preOpen, postOpen: Called before and after the region is reported as online to the master.
preFlush, postFlush: Called before and after the memstore is flushed into a new store file.
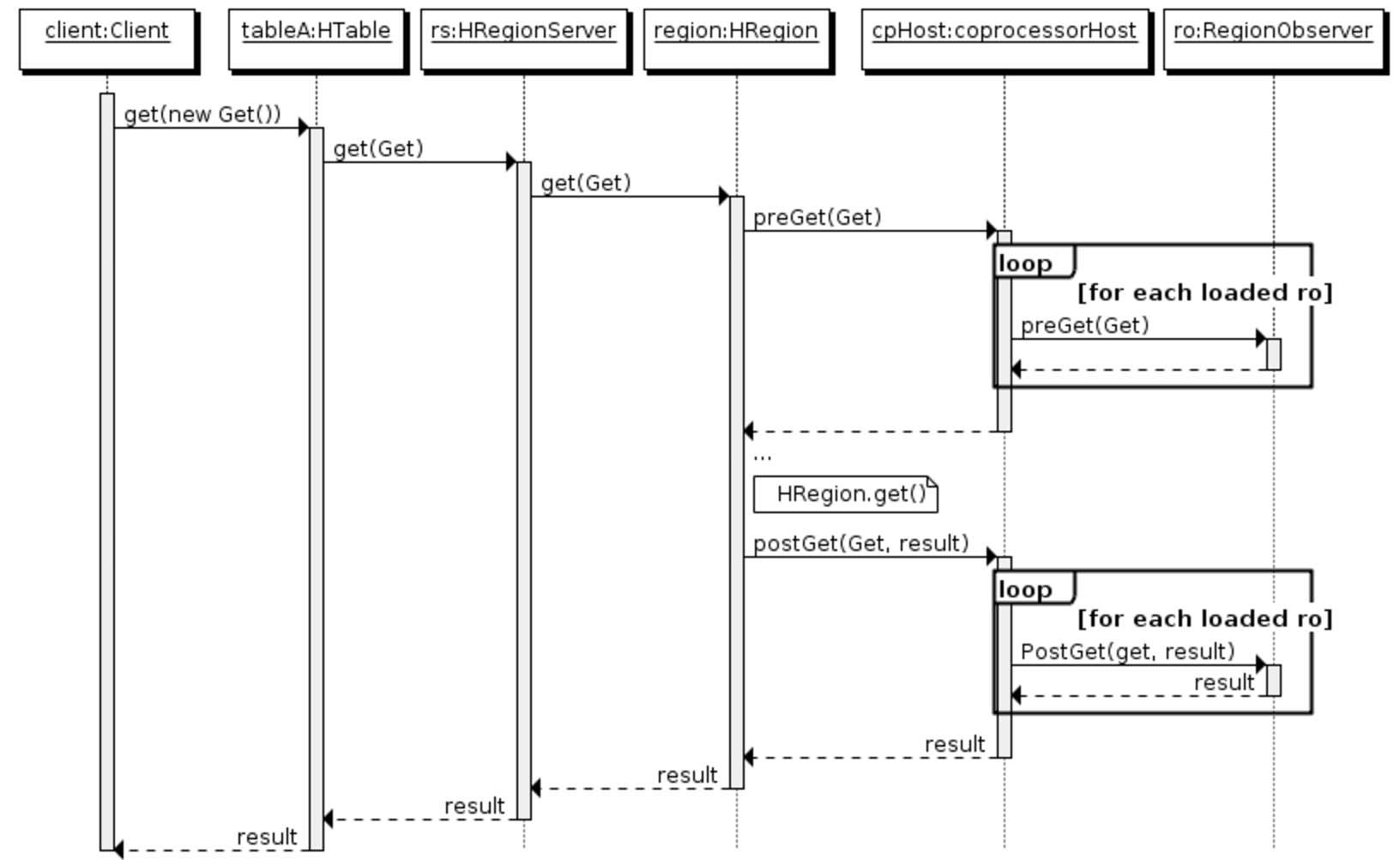
preGet, postGet: Called before and after a client makes a Get request.
preExists, postExists: Called before and after the client tests for existence using a Get.
prePut and postPut: Called before and after the client stores a value.
preDelete and postDelete: Called before and after the client deletes a value.
