓取LinkedIn?作为一个专业的社交平台,LinkedIn是一个数据宝库。它拥有关于专业人士、公司和工作机会的丰富信息。例如,招聘人员可以用它来寻找潜在候选人,销售团队可以用它来识别潜在客户,研究人员可以用它来进行劳动力市场分析。可能性是无穷无尽的。从人才发现、分析职业路径,到识别适合投资的公司、绘制新市场的竞争格局以及进行客户关系管理(CRM)强化,LinkedIn数据点对于公司创建更有针对性和有效的业务方法至关重要。
本文带您了解如何抓取LinkedIn公共数据以满足您的特定业务需求,包括识别投资的企业和发现人才。在最简单的形式中,网络抓取涉及自动化收集网络上可用的信息,然后可以将这些信息存储、分析或用于决策过程。在本教程中,你将学习如何使用抓取LinkedIn数据并利用Beautiful Soup。在学习了逐步抓取过程后,你还将了解Bright Data解决方案如何使 LinkedIn 抓取更快。
使用Python抓取LinkedIn
在本教程中,你将使用Python创建一个网络抓取工具,使用免费的工具如 Beautiful Soup和Requests。那么让我们开始吧!
请注意:本教程仅用于教育目的和演示技术能力。请注意,根据LinkedIn 的用户协议,抓取LinkedIn的数据是严格禁止的。任何滥用此信息来抓取 LinkedIn 的行为可能会导致你的LinkedIn账户被永久禁止或其他潜在的法律后果。请自行承担风险并自行决定。
在开始之前,请确保你的系统上安装了Python 3.7.9或更高版本。
