






前言
logo:

了解下链路式监控的的新技术,上级指定了一个开源的软件—zipkin。特此翻译一下官方文档,以便学习。
Home(主页)
Zipkin

Zipkin是一个分布式追踪系统。 它有助于收集解决微服务架构中延迟问题所需的时序数据。 它管理这些数据的收集和查找。 Zipkin的设计基于Google Dapper论文。这里提供一篇译文,有兴趣的可以了解一下。
应用程序用于向Zipkin报告时间数据。 Zipkin用户界面还提供了一个依赖关系图,显示每个应用程序有多少跟踪请求。 如果您正在解决延迟问题或错误问题,则可以根据应用程序,跟踪长度,注释或时间戳过滤或排序所有跟踪。 一旦选择了一个跟踪,您可以看到每个跨度所花费的总跟踪时间的百分比,从而可以确定问题应用程序。
Quickstart(快速入门)
在本节中,我们将通过构建和启动一个Zipkin实例来在本地检出Zipkin。 有三种选择:使用Java,Docker或从源代码运行。
如果你熟悉Docker,这是首选的方法。 如果您不熟悉Docker,请尝试通过Java或从源代码运行。
不管你用那种方式启动Zipkin,打开浏览器输入 http:// your_host:9411 寻找痕迹!Docker
Docker Zipkin项目能够构建docker的 images镜像,同时提供脚本和docker-compose.yml以启动预先构建的images。 最快的开始是直接运行最新的images:
docker run -d -p 9411:9411 openzipkin/zipkinJava
如果您安装了Java 8或更高版本,最快捷的入门方法是将最新版本(latest release)作为自包含的可执行jar获取:
wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
java -jar zipkin.jarRunning from Source(从源码运行)
如果您正在开发新功能,Zipkin可以从源代码运行。 为了实现这一点,你需要获得Zipkin的源代码并构建它。
# get the latest source
git clone https://github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
java -jar ./zipkin-server/target/zipkin-server-*exec.jarArchitecture(架构)
Architecture Overview(架构概述)
以下翻译官网名词我会用英文标红原著,中文写在括号中,便于编码时理解。
Tracers(跟踪器)位于您的应用程序中,并记录发生操作的时间和元数据。他们经常 instrument libraries(装配在库上),所以对用户来说是透明的。举个例子,一个装配过的 Web 服务器,会在接收请求和发送响应时进行记录。收集的追踪数据叫做 Span(跨度)。
生产环境中的装配器应该是安全并且低负载的。 因此,他们只在in-band(带内)传输 ID,并且告诉接收器仍有一个追踪在处理。以告诉接收器有一个正在进行的踪迹。已完成的跨度在out-of-band(带外)汇报给 Zipkin,类似于应用程序异步汇报指标一样。
举例来说,当追踪一个操作的时候,该操作对外发送了一个 HTTP 请求,那么,为了传输 ID 就会添加一些额外的头部信息。头部信息不是用来发送像是操作名这样的详细信息的。
装配应用中用于向 Zipkin 发送数据的组件叫做 Reporter。Reporter 通过 Transport 发送追踪数据到 Zipkin 的 Collector ,Collector 持久化数据到 Storage 中。之后,API 从 Storage 中查询数据提供给UI 。
下面的图表描述了整个流程:
Instrumented client:被装配的客户端
Non-Instrumented server:没被装配的服务端
Instrumented server:被装配的服务端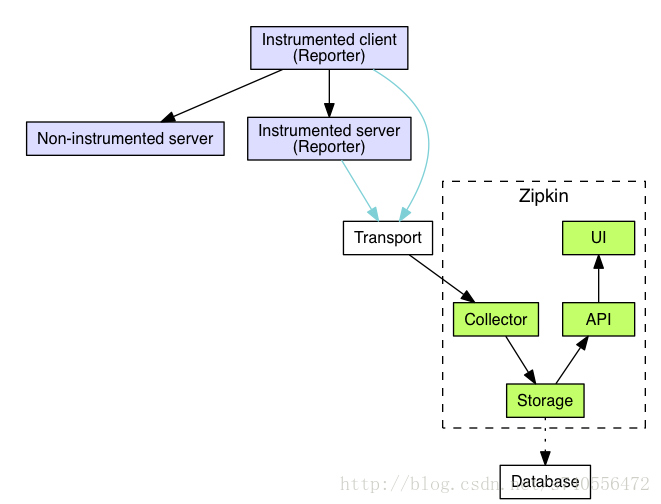
你所在平台是否已经有现成的装配库,可以查看:现有的装配库(点我,此处没有做翻译,了解下各语言自己的装配库的工具即可)。
