







前言
通过上面的两篇文章,分析了require.js加载过程中所做的工作,实际上就是创建一个contextName为’_'对应的context上下文,也只到require函数实际上就是调用localRequire函数,该函数的大概代码如下:
// deps表示依赖列表, callback表示回调函数,errback表示处理错误的回调函数
function localRequire(deps, callback, errback) {
// 相关处理代码
}
在函数会对依赖模块对应对象的创建、模块的加载以及其他相关工作,是整个require最核心的逻辑处理。
localRequire函数处理流程分析
通过阅读源码,分析localRequire函数的处理流程如下:
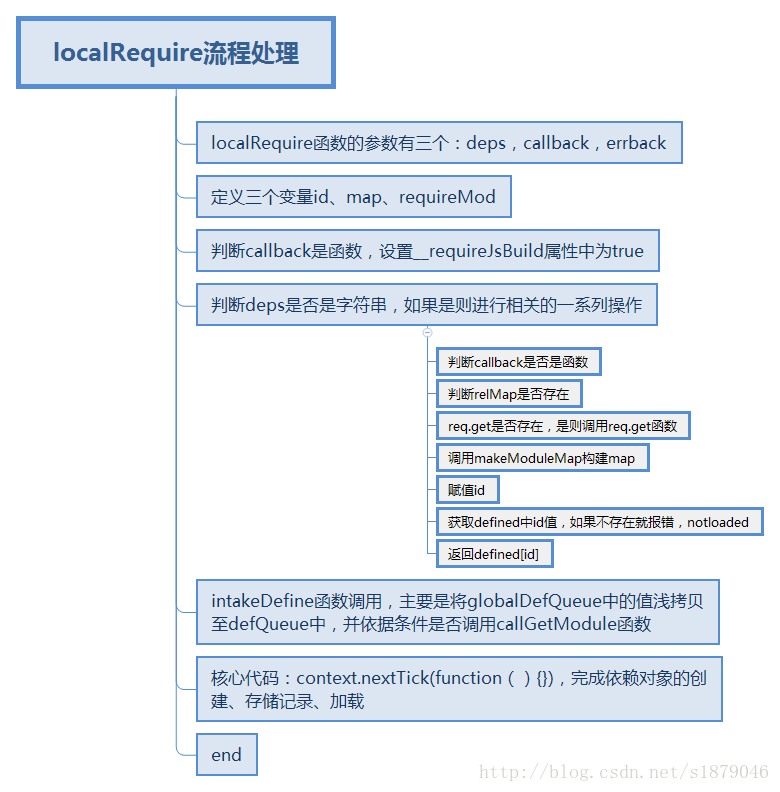
从上面可知最核心的处理是如下代码:
context.nextTick(function () {
intakeDefines();
requireMod = getModule(makeModuleMap(null, relMap));
requireMod.skipMap = options.skipMap;
requireMod.init(deps, callback, errback, {enabled: true});
checkLoaded();
});
- intakeDefines函数的主要功能是将globalDefQueue的内容copy到defQueue中并且根据条件调用callGetMoudle
- getMoudle:不言而喻,获取模块
- makeModuleMap:绘制Module依赖map
- requireMod.init:module对象的init方法
- checkLoaded:检查是否加载成功
本次创建了a.js和b.js两个js文件作为模块,在c.js中require中作为依赖,来分析整个流程相关的事情。
require(['./a.js', './b.js'], function(a, b) {
});
当加载c.js就会调用require函数,下面就具体分析下上面几个函数所做的事情。
在require.js加载过程中两次调用了req函数,所以两次定义了定时器,下面是req({}) context.nextTick中函数执行的过程,如下:
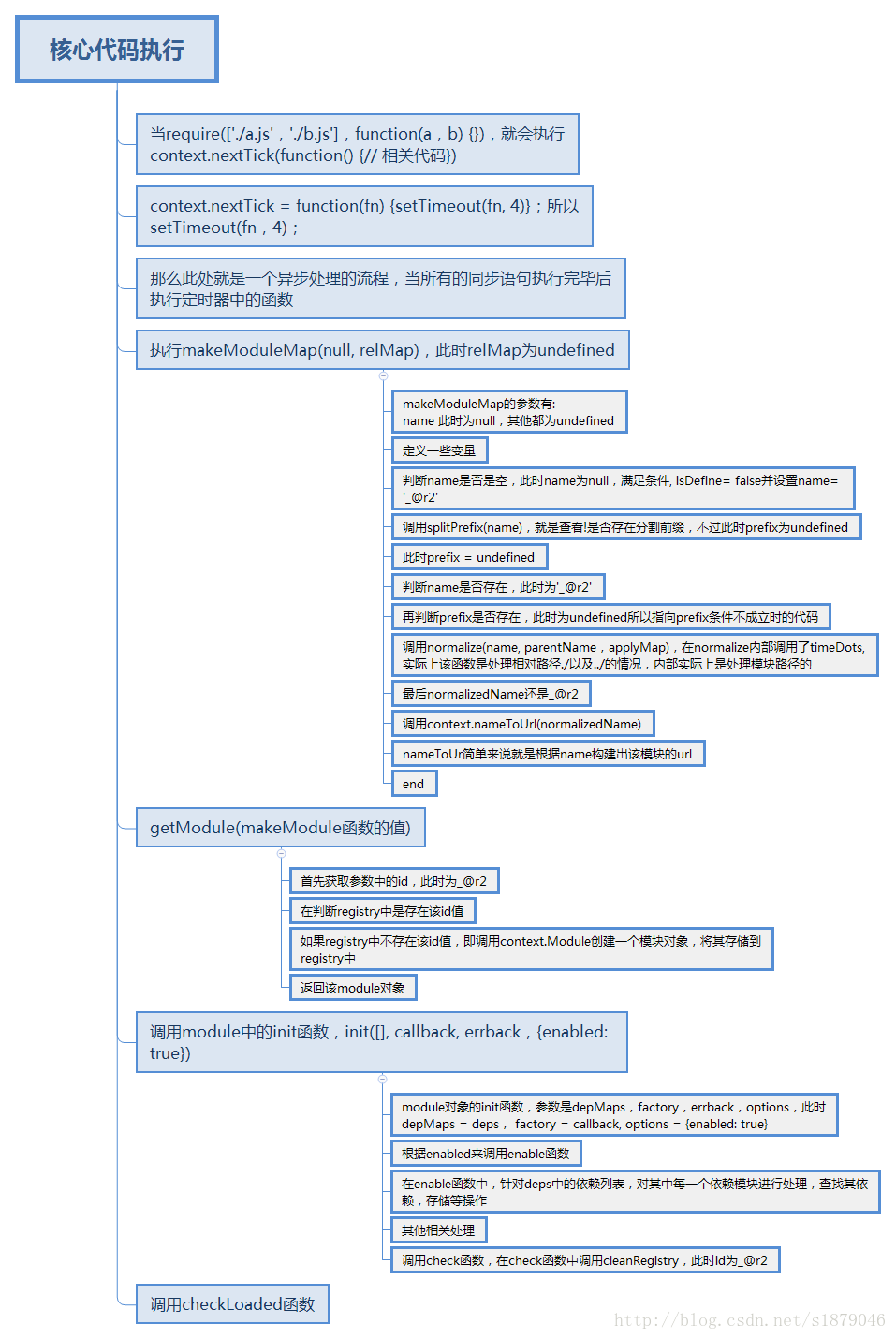