安装 Python 后,下一步是设置抓取所需的库。这里,你将使用requests来进行 HTTP 请求,使用BeautifulSoup(BS4)来解析 HTML 内容,并使用Playwright进行浏览器交互和任务自动化。打开你的 shell 或终端并运行以下命令:

LinkedIn的结构和数据对象
在开始抓取LinkedIn之前,以下部分将讨论该网站的结构并识别你将提取的数据对象。在本教程中,你将重点抓取工作列表、用户资料、文章和公司信息:
-
工作列表包含职位名称、公司、地点和职位描述等详细信息。
-
课程信息可以包括课程标题、讲师、时长和描述。
-
公司数据可以包括公司名称、行业、规模、地点和描述。
-
文章由专业人士撰写,涵盖职业发展和行业见解等主题。
例如,如果你想更好地了解LinkedIn的工作页面的HTML结构,请按照以下步骤操作:
-
访问LinkedIn网站并登录你的账户。
-
点击顶部导航栏的工作图标。输入任何职位名称(如“前端开发人员”)并按回车键。
-
从列表中右键点击一个工作项目,然后点击检查以打开浏览器的开发者工具。
-
分析HTML结构以识别包含你要抓取的数据的标签和属性。
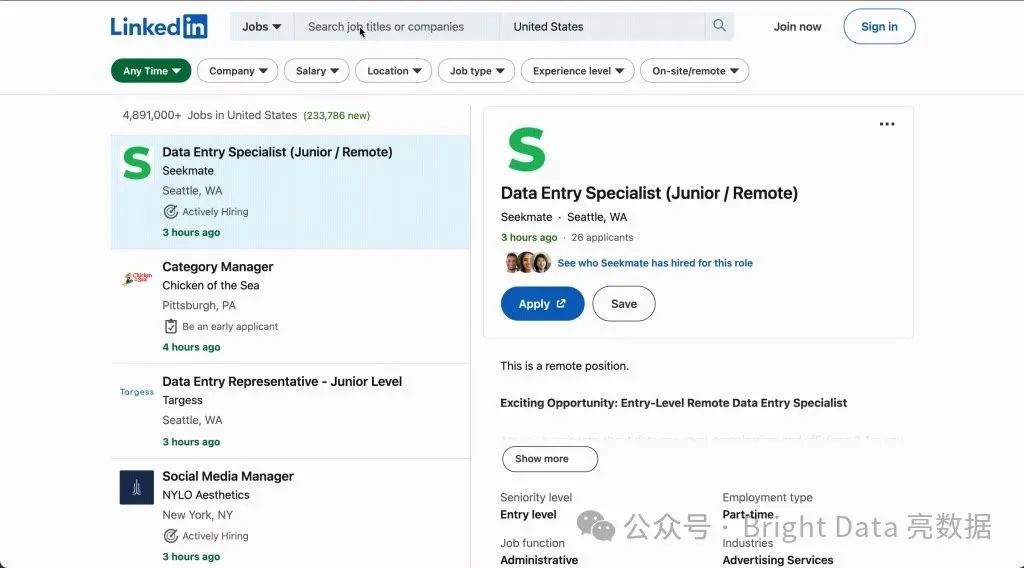
抓取工作列表
首先从LinkedIn抓取工作列表。你将使用requests来获取页面的HTML内容,并使用BeautifulSoup来解析和提取相关信息。
创建一个名为scraper_linkedIn_jobs.py的新文件,并添加以下代码(以Python为例):
