






问题记录:近期客户文件最小30MB而且一次上传四张表同时解析完成之后合并交际数据字段入库,在使用 poi解析Excel项目读取Exel文件导致OOM。而且可能后面文件会更大。项目中引入的是3.17这个版本。所以本项目后来把poi改成EasyExcel对excel进行解析文档。
原因:使用poi读写文件都是基于DOM文档驱动,基于内存内存消耗非常大,数据量大的情况下很难不出现OOM。
poi 及API就不详细说明了,有兴趣可以自行找资料了解。
EasyExcel:
EasyExcel 是Alibaba集团开源的EasyExcel技术,该技术是针对Apache POI技术的封装和优化,主要解决了POI技术的耗内存问题,并且提供了较好的API使用。不需要大量的代码就可以实现excel的操作功能。
使用步骤及示例封装工具类
第一步 引入依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.0.2</version>
</dependency>简单的读写:
创建Entity封装Excel对应行列值
@Data//生成get、set方法
@NoArgsConstructor//生成无参构造
@AllArgsConstructor//生成有参构造
public class ExcelOrder {
// @ExcelProperty:指定当前字段对应excel中的那一列。index是列下标可只指定其中一种
@ExcelProperty("订单编号",index = 0)
private String orderId;//订单编号
@ExcelProperty("商品名称",index = 1)
private String tradeName;//商品名称
@ExcelProperty("成本价",index = 2)
private Double costPrice;//成本价
@ExcelProperty("销售价",index = 3)
private Double sellingPrice;//销售价
}两种方式读数据:EasyExcel.read()有多种方法有想法的自己去看
1. 匿名内部类方式
List<ExcelOrder> resultData = new ArrayList<>(); //结果集
EasyExcel.read(fileName,ExcelOrder.class ,new AnalysisEventListener<ExcelOrder>() {
//用于存储表头的信息
private Map<Integer, String> headMap;
//读取excel表头信息 ---仅限首行为表头的情况下
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
this.headMap=headMap;
System.out.println("表头信息:" + headMap);
}
//直接使用List来保存数据
@Override
public void invoke(ExcelOrder valueData, AnalysisContext context) {
if(ObjectUtil.isNotEmpty(valueData)){
resultData .add(valueData); //封装数据
}
}
// 解析完成会调用该方法
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// log.info("Excel读取完成,文件名:"+fileName+",sheet:"+sheetName+",行数:"+dataList.size());
System.out.println("解析完成了");
}
}).sheet(sheet) // 读取的sheet页 0,1,2
.headRowNumber(headRowNumber) //表头行 --如表头在第一行-正式数据则从第二行开始读取
.doRead();2. 和监听器方式。 本文已经封装了包含合并单元格数据处理方式粘贴即用。
2.1 创建监听器--继承 AnalysisEventListener/或ReadListener重写对应方法
package com.sgcc.common.utils.easyexcel;
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.alibaba.excel.metadata.CellExtra;
import com.alibaba.excel.read.metadata.holder.ReadRowHolder;
import com.alibaba.fastjson.JSON;
import org.apache.commons.beanutils.BeanUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
/**
* Excel模板的读取监听通用工具 类
*
* @author D_ZH
*/
public class ReadtExcelListener<T> extends AnalysisEventListener<T> {
private static final Logger LOGGER = LoggerFactory.getLogger(ImportExcelListener.class);
/**