可以看出实际上该函数直接调用了4个函数来处理相关逻辑:
- makeModuleMap
- getModule
- module对象的init函数
- checkLoaded函数
从上面可知:
- req({})创建了模块id为_@r2,url为./_@r2.js
- 分析可知req(cfg)创建了模块id为_@r3,url为./_@r3.js
- require([‘a.js’,‘b.js’])创建了id为_@r4的模块,url为./_@r4.js其depMaps是a和b两个模块
实际上require([‘a.js’,‘b.js’])的过程与req({})中上图过程差不多,出现差别的地方是:
- 调用module对象的init时,depMaps = [‘a’,‘b’],对depMaps进行遍历,对其中每一个依赖执行makeModuleMap操作,创建id为a和b的模块并将其存入registry中
然后就是列表a和b依次执行下面这四个函数:
- makeModuleMap
- getModule
- module对象的init函数
- checkLoaded函数
在流程中调用check函数的时候调用了有了较大的差别:
- 首先在check函数中调用了fetch函数
- 在fetch函数中调用了load函数
- 在load函数中调用了req.load函数,而req.load函数是用于创建script节点,并设置srcipt中一些属性的,设置了async = true,这是异步加载的本质
同理模块b的过程也是如此,自此,默认明白了require是任何处理依赖列表,并且如何异步加载js文件的。
总结
通过对于源码的阅读分析,知道核心代码直接调用了下面四个函数:
- makeModuleMap:构建ModuleMap的
- getModule:获取module对象
- module对象的init函数:设置deps,判断模块是否可使用以及依赖列表的中每个依赖的处理
- checkLoaded函数:处理循环依赖等问题
require函数会通过上面四个函数创建模块,而require中依赖也是通过上面四个函数创建被加载的,这部分的主要实现是check函数中对于depMaps的遍历处理。
已经知道了require.js是如何处理依赖列表和加载依赖的,但是对于循环依赖是如何处理的,之后会看看require.js是如何处理循环依赖的。














 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