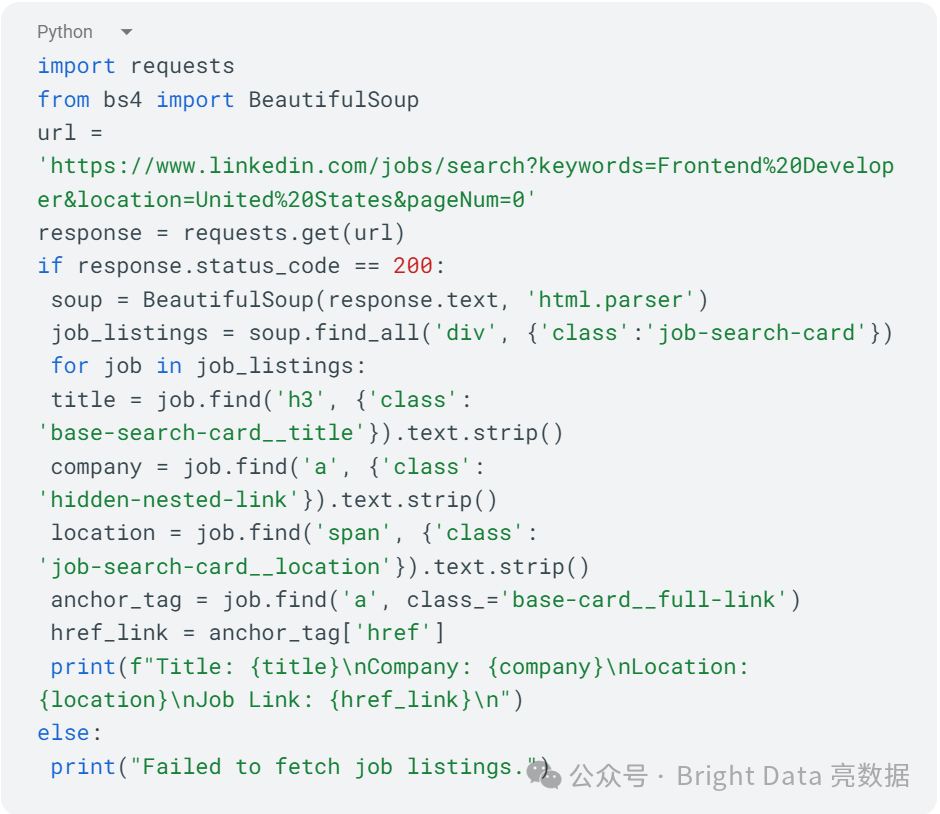
这段代码从LinkedIn搜索页面中获取美国前端开发职位的工作列表。
注意:在定义的url中,你可以使用URL参数根据自己的偏好定制工作搜索。例如,你可以将location=United%20States更改为你选择的国家,以查找特定位置的工作列表。同样,你可以将keywords=Frontend%20Developer更改为任何其他你感兴趣的职位名称,以根据不同的关键词搜索工作。此外,你可以调整“pageNum=0”以浏览搜索结果的不同页面,从而探索更多的工作机会。这些参数使你能够根据自己的标准和偏好定制工作搜索。
从 shell 或终端运行以下命令来运行代码:

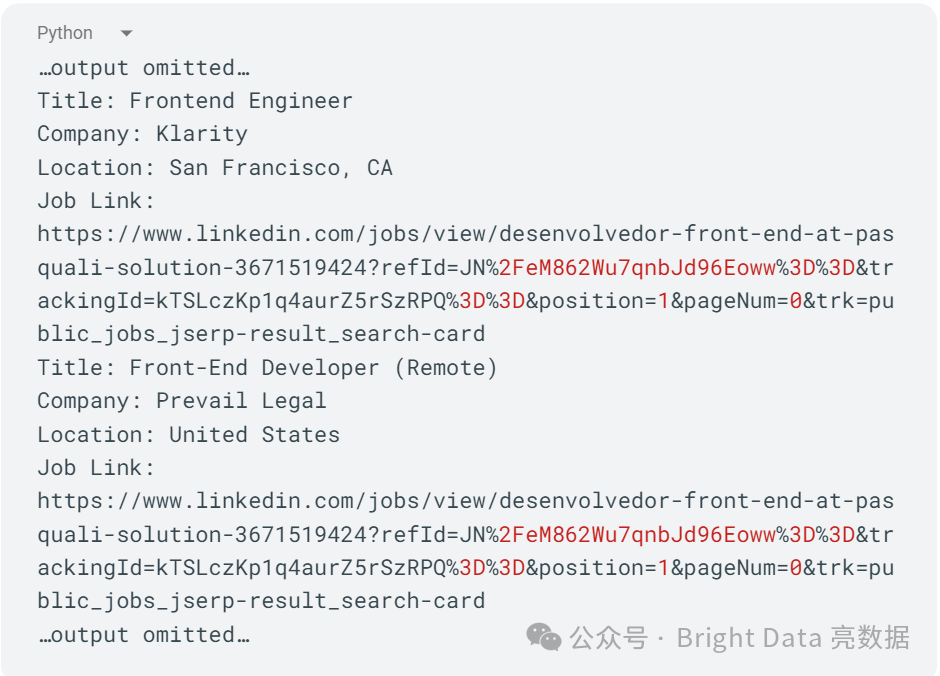
你应该会得到一个包含职位标题、公司、地点和职位链接的工作列表。结果应如下所示:
抓取LinkedIn学习
除了抓取工作列表,你还可以抓取LinkedIn学习页面的课程。
创建一个名为scraper_linkedIn_courses.py的新文件,并添加以下代码:
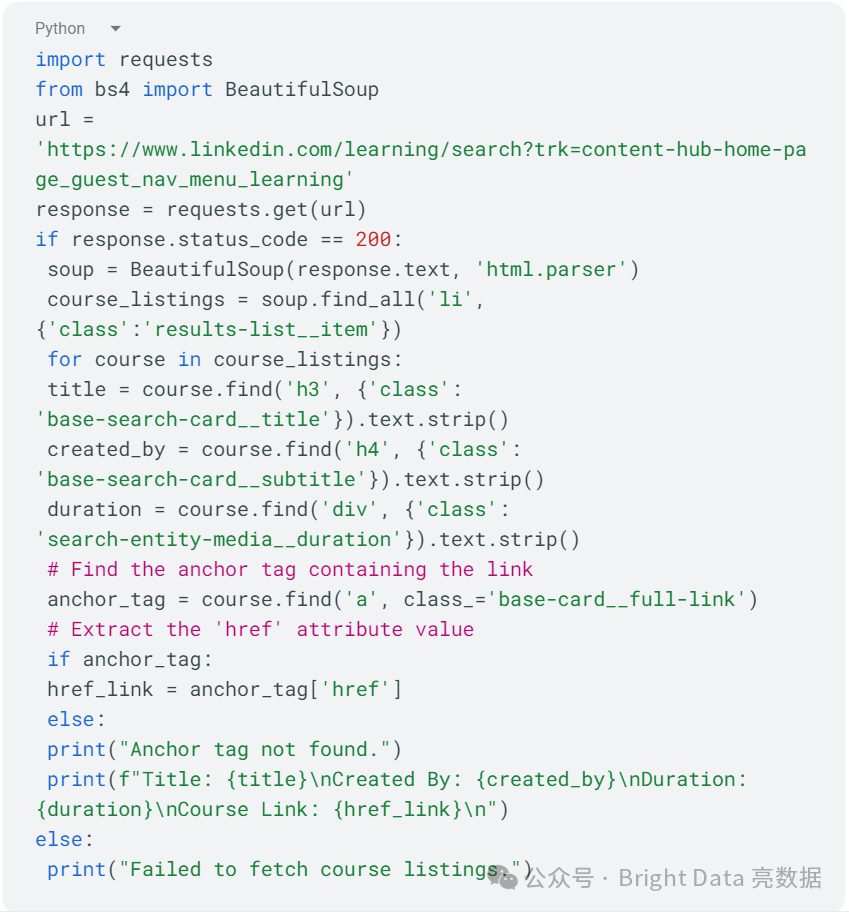
在这里,你使用requests访问 LinkedIn 的学习页面,并使用BeautifulSoup进行解析。你寻找具有results-list__item类的li元素,这些元素包含课程列表。对于每个课程,你提取并打印标题、创建者、时长和链接。如果初始请求失败,你将打印失败信息。