Example flow (事例流程)
正如上文中所提到的,ID(标识符)是在in-band(带内)发送的,而详细信息是通过out-of-band(带外)发送到Zipkin的。 在这两种情况下,跟踪工具都负责创建有效的痕迹并正确渲染它们。 例如,一个跟踪器可确保它在带内(下游)和带外(向Zipkin异步)发送的数据之间进行平衡。
以下是用户代码调用资源/foo的http跟踪示例序列。 这会导致一个Span(跨度)在用户代码收到http响应后异步发送到Zipkin。
┌─────────────┐ ┌───────────────────────┐ ┌─────────────┐ ┌──────────────────┐
│ User Code │ │ Trace Instrumentation │ │ Http Client │ │ Zipkin Collector │
└─────────────┘ └───────────────────────┘ └─────────────┘ └──────────────────┘
│ │ │ │
┌─────────┐
│ ──┤GET /foo ├─▶ │ ────┐ │ │
└─────────┘ │ record tags
│ │ ◀───┘ │ │
────┐
│ │ │ add trace headers │ │
◀───┘
│ │ ────┐ │ │
│ record timestamp
│ │ ◀───┘ │ │
┌─────────────────┐
│ │ ──┤GET /foo ├─▶ │ │
│X-B3-TraceId: aa │ ────┐
│ │ │X-B3-SpanId: 6b │ │ │ │
└─────────────────┘ │ invoke
│ │ │ │ request │
│
│ │ │ │ │
┌────────┐ ◀───┘
│ │ ◀─────┤200 OK ├─────── │ │
────┐ └────────┘
│ │ │ record duration │ │
┌────────┐ ◀───┘
│ ◀──┤200 OK ├── │ │ │
└────────┘ ┌────────────────────────────────┐
│ │ ──┤ asynchronously report span ├────▶ │
│ │
│{ │
│ "traceId": "aa", │
│ "id": "6b", │
│ "name": "get", │
│ "timestamp": 1483945573944000,│
│ "duration": 386000, │
│ "annotations": [ │
│--snip-- │
└────────────────────────────────┘跟踪工具异步的去报告Span是为了防止与跟踪系统有关的延迟、或故障延迟或者破坏用户代码。
Transport
装配库发送的Span(跨度)必须从正在追踪的服务中传送到Zipkin的Collector。 有三种主要的传输方式:HTTP,Kafka和Scribe。
Components(组件)
由下面的四个组件组成了zipkin:
collector
storage
search
web UIZipkin Collector(zipkin的采集器)
一旦追踪数据抵达 Zipkin Collector 的守护进程,Zipkin Collector 为了查询,会对其进行校验、存储和索引。
Storage(存储)
由于Cassandra具有可扩展性,具有灵活的架构,并且在Twitter中大量使用,所以Zipkin最初构建用于存储Cassandra的数据。 但是,我们使该组件可插入。 除了Cassandra之外,我们还支持ElasticSearch和MySQL。 其他后端可能会作为第三方扩展提供。
Zipkin Query Service (zipkin的查询服务)
一旦数据被存储和索引,我们需要一种方法来提取它。 查询守护进程提供了一个用于查找和检索跟踪的简单JSON API。 这个API的主要用户是Web UI。
Web UI(webUI界面)
我们创建了一个GUI,为查看痕迹提供了一个很好的界面。 Web UI提供了一种基于服务,时间和注释查看跟踪的方法。 注意:UI中没有内置认证!
