







虚基类(虚继承)
class base1:virtual public base
出现原因:假如我们有类A是父类,类B和类C继承了类A,而类D既继承类B又继承类C(这种菱形继承关系)。
当我们实例化D的对象的时候,每个D的实例化对象中都有了两份完全相同的A的数据。
因为保留多份数据成员的拷贝,不仅占用较多的存储空间,还增加了访问这些成员时的困难,容易出错,而实际上,我们并不需要有多份拷贝。
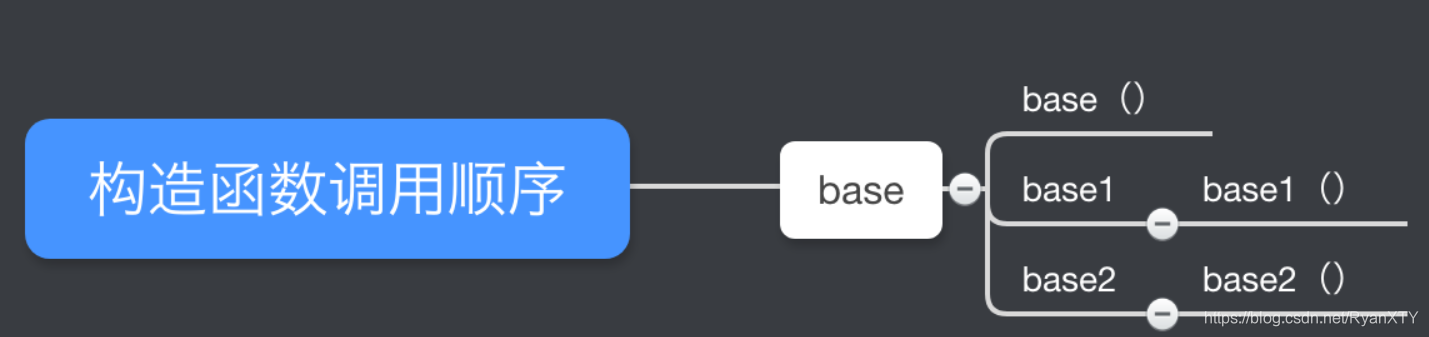
当没有使用虚继承的时候 构造函数的执行顺序是:

使用虚继承后,构造函数执行顺序是
map unordered_map 和 hashmap
1.map
基于红黑树实现,红黑树具有自动排序的功能,map 的所有元素都是 pair.因此map内部所有的数据,在任何时候,都是有序的。不允许键值重复。
2.unordered_map
基于红黑树实现,允许键值重复。记录元素的hash值,根据hash值判断元素是否相同。
【性能:unordered_map>hashmap>map】
3.hashmap
基于哈希表和链表实现 《需要知道解决哈希冲突的方案》

堆排序与快排的使用场景
堆排序比较和交换次数比快速排序多,所以平均而言比快速排序慢,也就是常数因子比快速排序大,如果你需要的是“排序”,那么绝大多数场合都应该用快速排序而不是其它的O(nlogn)算法。
但有时候你要的不是“排序”,而是另外一些与排序相关的东西,比如最大/小的元素,topK之类,这时候堆排序的优势就出来了。用堆排序可以在N个元素中找到top K,时间复杂度是O(N log K),空间复杂的是O(K),而快速排序的空间复杂度是O(N),也就是说,如果你要在很多元素中找很少几个top K的元素,或者在一个巨大的数据流里找到top K,快速排序是不合适的,堆排序更省地方。
另外一个适合用heap的场合是优先队列,需要在一组不停更新的数据中不停地找最大/小元素,快速排序也不合适















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