从 shell 或终端运行以下命令来运行代码:

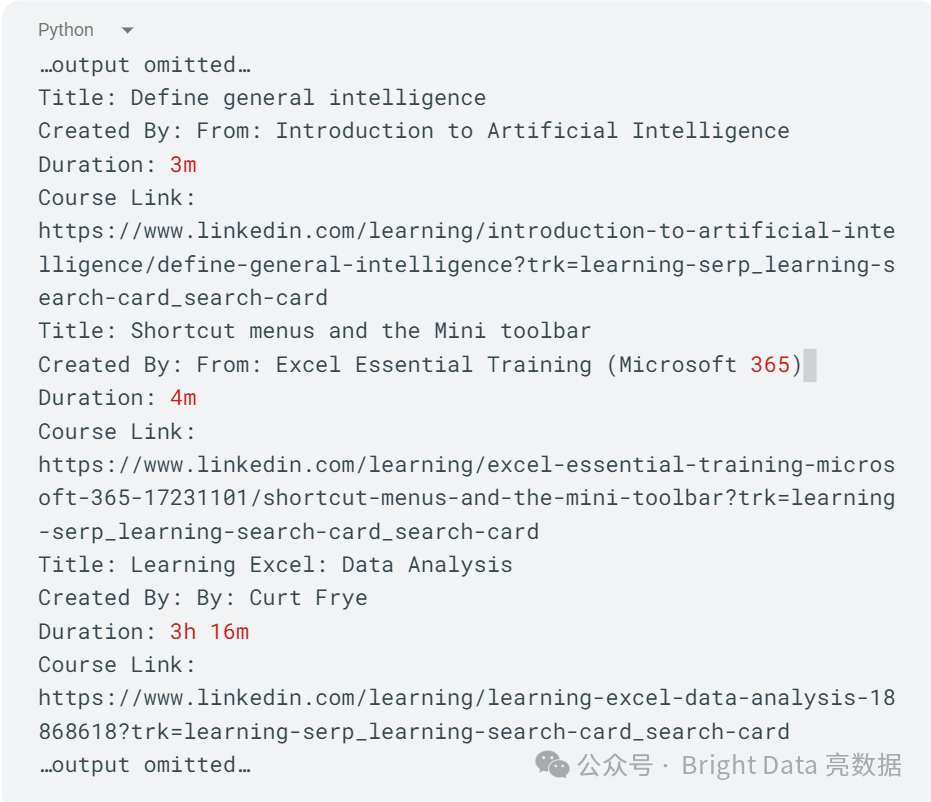
你应该会得到一个包含标题、作者和课程链接的课程列表。结果应如下所示:
抓取LinkedIn文章
你还可以抓取LinkedIn文章页面的文章数据。
为此,创建一个名为scraper_linkedIn_articles.py的新文件,并添加以下代码:
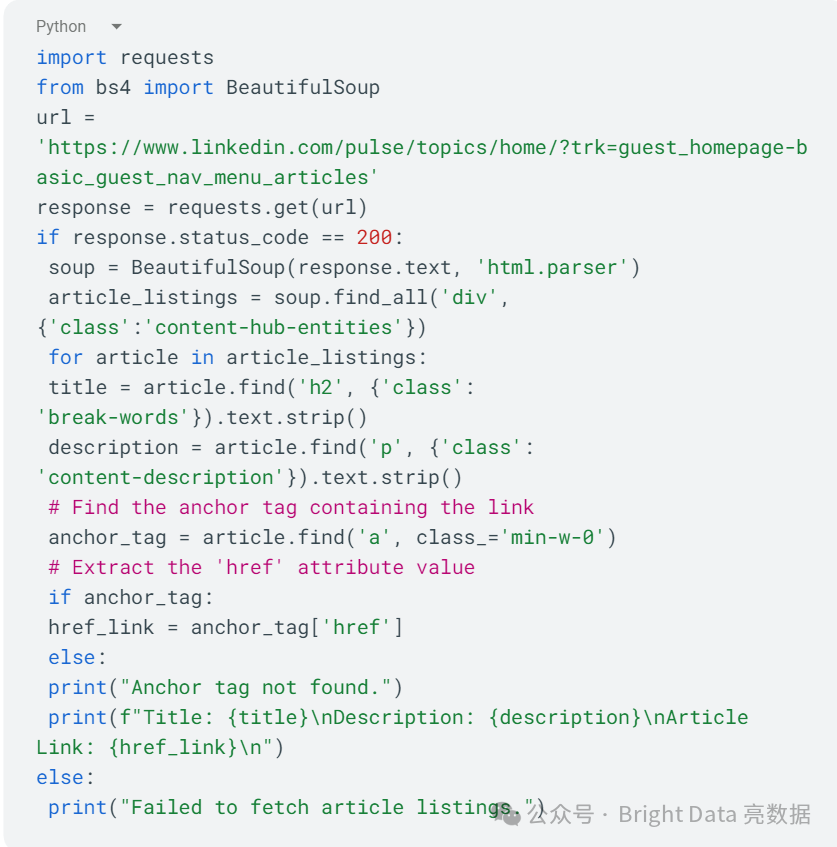
在这段代码中,你使用requests来抓取LinkedIn的页面,并使用BeautifulSoup来解析它。你正在寻找具有content-hub-entities类的div元素,这些元素包含文章列表。对于每篇文章,你提取并打印标题、描述和链接。如果初始请求失败,将打印失败信息。
从 shell 或终端运行以下命令来运行代码:

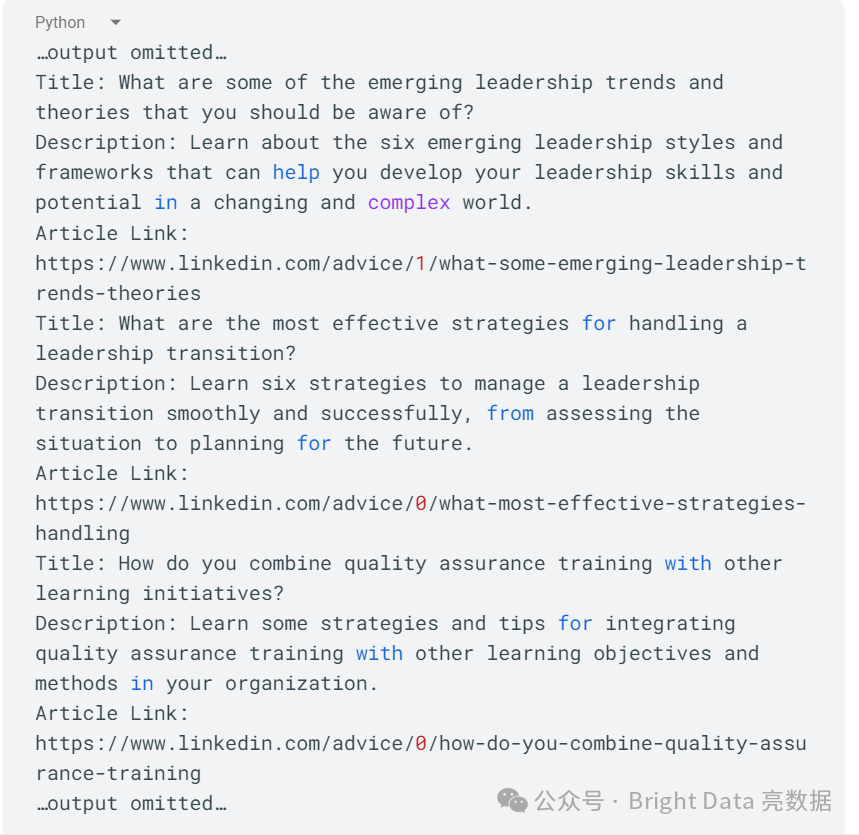
你将得到一个包含标题、描述和文章链接的文章列表。结果应如下所示:
所有本教程的代码可在GitHub仓库中找到。
抓取LinkedIn时需要考虑的事项
LinkedIn和许多其他网站一样,采用了多种技术来防止其数据被自动抓取。了解这些技术可以帮助你绕过它们,确保你的抓取活动成功:
-
分页:LinkedIn以分页形式显示搜索结果。确保你的抓取脚本处理分页以检索所有相关数据。
-
广告:LinkedIn在各个部分显示广告。确保你的抓取脚本目标是实际数据,并避免提取广告内容。
