







1. 绪论
数据库的基本概念:
数据(data): 数据库中存储的基本对象, 可以是文字, 声音, 图片, 视频等。
数据库(DB): 概括来说就是永久存储, 有组织, 可共享的大量数据的集合。
数据库管理系统(DBMS): 和操作系统一样是计算机基础软件, 主要有数据定义语言(DDL, 对数据对象的组成与结构进行定义)和数据操作语言(DML, 增删改查)等
数据库系统(DBS): 由数据库, 数据库管理系统(及其应用开发工具), 应用程序和数据库管理员(DBA)组成的存储、管理、处理和维护数据的系统。
引入数据库后计算机系统的层次结构:

1.1 数据模型
两类数据模型: 1) 概念模型 2) 逻辑模型+物理模型
数据模型=数据结构+ 数据操作+数据的完整性约束条件
客观对象的抽象过程:

概念模型:
1) 实体: 客观存在可互相区别的事物, 如学生, 职工, 部门, 选课等。
2) 属性: 实体所具有的某一特性, 如学生的学号, 姓名, 出生年月等。
3) 码: 唯一标识实体的属性集, 如学生的学号, 整个属性组是码, 则称为全码
4) 实体型: 实体名及其属性名集合, 如学生(学号, 姓名, 出生年月)就是一个实体型
5) 实体集: 同一类型实体的集合
6) 联系: 实体之间的联系, 如一对一, 一对多, 多对多。
逻辑模型:
1) 层次模型
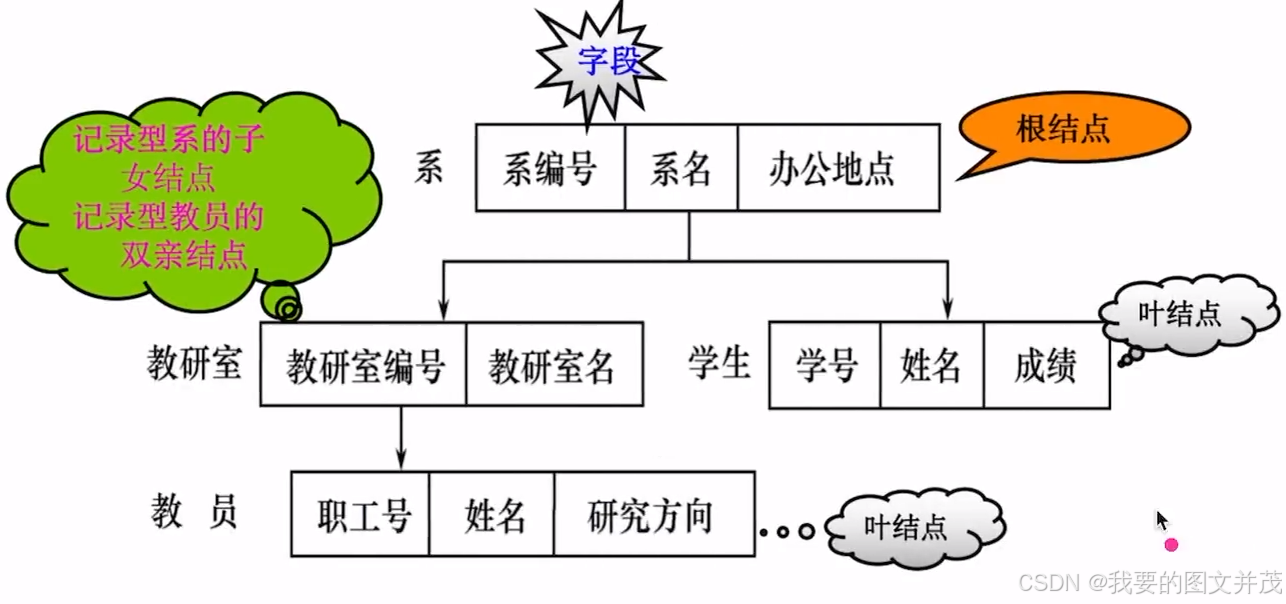
优点: 数据结构清晰简单, 查询效率优
缺点: 多对多联系表示不自然, 对插入和删除限制多
2) 网状模型

优点: 具有良好性能
缺点: 结构比价复杂
3) 关系模型

4) 面向对象数据模型
5) 对象关系数据模型
6) 半结构化数据模型
相关概念:
关系: 一个关系对应一张表
元组: 表中的一行为一个元组
属性: 表中的一列即为一个属性
码: 可以唯一确定一个元组
域: 属性的取值范围, 如 {男, 女}
分量: 元组中的一个属性值
关系模式: 关系名(属性1, 属性2, ... , 属性n)
备注: 关系必须是规范化的, 每一个分量是一个不可分的数据项, 即不允许表中表。
数据库系统结构
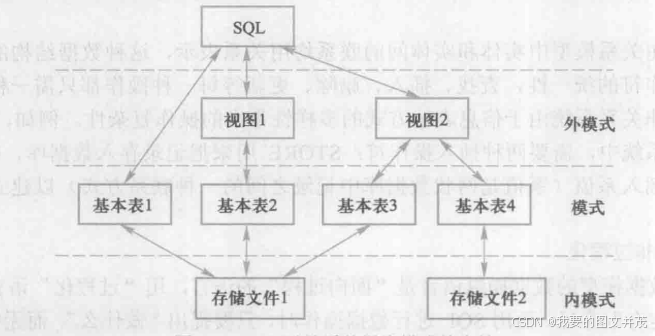