Data Model(数据模型)
官网提示此页面已经过时,所以可以大概扫一眼zipkin中数据模型长的是什么样子即可。https://zipkin.io/pages/data_model.html
Instrumenting a library(装配库)
Overview(概述)
装配一个库,你需要了解并创建以下元素:
1.Core data structures(核心数据结构) - 收集并发送给Zipkin的信息
2.Trace identifiers(跟踪标识符) - 需要哪些信息标签,以便Zipkin按照逻辑顺序重新组合
Generating identifiers(生成标识符) - 如何生成这些ID(标识)以及应继承哪些ID(标识)
Communicating trace information(沟通跟踪信息) - 发送给Zipkin的附加信息以及跟踪和他们的ID。
3.Timestamps and duration(时间戳和持续时间) - 如何记录关于操作的时间信息。Core data structures (核心数据结构)
核心数据结构在Thrift评论中详细记录。 这里有一个高级描述来帮助你开始:
Annotation(注解)
注解用于记录及时事件。 有一组核心注解用于定义RPC请求的开始和结束:
cs - Client Send. 客户已提出请求。 这设置了Span(跨度)的开始。
sr - Server Receive: 服务器已收到请求并将开始处理它。 这与cs的区别在于网络延迟和时钟抖动的组合。
ss - Server Send: 服务器已完成处理并将请求发送回客户端。 这和sr之间的区别是服务器处理请求所花费的时间。
cr - Client Receive: 客户端已收到来自服务器的响应。 这设置了Span(跨度)的结束。 记录此注释时RPC被认为是完整的。当使用消息代理而不是RPC时,以下注释有助于澄清流程的方向:
ms - Message Send: producer(生产者)向broker(个人理解应该是kafka的broker)发送消息。
mr - Message Receive: consumer(消费者)从 broker(个人理解应该是kafka的broker) 收到消息。与RPC不同,消息传递Span(跨度)永远不会共享Span(跨度)ID。 例如,消息的每个消费者是生产Span(跨度)的不同子范围。
其他注释可以在请求的生命周期中记录下来,以提供进一步的洞察。 例如,在服务器开始时添加注释并结束昂贵的计算可以提供有关在处理请求之前和之后花费多少时间与运行计算花费多少时间的信息。
BinaryAnnotation(二进制注解)
二进制注解没有时间分量。 它们旨在提供有关RPC的额外信息。 例如,在调用HTTP服务时,提供呼叫的URI将有助于稍后分析进入该服务的请求。 二进制注解也可用于Zipkin Api或UI中的精确匹配搜索。
Span(跨度)
与特定RPC对应的一组注释和二进制注释。 Spans包含标识信息,如traceId,spanId,parentId和RPC名称。
跨度通常很小。 例如,序列化形式通常以KiB或更少的量度量。 当跨度增长超出KiB的命令时,会发生其他问题,例如达到Kafka消息大小(1MiB)等限制。 即使您可以提高消息限制,大跨度会增加成本并降低跟踪系统的可用性。 出于这个原因,有意识地存储有助于解释系统行为的数据,而不要存储那些没有的数据。
trace
一组共享一个root span的span。 通过收集共享traceId的所有Spans来构建跟踪。 然后根据spanId和parentId将跨度排列在树中,从而提供请求在整个系统中的路径概览。
附上总结:
- Span:基本工作单元,一次链路调用(可以是RPC,DB等没有特定的限制)创建一个span,通过一个64位ID标识它,
span通过还有其他的数据,例如描述信息,时间戳,key-value对的(Annotation)tag信息,parent-id等,其中parent-id
可以表示span调用链路来源,通俗的理解span就是一次请求信息 - Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
- Annotation: 注解,用来记录请求特定事件相关信息(例如时间),通常包含四个注解信息
先到这里,基本概念就到这里,大部分用到的都能在上面找到,而深入的话需要继续看https://zipkin.io/pages/instrumenting.html此处,官方文档下面还有好多。。用到的时候在查相关概念即可,不冗余的多做翻译了。















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