-
速率限制:LinkedIn监控在一定时间内来自某个 IP 地址的请求数量。如果请求数量超过某个限制,LinkedIn 可能会暂时或永久阻止该 IP 地址。
-
CAPTCHA:如果LinkedIn检测到某个IP地址的异常活动,可能会出现 CAPTCHA挑战。CAPTCHA设计为易于人类解决但难以为机器人解决,从而防止自动抓取。
-
登录要求:LinkedIn上的某些数据只有在登录时才可访问(例如用户资料和公司页面)。这意味着任何抓取这些数据的尝试都需要自动登录,这会被LinkedIn检测并阻止。
-
动态内容:LinkedIn使用JavaScript动态加载某些内容。这可能使抓取变得更困难,因为数据可能在页面初始加载时并不存在于HTML 中。
-
robots.txt:LinkedIn的robots.txt文件指定了允许哪些部分的站点供网络爬虫访问。虽然这并不是严格的防御技术,但忽略该文件中的指令可能会导致你的 IP 被阻止。
记住,虽然在技术上可以绕过这些技术,但这样做可能违反LinkedIn的服务条款,并可能导致你的账户被封禁。始终确保你的抓取活动是合法和道德的。
更好的选择:使用Bright Data 抓取LinkedIn
虽然手动网络抓取适用于小规模数据提取,但在大规模上会变得耗时且低效。Bright Data提供了一个更简单、更高效的替代方案,让你轻松访问大量的LinkedIn数据。
Bright Data提供了两种主要的网络抓取产品:
-