复制代码 public class 协处理器类名称 extends BaseRegionObserver { private static final Log LOG = LogFactory.getLog(协处理器类名称.class); private RegionCoprocessorEnvironment env = null;// 协处理器是运行于region中的,每一个region都会加载协处理器 // 这个方法会在regionserver打开region时候执行(还没有真正打开) @Override public void start(CoprocessorEnvironment e) throws IOException { env = (RegionCoprocessorEnvironment) e; }
// 这个方法会在regionserver关闭region时候执行(还没有真正关闭)
@Override
public void stop(CoprocessorEnvironment e) throws IOException {
// nothing to do here
}
/**
* 出发点,比如可以重写prePut postPut等方法,这样就可以在数据插入前和插入后做逻辑控制了。
*/
@Override
复制代码 业务代码实现 :
根据上述需求和代码框架,具体逻辑实现如下。
在插入需要做检查所以重写了prePut方法 在删除前需要做检查所以重写了preDelete方法 复制代码 public class MyRegionObserver extends BaseRegionObserver { private static final Log LOG = LogFactory.getLog(MyRegionObserver.class);
private RegionCoprocessorEnvironment env = null;
// 设定只有F族下的列才能被操作,且A列只写,B列只读。的语言
private static final String FAMAILLY_NAME = "F";
private static final String ONLY_PUT_COL = "A";
private static final String ONLY_READ_COL = "B";
// 协处理器是运行于region中的,每一个region都会加载协处理器
// 这个方法会在regionserver打开region时候执行(还没有真正打开)
@Override
public void start(CoprocessorEnvironment e) throws IOException {
env = (RegionCoprocessorEnvironment) e;
}
// 这个方法会在regionserver关闭region时候执行(还没有真正关闭)
@Override
public void stop(CoprocessorEnvironment e) throws IOException {
// nothing to do here
}
/**
* 需求 1.不允许插入B列 2.只能插入A列 3.插入的数据必须为整数 4.插入A列的时候自动插入B列
*/
@Override
public void prePut(final ObserverContext<RegionCoprocessorEnvironment> e,
final Put put, final WALEdit edit, final Durability durability)
throws IOException {
// 首先查看单个put中是否有对只读列有写操作
List<Cell> cells = put.get(Bytes.toBytes(FAMAILLY_NAME),
Bytes.toBytes(ONLY_READ_COL));
if (cells != null && cells.size() != 0) {
LOG.warn("User is not allowed to write read_only col.");
throw new IOException("User is not allowed to write read_only col.");
}
// 检查A列
cells = put.get(Bytes.toBytes(FAMAILLY_NAME),
Bytes.toBytes(ONLY_PUT_COL));
if (cells == null || cells.size() == 0) {
// 当不存在对于A列的操作的时候则不做任何的处理,直接放行即可
LOG.info("No A col operation, just do it.");
return;
}
// 当A列存在的情况下在进行值得检查,查看是否插入了整数
byte[] aValue = null;
for (Cell cell : cells) {
try {
aValue = CellUtil.cloneValue(cell);
LOG.warn("aValue = " + Bytes.toString(aValue));
Integer.valueOf(Bytes.toString(aValue));
} catch (Exception e1) {
LOG.warn("Can not put un number value to A col.");
throw new IOException("Can not put un number value to A col.");
}
}
// 当一切都ok的时候再去构建B列的值,因为按照需求,插入A列的时候需要同时插入B列
LOG.info("B col also been put value!");
put.addColumn(Bytes.toBytes(FAMAILLY_NAME),
Bytes.toBytes(ONLY_READ_COL), aValue);
}
/**
* 需求 1.不能删除B列 2.只能删除A列 3.删除A列的时候需要一并删除B列
*/
@Override
public void preDelete(
final ObserverContext<RegionCoprocessorEnvironment> e,
final Delete delete, final WALEdit edit, final Durability durability)
throws IOException {
// 首先查看是否对于B列进行了指定删除
List<Cell> cells = delete.getFamilyCellMap().get(
Bytes.toBytes(FAMAILLY_NAME));
if (cells == null || cells.size() == 0) {
// 如果客户端没有针对于FAMAILLY_NAME列族的操作则不用关心,让其继续操作即可。
LOG.info("NO F famally operation ,just do it.");
return;
}
// 开始检查F列族内的操作情况
byte[] qualifierName = null;
boolean aDeleteFlg = false;
for (Cell cell : cells) {
qualifierName = CellUtil.cloneQualifier(cell);
// 检查是否对B列进行了删除,这个是不允许的
if (Arrays.equals(qualifierName, Bytes.toBytes(ONLY_READ_COL))) {
LOG.info("Can not delete read only B col.");
throw new IOException("Can not delete read only B col.");
}
// 检查是否存在对于A队列的删除
if (Arrays.equals(qualifierName, Bytes.toBytes(ONLY_PUT_COL))) {
LOG.info("there is A col in delete operation!");
aDeleteFlg = true;
}
}
// 如果对于A列有删除,则需要对B列也要删除
if (aDeleteFlg)
{
LOG.info("B col also been deleted!");
delete.addColumn(Bytes.toBytes(FAMAILLY_NAME), Bytes.toBytes(ONLY_READ_COL));
}
}
1.cf:countCol 进行累加操作,每次插入的时候都要与之前的值进行相加 */ @Override public void prePut(ObserverContext e, Put put, WALEdit edit, Durability durability) throws IOException { if (put.has(columnFamily,countCol)){ //获取old countCol value Result result = e.getEnvironment().getRegion().get(new Get(put.getRow())); int oldNum=0; for (Cell cell:result.rawCells()){ if (CellUtil.matchingColumn(cell,columnFamily,countCol)){ oldNum=Integer.parseInt(Bytes.toString(CellUtil.cloneValue(cell))); } }
//获取new countCol value
List<Cell> cells=put.get(columnFamily,countCol);
int newNum=0;
for (Cell cell:cells){
if (CellUtil.matchingColumn(cell,columnFamily,countCol)){
newNum=Integer.parseInt(Bytes.toString(CellUtil.cloneValue(cell)));
}
}
//sum AND update Put实例
put.addColumn(columnFamily,countCol,Bytes.toBytes(String.valueOf(oldNum+newNum)));
} }
/**
不能直接删除unDeleteCol,删除countCol的时候将unDeleteCol列一同删除 */ @Override public void preDelete(ObserverContext e, Delete delete, WALEdit edit, Durability durability) throws IOException { List cells=delete.getFamilyCellMap().get(columnFamily); if (cells==null|| cells.size()==0){ return; } boolean delFlag=false; for (Cell cell:cells){ byte[] qualifier=CellUtil.cloneQualifier(cell); if (Arrays.equals(qualifier,unDeleteCol)){ throw new IOException(“can not delete unDel column”); } if (Arrays.equals(qualifier,countCol)){ delFlag=true; } } if (delFlag){ delete.addColumn(columnFamily,unDeleteCol); } } }

























 3807
3807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