* 解析的数据
*/
List<T> list = new ArrayList<>();
/**
* 正文起始行
*/
private Integer headRowNumber;
/**
* 合并单元格
*/
private List<CellExtra> extraMergeInfoList = new ArrayList<>();
public ImportExcelListener(Integer headRowNumber) {
this.headRowNumber = headRowNumber;
}
/**
* 这个每一条数据解析都会来调用
*
* @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context context
*/
@Override
public void invoke(T data, AnalysisContext context) {
// 如果一行Excel数据均为空值,则不装载该行数据
if(isLineNullValue(data)){
return;
}
LOGGER.info("解析到一条数据: {}", data);
// 获取Excle行号(从0开始)
ReadRowHolder readRowHolder = context.readRowHolder();
Integer rowIndex = readRowHolder.getRowIndex();
try {
BeanUtils.setProperty(data, "lineNo", rowIndex+1);
} catch (IllegalAccessException e) {
LOGGER.error("ImportExcelListener.invoke 设置行号异常: ", e);
} catch (InvocationTargetException e) {
LOGGER.error("ImportExcelListener.invoke 设置行号异常: ", e);
}
list.add(data);
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
LOGGER.info("所有数据解析完成!");
}
/**
* 返回解析出来的List
*/
public List<T> getData() {
return list;
}
/**
* 读取额外信息:合并单元格
*/
@Override
public void extra(CellExtra extra, AnalysisContext context) {
LOGGER.info("读取到了一条额外信息:{}", JSON.toJSONString(extra));
switch (extra.getType()) {
case MERGE: {
LOGGER.info(
"额外信息是合并单元格,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{}",
extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(),
extra.getLastColumnIndex());
if (extra.getRowIndex() >= headRowNumber) {
extraMergeInfoList.add(extra);
}
break;
}
default:
}
}
/**
* 返回解析出来的合并单元格List
*/
public List<CellExtra> getExtraMergeInfoList() {
return extraMergeInfoList;
}
/**
* 判断整行单元格数据是否均为空 true是 false否
*/
private boolean isLineNullValue(T data) {
if (data instanceof String) {
return Objects.isNull(data);
}
try {
List<Field> fields = Arrays.stream(data.getClass().getDeclaredFields())
.filter(f -> f.isAnnotationPresent(ExcelProperty.class))
.collect(Collectors.toList());
List<Boolean> lineNullList = new ArrayList<>(fields.size());
for (Field field : fields) {
field.setAccessible(true);
Object value = field.get(data);
if (Objects.isNull(value)) {
lineNullList.add(Boolean.TRUE);
} else {
lineNullList.add(Boolean.FALSE);
}
}
return lineNullList.stream().allMatch(Boolean.TRUE::equals);
} catch (Exception e) {
LOGGER.error("读取数据行[{}]解析失败: {}", data, e.getMessage());
}
return true;
}
}
2.2 数据读取处理