抓取浏览器:抓取浏览器 是一个基于浏览器的解决方案,可以让你像普通用户一样与网站交互。它处理JavaScript渲染、AJAX请求和其他复杂问题,使其成为抓取LinkedIn等动态网站的理想选择。
-
LinkedIn数据集:LinkedIn数据集是一个预先收集和结构化的数据集,包含LinkedIn数据,包括工作列表、用户资料和公司信息。你可以直接从Bright Data平台访问和下载数据。
设置你的Bright Data账户
-
要访问Bright Data平台上的LinkedIn数据集,请按照以下步骤操作:
-
在Bright Data网站上创建一个账户,开始并按照说明进行操作。
-
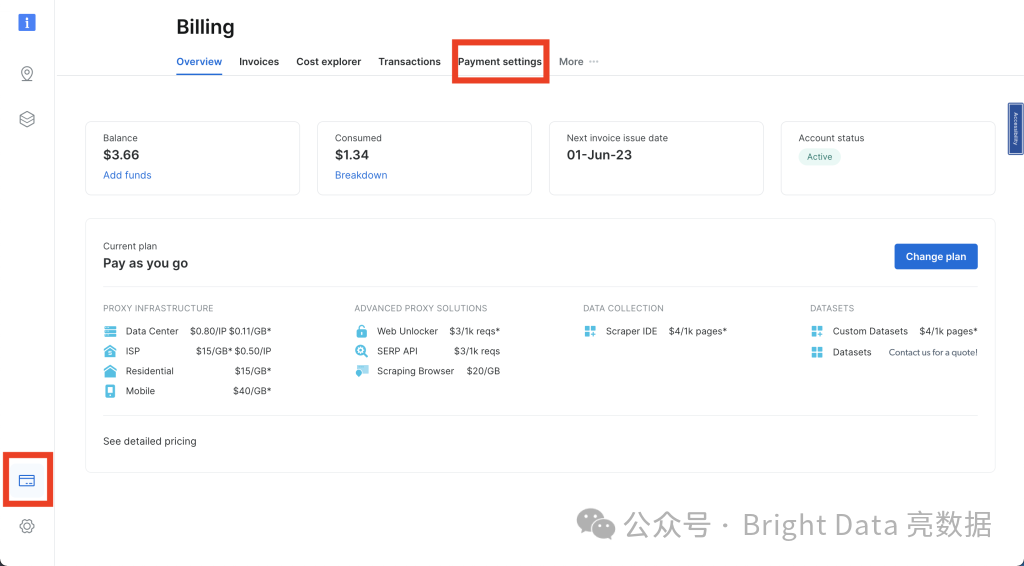
登录后,点击左侧导航面板上的信用卡图标进入账单页面。然后添加付款方式以激活你的账户:
接下来,点击图钉图标打开代理和抓取基础设施页面。选择抓取浏览器 > 开始:
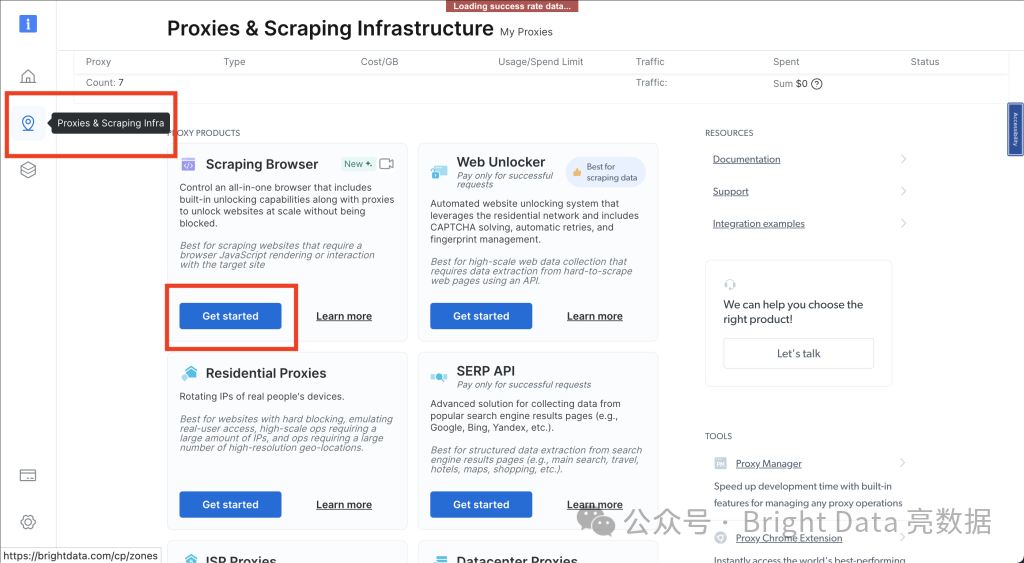
为你的解决方案命名,然后点击添加按钮:
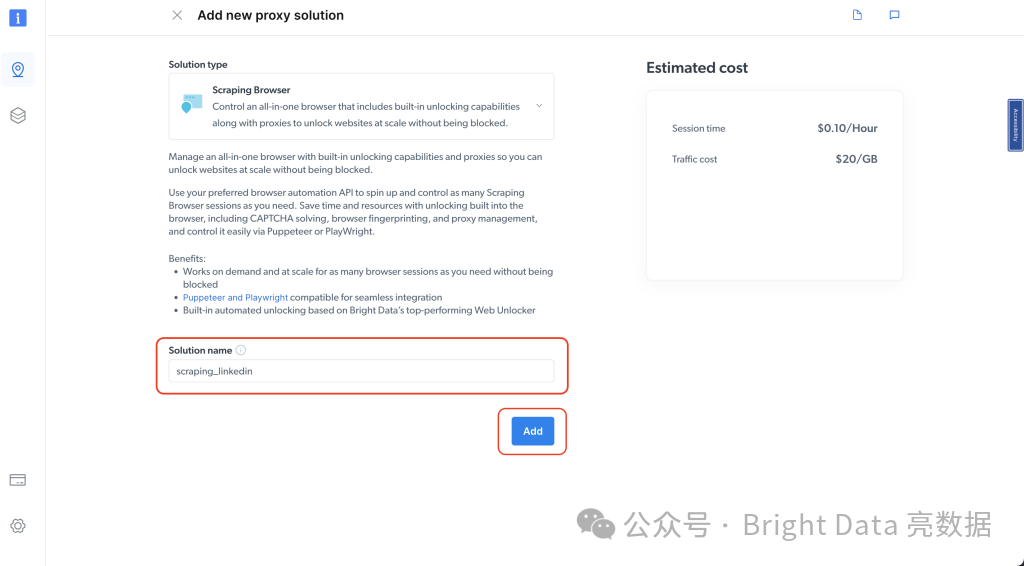
选择访问参数并记下你的用户名、主机和密码,因为你将在下一步中需要它们:
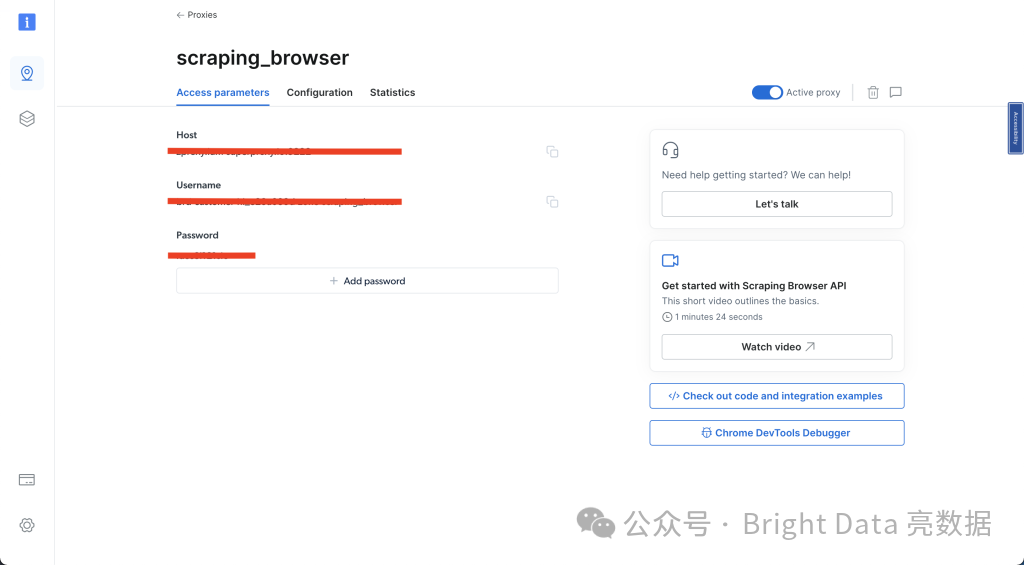
完成所有这些步骤后,你可以继续下一部分。
使用抓取浏览器抓取LinkedIn公司数据
要从LinkedIn上的公司页面抓取公司数据,请创建一个名为scraper_linkedIn_bdata_company.py的新文件,并添加以下代码:
