







 本文深入剖析Otter和Canal数据同步的3w分析,涵盖工作原理、 Otter的Docker与Release包部署、源码编译,以及常见问题。Otter依赖Canal、Zookeeper、Manager、Node等组件,实现数据库增量日志的准实时同步。文章详细介绍了Otter的搭建过程,包括Docker快速启动、手动配置、源码编译等,并给出了配置流程与食用指南。
本文深入剖析Otter和Canal数据同步的3w分析,涵盖工作原理、 Otter的Docker与Release包部署、源码编译,以及常见问题。Otter依赖Canal、Zookeeper、Manager、Node等组件,实现数据库增量日志的准实时同步。文章详细介绍了Otter的搭建过程,包括Docker快速启动、手动配置、源码编译等,并给出了配置流程与食用指南。
文章目录
一 3w分析及原理运行机制说明
首先, 在了解问题答案之前, 依据3w法则分析一波Otter/Canal。了解了这些更有利于我们解决相关的问题。
why: 为什么要用 ?
简而言之,在数据同步这块儿,目前独树一帜、功能强大、场景覆盖面广。
1. 异构库同步
a. mysql -> mysql/oracle. (目前开源版本只支持mysql增量,目标库可以是mysql或者oracle,取决于
canal的功能)
2. 单机房同步 (数据库之间RTT < 1ms)
a. 数据库版本升级
b. 数据表迁移
c. 异步二级索引
3. 异地机房同步 (比如阿里巴巴国际站就是杭州和美国机房的数据库同步,RTT > 200ms,亮点)
a. 机房容灾
4. 双向同步
a. 避免回环算法 (通用的解决方案,支持大部分关系型数据库)
b. 数据一致性算法 (保证双A机房模式下,数据保证最终一致性,亮点)
5. 文件同步
a. 站点镜像 (进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片).
how怎么用?
安装完之后在Web界面可以配置主库从库的信息,Canal、Pipeline等信息,此外还需要主库开启binlog模式,开通具有salve权限的账号等,之后就可以很轻松在web页面使用数据同步的功能,后文将会详细解析搭建及配置的具体情况。
what是什么?
Canal属于Otter的一个核心组件, Otter除使用了Canal还使用了Node、Manager、Zookeeper等以支持了图形化界面、多节点同步,分布式协调等功能。它能更便捷的利用数据库主从复制的特性,准实时同步增量日志到本机房或异地机房,更便捷的利用到数据同步的场景。简而言之,就是搞数据同步的非常棒的一个开源项目。
原理及运行机制:
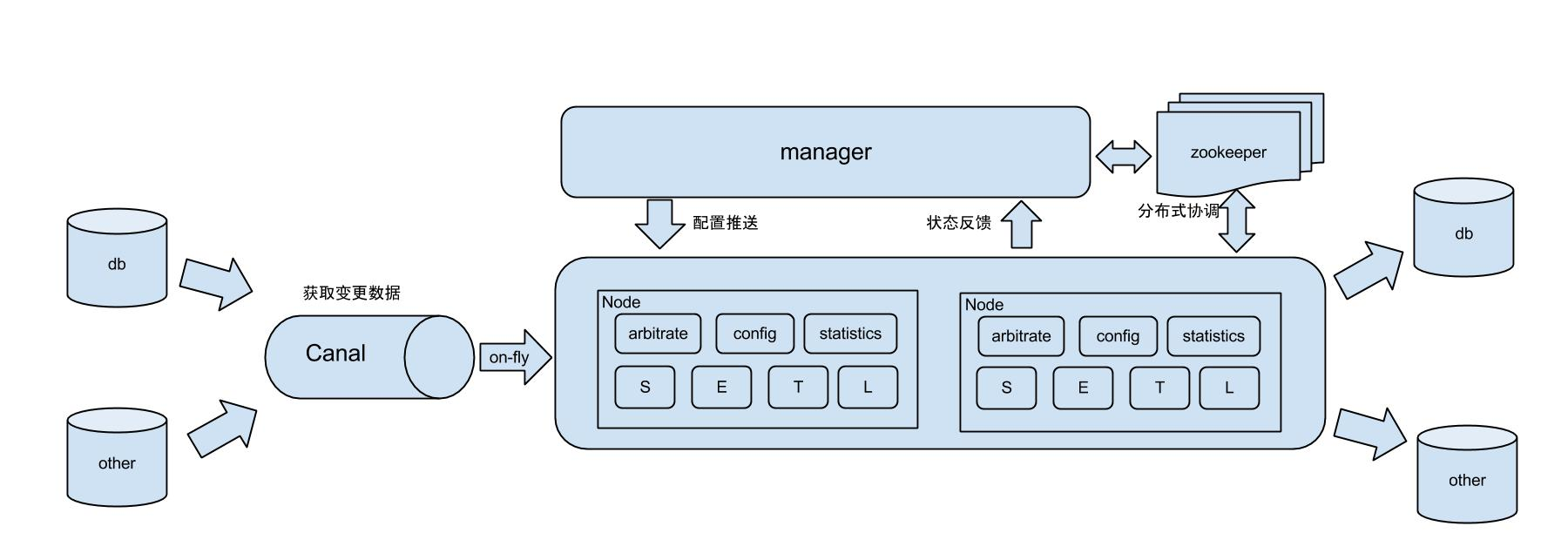
说明:为了更好的支持系统的扩展性和灵活性,将整个同步流程抽象为Select/Extract/Transform/Load,这么4个阶段。
Select阶段: 为解决数据来源的差异性,比如接入canal获取增量数据,也可以接入其他系统获取其他数据等。
Extract/Transform/Load 阶段:类似于数据仓库的ETL模型,具体可为数据join,数据转化,数据Load等。
-
基于Canal开源产品,获取数据库增量日志数据。 什么是Canal, 请点击
-
典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
-
基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作。
特性:
- 使用纯 Java 开发,占时资源比较高
- 基于Canal获取数据库增量日志,Canal是阿里爸爸另外一个开源产品
- 使用manager(web管理)+node(工作节点),manager负责配置监控,node负责处理任务
- 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作
- 使用aria2多线程传输技术,对网络依赖带宽依赖较低
缺点:
Otter使用的技术栈较老,且官方社区目前不是很活跃。
官方文档不够详细且很久没有更新了,学习成本较高。
二 Otter搭建
Otter依赖aria2、Manager、Node、Mysql、Zookeeper等,
-
Manager:Web管理页面
-
Node:工作节点
-
Mysql:存储依赖的表数据
-
Zookeeper:解决分布式状态调度的,允许多node节点之间协同工作
-
aria2:是一个文件通道来保证需要同步的数据通过极快的速度同步到需要同步的服务器上
官方提供了两种搭建方式,一种是Docker部署,一种是Release包部署
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