package com.sgcc.common.utils.easyexcel;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.enums.CellExtraTypeEnum;
import com.alibaba.excel.metadata.CellExtra;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.util.CollectionUtils;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.util.List;
/**
* DZ_H
* @param <T>
*/
public class ReadExcelHelper<T> {
private static final Logger LOGGER = LoggerFactory.getLogger(ImportExcelHelper.class);
/**
* 返回解析后的List
*
* @param: file 文件流
* @param: clazz Excel对应属性名
* @param: sheetNo 要解析的sheet
* @param: headRowNumber 正文起始行
* @return java.util.List<T> 解析后的List
*/
public List<T> getList(InputStream file, Class<T> clazz, Integer sheetNo, Integer headRowNumber) {
ImportExcelListener<T> listener = new ImportExcelListener<>(headRowNumber);
try {
//读取当前数据
EasyExcel.read(file, clazz, listener).extraRead(CellExtraTypeEnum.MERGE).sheet(sheetNo).headRowNumber(headRowNumber).doRead();
} catch (Exception e) {
LOGGER.error(e.getMessage());
}
// 监听合并单元格
List<CellExtra> extraMergeInfoList = listener.getExtraMergeInfoList();
if (CollectionUtils.isEmpty(extraMergeInfoList)) {
return listener.getData();
}
// 处理合并单元格
List<T> data = explainMergeData(listener.getData(), extraMergeInfoList, headRowNumber);
return data;
}
/**
* 处理合并单元格
*
* @param data 解析数据
* @param extraMergeInfoList 合并单元格信息
* @param headRowNumber 起始行
* @return 填充好的解析数据
*/
private List<T> explainMergeData(List<T> data, List<CellExtra> extraMergeInfoList, Integer headRowNumber) {
//循环所有合并单元格信息
extraMergeInfoList.forEach(cellExtra -> {
int firstRowIndex = cellExtra.getFirstRowIndex() - headRowNumber;
int lastRowIndex = cellExtra.getLastRowIndex() - headRowNumber;
int firstColumnIndex = cellExtra.getFirstColumnIndex();
int lastColumnIndex = cellExtra.getLastColumnIndex();
//获取初始值
Object initValue = getInitValueFromList(firstRowIndex, firstColumnIndex, data);
//设置值
for (int i = firstRowIndex; i <= lastRowIndex; i++) {
for (int j = firstColumnIndex; j <= lastColumnIndex; j++) {
setInitValueToList(initValue, i, j, data);
}
}
});
return data;
}
/**
* 设置合并单元格的值
*
* @param filedValue 值
* @param rowIndex 行
* @param columnIndex 列
* @param data 解析数据
*/
public void setInitValueToList(Object filedValue, Integer rowIndex, Integer columnIndex, List<T> data) {
T object = data.get(rowIndex);
for (Field field : object.getClass().getDeclaredFields()) {