模式: 逻辑模式, 数据库中全体数据的逻辑结构和特征的描述, 是所有用户的公共数据视图。
外模式: 称子模式或用户模式, 是数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述。
内模式: 存储模式, 数据物理结构和存储方式的描述。
1.2 数据库系统模式
数据库系统的三级模式结构:
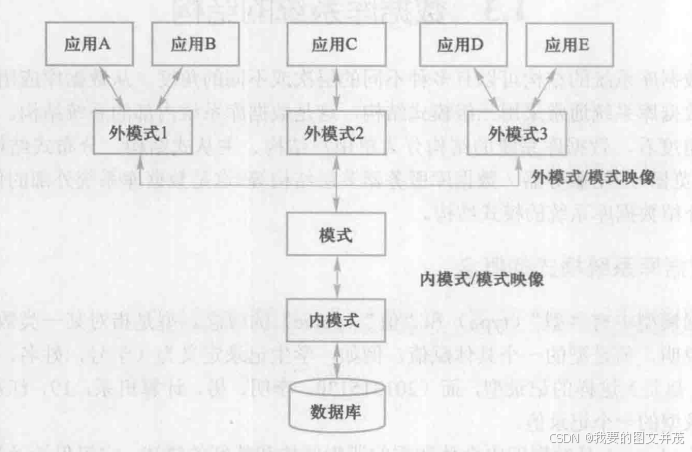
数据库的二级映像:
1) 外模式/模式映像: 模式改变时, 可使外模式不变, 保证数据与程序的逻辑独立性
2) 模式/内模式映像: 数据库的结构改变时, 可使模式保持不变, 保证数据与程序的物理独立性
2 关系数据库
笛卡尔积: 域上的一种运算。
例图:

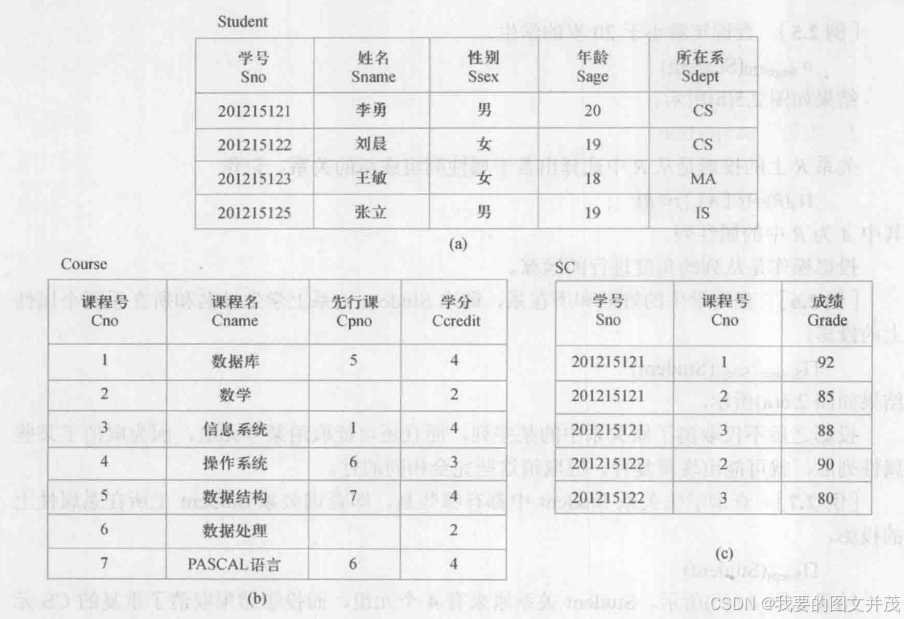
备注: 其中(刘逸, 计算机专业, 刘晨) 是元组(记录), 刘逸是分量。R(A1,A2 ...An), 即关系名(属性1, 属性2 ... 属性n) 称为关系模型
2.1 关系操作
关系的完整性:
实体完整性: 关系R中主属性不能取空值, 如学生(学号, 姓名, 年龄), 学号为主码不能是空值。
参照完整性: 外码取空值或取对应关系表中某个元组的值
用户定义的完整性: 如成绩只能取 0~100
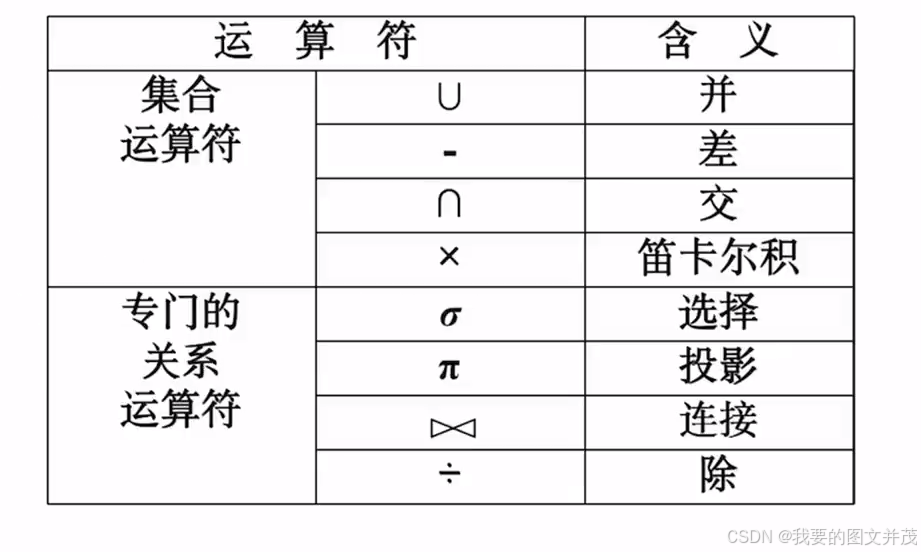
关系代数运算符表:
示例表:
2.1.1 选择
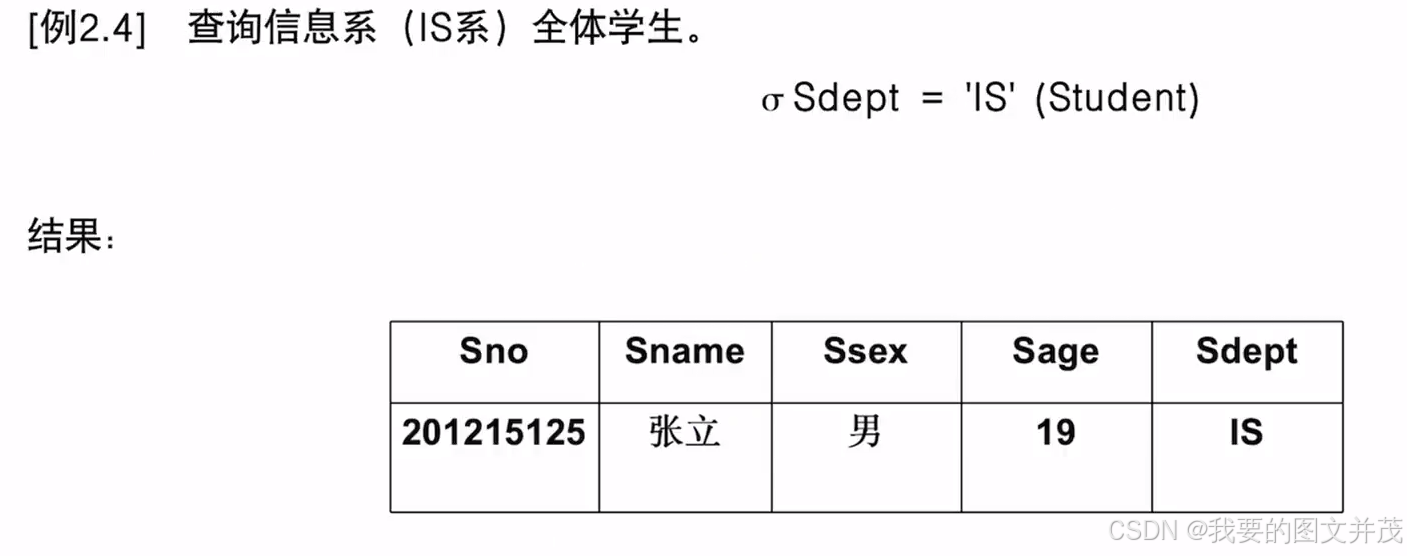
2.1.2 投影
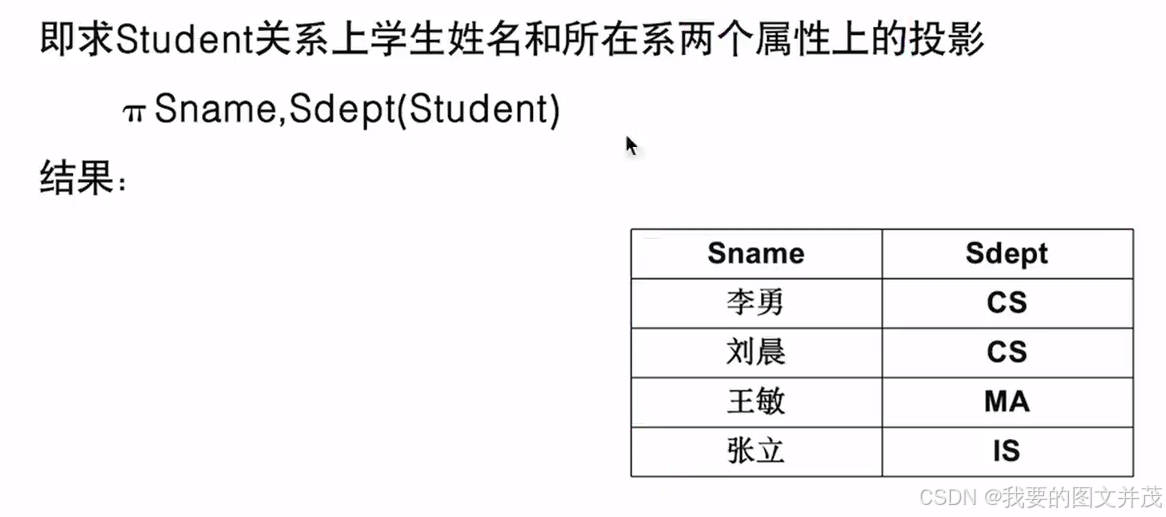
备注: 去重
2.1.3 连接

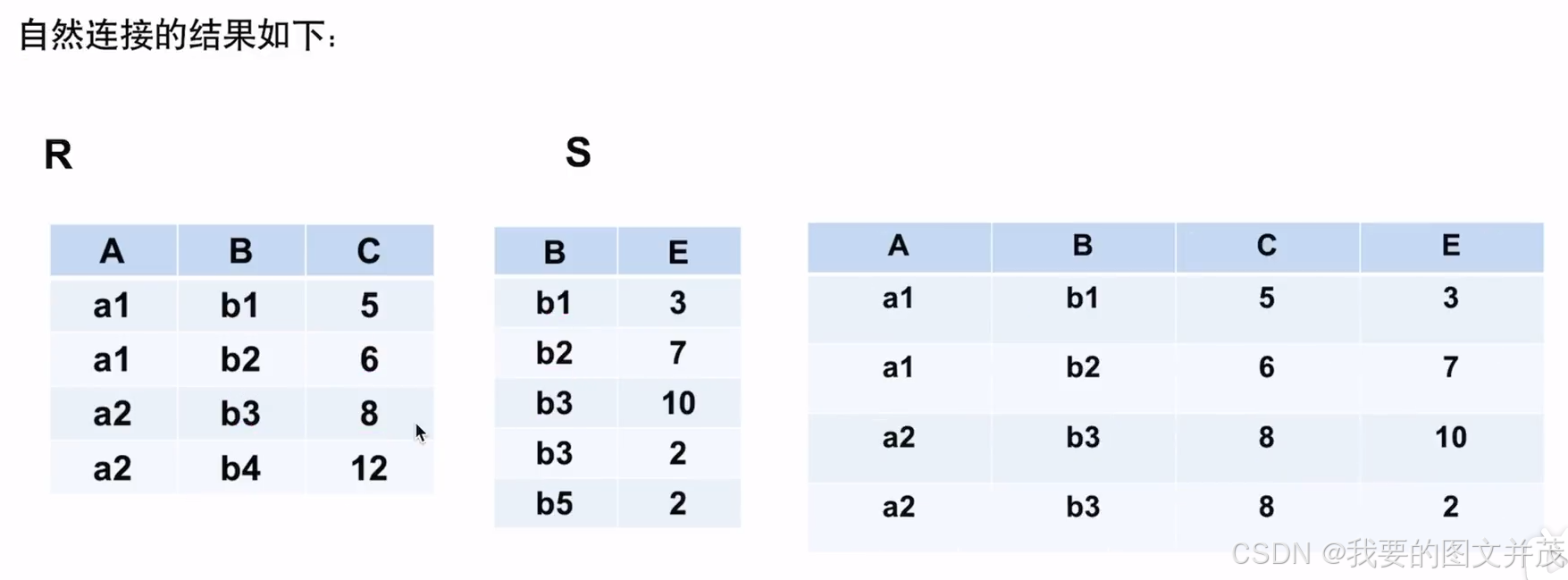
备注: 自然连接是两个关系的相同属性上的等值连接。结果中把重复的属性去掉, 而等值连接不必。
2.1.4 除
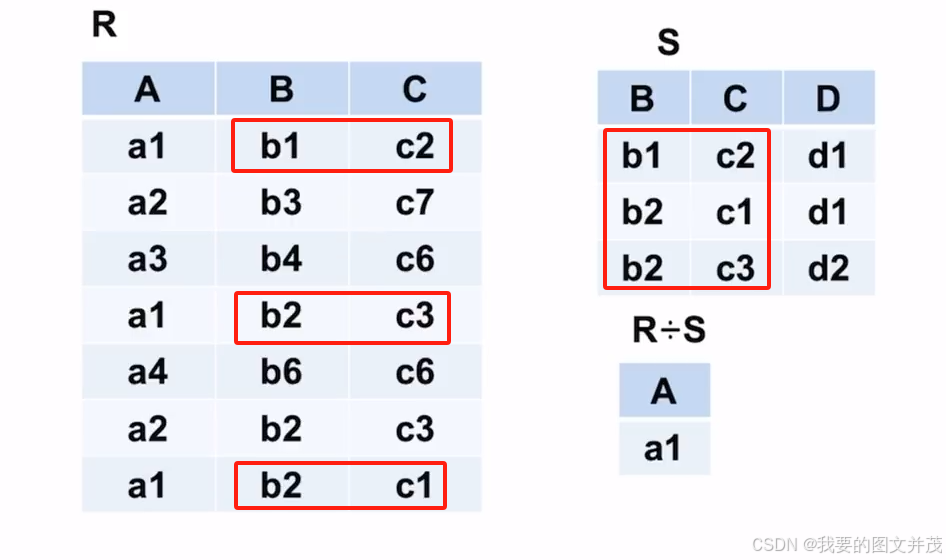
2.2 数据库标准语言SQL
SQL的基本概念:
视图: 数据库中只存放视图定义而不存放视图对应数据, 因此是一个虚表
2.2.1 SQL理论
数值类型:
bit[(m)] m制定位数,默认为1 tinyint 1字节
smallint 2字节 int 4字节
bigint 8字节 float(M,D) 4字节
double(M,D) 8字节 decimal(M,D) 相当于java BigDecimal
日期类型: datetime 8字节
运算符: and, or, not
2.2.2 SQL定义
约束:
NOT NULL: 不能为空 (用户定义的完整性)
unque: 数据唯一 (用户定义的完整性)
check (条件) : 检查列值是否满足条件表达式 (用户定义的完整性)
default: 默认值
primary key auto_increment:限制列为自增主键 (实体完整性)
primary key (列名):定义关系主码 (实体完整性)
foreign key (子表的列名) references父表名(列名) (参照完整性)
创建数据库:
create database 数据库名
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