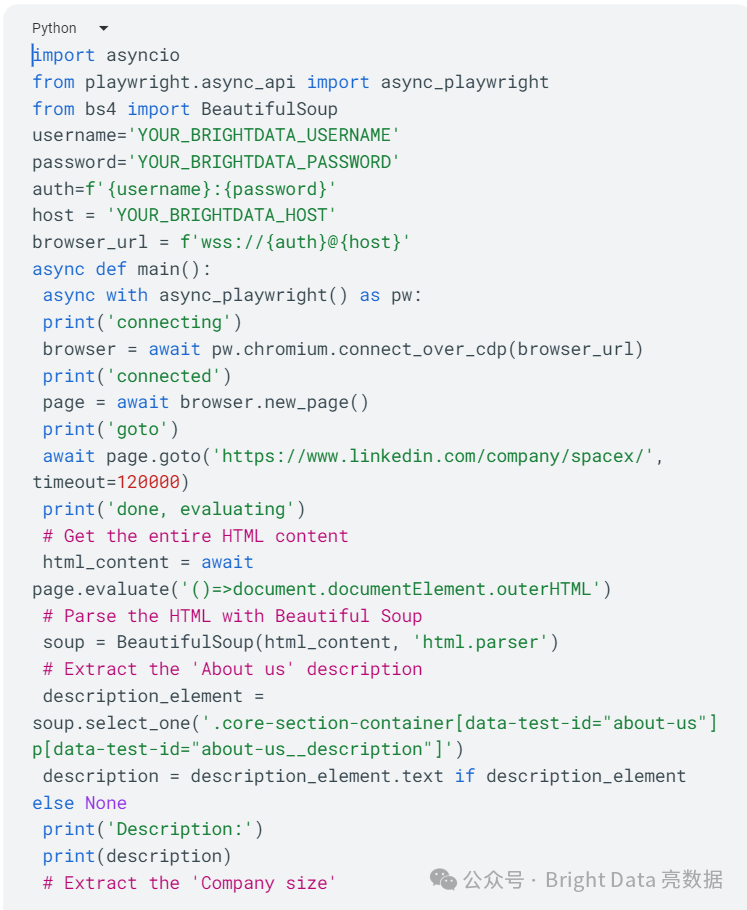
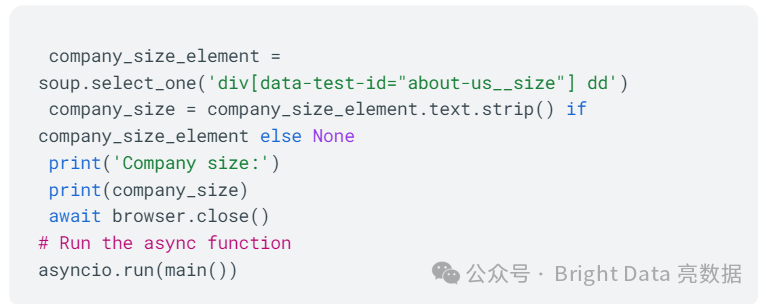
在这段代码中,你使用Playwright进行浏览器自动化。你通过代理连接到一个Chromium浏览器,导航到SpaceX的公司页面,并提取关于我们描述和公司规模。
要获取HTML内容,你使用Playwright的评估方法,然后使用Beautiful Soup 解析它,找到特定的元素并打印提取的信息。你利用Playwright的异步功能定义一个名为main()的异步函数,并用asyncio.run(main())启动脚本的执行。
注意:请确保将YOUR_BRIGHTDATA_USERNAME、YOUR_BRIGHTDATA_PASSWORD和YOUR_BRIGHTDATA_HOST替换为你的Bright Data账户的正确且特定的登录凭据。这一步对于成功认证和访问你的账户至关重要。
打开shell或终端并使用以下命令运行代码:

你应该会得到如下输出:

你用来抓取LinkedIn的初步方法可能会遇到弹出窗口和reCAPTCHA 等挑战,导致 代码被阻止。然而,使用Bright Data抓取浏览器可以帮助你克服这些障碍,确保抓取不中断。
Bright Data LinkedIn 数据集
手动抓取LinkedIn数据的另一种替代方法是购买LinkedIn数据集,这将为你提供包括用户资料和其他信息在内的有价值的个人数据。使用Bright Data LinkedIn数据集可以消除手动网络抓取的需求,节省时间,并提供准备好分析的结构化数据。