//提升反射性能,关闭安全检查
field.setAccessible(true);
ExcelProperty annotation = field.getAnnotation(ExcelProperty.class);
if (annotation != null) {
if (annotation.index() == columnIndex) {
try {
field.set(object, filedValue);
break;
} catch (IllegalAccessException e) {
LOGGER.error("设置合并单元格的值异常:"+e.getMessage());
}
}
}
}
}
/**
* 获取合并单元格的初始值
* rowIndex对应list的索引
* columnIndex对应实体内的字段
*
* @param firstRowIndex 起始行
* @param firstColumnIndex 起始列
* @param data 列数据
* @return 初始值
*/
private Object getInitValueFromList(Integer firstRowIndex, Integer firstColumnIndex, List<T> data) {
Object filedValue = null;
T object = data.get(firstRowIndex);
for (Field field : object.getClass().getDeclaredFields()) {
//提升反射性能,关闭安全检查
field.setAccessible(true);
ExcelProperty annotation = field.getAnnotation(ExcelProperty.class);
if (annotation != null) {
if (annotation.index() == firstColumnIndex) {
try {
filedValue = field.get(object);
break;
} catch (IllegalAccessException e) {
LOGGER.error("设置合并单元格的初始值异常:"+e.getMessage());
}
}
}
}
return filedValue;
}
}
3. 批注、超链接、合并单元格信息读取
额外信息(批注、超链接、合并单元格信息读取)EasyExcel对这COMMENT,HYPERLINK,MERGE三种额外数据读取。
监听器里重写extra方法拿到额外信息,即可拿到改【最后行,最后列,起始行,起始列】的行列下标以及单元格内容。最后处理数据用。
@Override
public void extra(CellExtra extra, AnalysisContext context) {
log.info("读取到了一条额外信息:{}", JSON.toJSONString(extra));
switch (extra.getType()) {
case COMMENT:
log.info("额外信息是批注,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(), extra.getColumnIndex(),
extra.getText());
break;
case HYPERLINK:
log.info(
"额外信息是超链接,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{},"
+ "内容是:{}",
extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(),
extra.getLastColumnIndex(), extra.getText());
break;
case MERGE:
log.info(
"额外信息是合并单元格,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{}",
extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(),
extra.getLastColumnIndex());
break;
default:
}Excel写操作:简单示例
// 写入路径
String fileName = TestFileUtil.getPath() + "excludeOrIncludeWrite" + System.currentTimeMillis() + ".xlsx";
//获取数据
List<Student> students = StudentService.getList();
EasyExcel.write(fileName, Student.class)
.sheet("模板") //指定写入到sheet
.doWrite(students); //数据源本地测试:文件准备
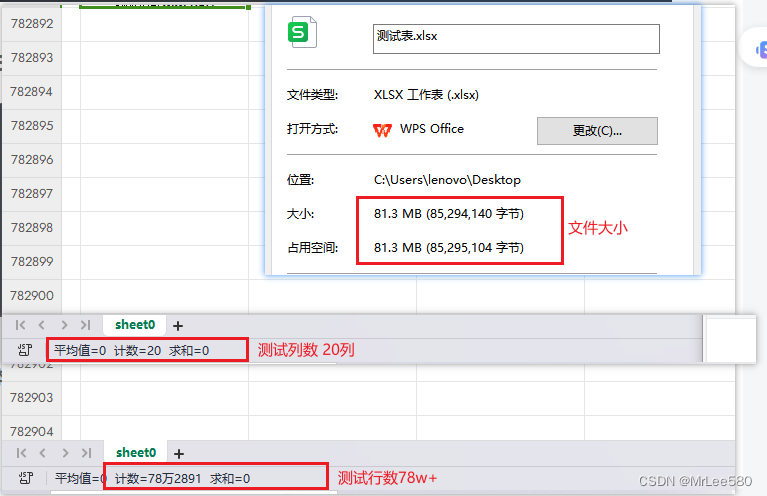
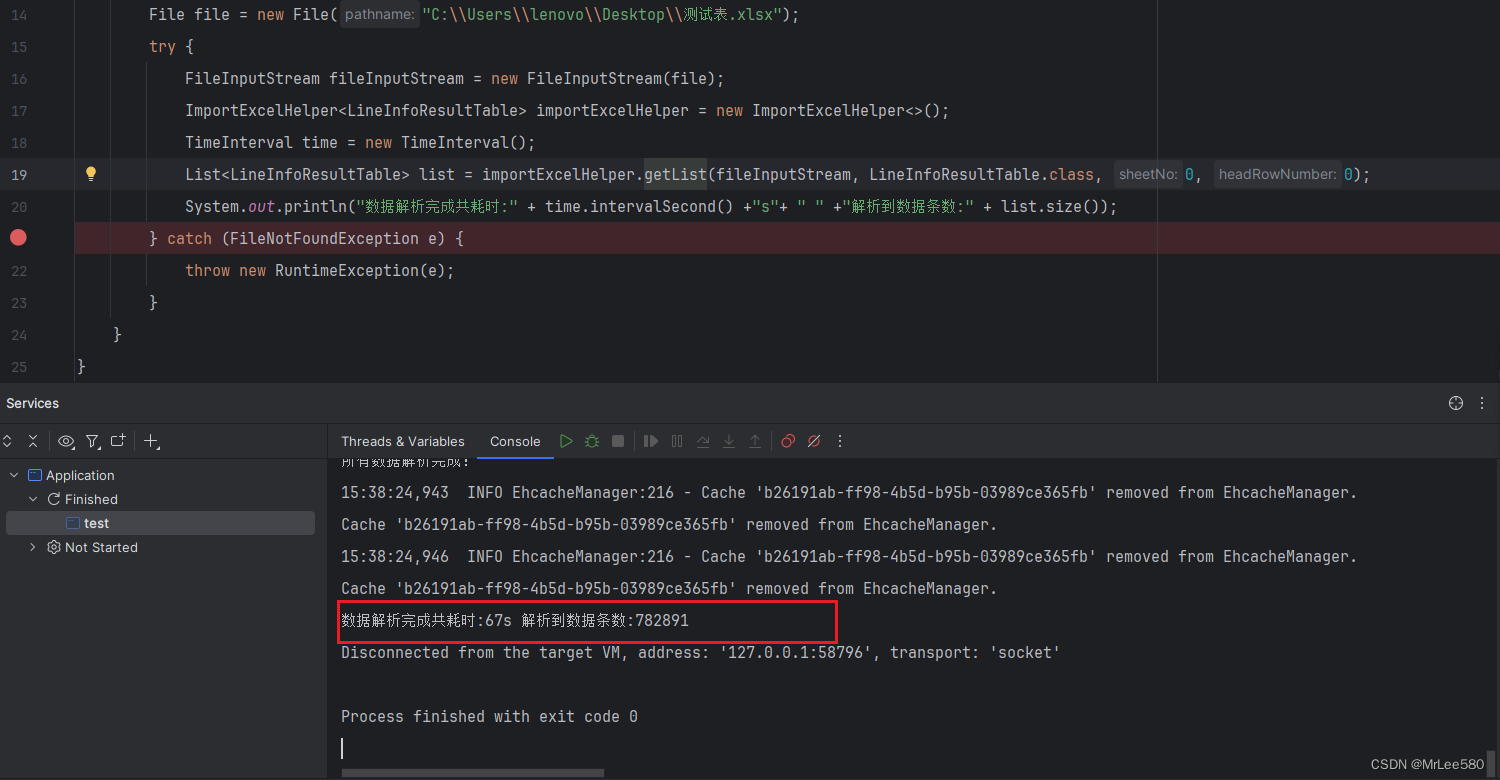
执行结果:782891条数据解析耗时67秒

















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