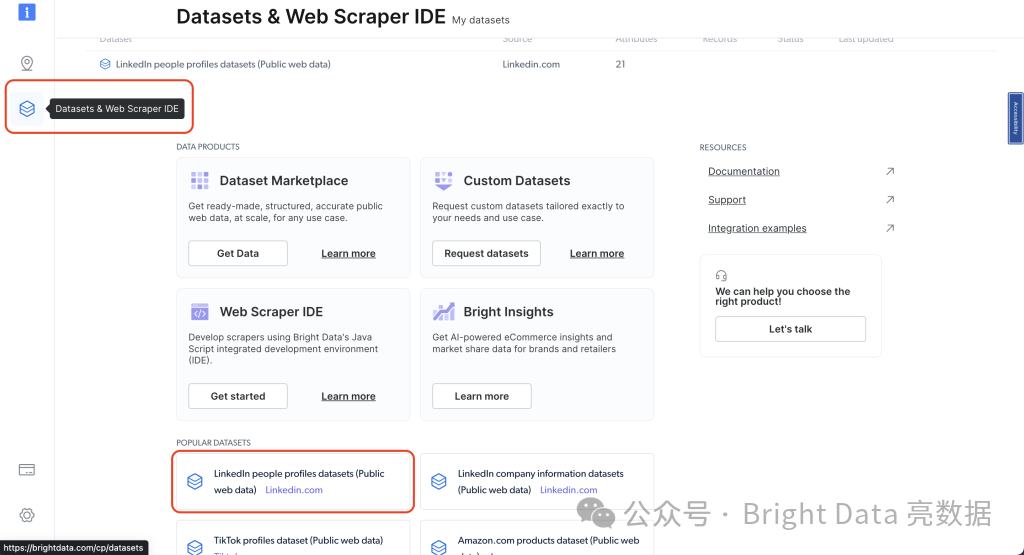
要了解有哪些数据集可用,请转到你的Bright Data仪表板,然后从左侧导航栏中点击数据集和网络抓取IDE并选择LinkedIn人员资料数据集(公共网络数据):
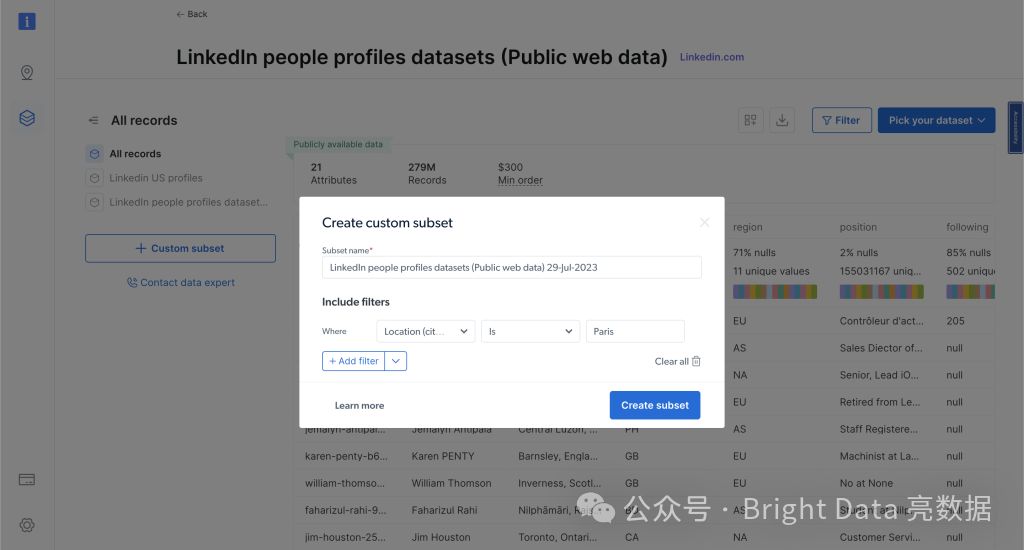
现在,你可以应用过滤器进一步细化你的选择并获取符合你标准的特定数据,然后点击“购买选项”查看费用。
定价基于你选择的记录数量,使你可以根据需要和预算调整购买。通过选择购买这些数据集,你可以显著简化工作流程,避免数据提取和收集的手动操作:
结论
在本文中,你学习了如何使用Python手动抓取LinkedIn的数据,并介绍了 Bright Data,它可以简化和加速数据抓取过程。无论你是为了市场研究、人才招聘还是竞争分析而抓取数据,这些工具和技术都能帮助你收集所需的信息。
记住,虽然手动抓取可以是一种强大的工具,但Bright Data提供了一个更简单、更高效的替代方案。通过其抓取浏览器和预先抓取的LinkedIn数据集,Bright Data可以节省你的时间和精力,让你专注于真正重要的事情:使用数据做出明智的决策。
更多博客技术文章,请点击【亮数据博客】查看。


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









