







Elasticsearch是什么
- Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
- Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。
- Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件。
- Elastic Stack 是适用于数据采集、充实、存储、分析和可视化的一组开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
Elasticsearch的使用场景
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
Elasticsearch基本概念
- Near Realtime(NRT) :近实时,es从数据写入到数据被搜索到有一个延时(大概1秒),基于es执行的搜索和分析可以达到妙级
- Cluster: 集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称)来决定,节点可以分散到各个机器上。
- Node:节点,集群中的一个节点,如果默认启动1个或者多个节点,那么他们自动组成一个集群。一个elasticsearch实例即就是一个节点。每个节点可以有多个shard,但是primary shard和对应replica shard 不能在同一个节点上。
- index:索引,包含一堆具有相似结构的文档数据,一个索引默认有5个primary shard,一个primary shard 对应一个replica shard,即(5个primary shard 和5个replica shard。(7.0.0之后默认的碎片数量将从5更改为1)
- type:类型,每个索引有一个或者多个type,type是index中的一个逻辑数据分类,一个type下的document,应该都有相同field(6.2.4后只能index单type,7.0.0后移除type)
- document:文档,es中最小的数据单元,由json串组成,里面包含多个field,每个field即是一个数据字段。
Elasticsearch数据类型
1. 核心数据类型
(1)字符串类型: text, keyword
(2)数字类型:long, integer, short, byte, double, float, half_float, scaled_float
(3)日期:date
(4)日期 纳秒:date_nanos
(5)布尔型:boolean
(6)二进制型:binary
(7)范围类型: integer_range, float_range, long_range, double_range, date_range
2. 复杂数据类型
(1)Object:JSON文档是分层的,文档可以包含内部对象, 内部对象也可以包含内部对象.
(2)nested:嵌套类型是对象数据类型的一个特例, 可以让array类型的对象被独立索引和搜索.
(3)array:数组类型
3. 地理数据类型
(1)Geo-point:经纬度坐标
(2)Geo-shape:地理形状类型,是多边形的复杂形状
4. 特殊数据类型
(1)IP: IP类型的字段用于存储IPv4或IPv6的地址, 本质上是一个长整型字段.
(2)Token count:token_count类型用于统计字符串中的单词数量.本质上是一个整数型字段, 接受并分析字符串值,然后索引字符串中单词的个数.
Elasticsearch基本操作
基础操作
#查询集群是否健康
GET /_cat/health?v
#获取所有索引
GET _cat/indices?v
#获得所有type
GET demo/_mapping
#增加索引
PUT people
#删除索引
DELETE people
##增加字段
PUT /people/_mapping
{
"properties": {
"ip": {
"type": "ip"
}
}
}
##新增索引(带设置)
PUT /demo
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "whitespace"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"email": {
"type": "keyword"
},
"tel": {
"type": "keyword"
},
"birthday": {
"type": "date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
单词解释
- cluster ,集群名称
- status,集群状态 green代表健康;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;red代表部分主分片不可用,可能已经丢失数据。
- node.total,代表在线的节点总数量
- node.data,代表在线的数据节点的数量
- shards, active_shards 存活的分片数量
- pri,active_primary_shards 存活的主分片数量
- relo, relocating_shards 迁移中的分片数量,正常情况为 0
- init, initializing_shards 初始化中的分片数量 正常情况为 0
- unassign, unassigned_shards 未分配的分片 正常情况为 0
- pending_tasks,准备中的任务,任务指迁移分片等 正常情况为 0
- max_task_wait_time,任务最长等待时间
- active_shards_percent,正常分片百分比 正常情况为 100%
普通CRUD
#增(没有索引会自动创建)
POST people/_doc
{
"name": "wali",
"detail": "中国很美丽",
"age": 23,
"date": "1996-04-21"
}
#改(id存在修改,不存在则新增)
PUT people/_doc/102
{
"name": "haha",
"detail": "我要去新疆玩",
"age": 24,
"date": "1993-05-21"
}
#查
GET people/_doc/102
#删
DELETE people/_doc/102
#列表
GET people/_search
返回值解释
{
"took":4, 请求花了多少时间(毫秒)
"time_out":false, 有没有超时
"_shards":{ 执行请求时查询的分片信息
"total":5, 查询的分片数量
"skipped":0,
"successful":5, 成功返回结果的分片数量
"failed":0 失败的分片数量
},
"hits":{
"total":2, 查询返回的文档总数
"max_score":0.625, 计算所得的最高分
"hits":[ 返回文档的hits数组
{
"_index":"books", 索引
"_type":"es", 属性
"_id":"1", 标志符
"_score":0.625, 得分
"_source":{ 发送到索引的JSON对象
"title":"Elasticsearch Server",
"publish":2013
}
},
{
"_index":"books",
"_type":"es",
"_id":"2",
"_score":0.19178301,
"_source":{
"title":"Mastering Elasticsearch",
"published":2013
}
}
]
}
}```
单条件查询
以下介绍term、terms、match、multi_match、match_parsh、range
#term(精确查询,对查询的值不分词)
GET people/_search
{
"query":{
"term":{
"detail":"中国"
}
}
}
#terms
GET people/_search
{
"query":{
"terms":{
"age":[23,24]
}
}
}
#match(模糊查询,对查询的值分词)
GET people/_search
{
"query":{
"match":{
"detail":"少年人如初生"
}
}
}
#match_parse(分词必须全部匹配,还要索引位置相邻)
GET people/_search
{
"query":{
"match_phrase":{
"detail":"少年人如初生"
}
}
}
#multi_match(只要一个字段符合既可以)
GET people/_search
{
"query": {
"multi_match": {
"query" : "23",
"fields": ["age","detail"]
}
}
}
#range(区间查询)
GET people/_search
{
"query":{
"range":{
"age":{
"gte":25,
"lte":30
}
}
}
}
分页与排序
#分页查询、排序、指定/排除返回的字段
GET people/_search
{
"_source":{
"includes":["age","id"],
"excludes":["detail"]
},
"query": { "match_all": {} },
"from": 1,
"size": 2,
"sort": [
{ "age": "asc" }
]
}
多条件查询(复合查询)
| 属性 | 说明 |
|---|---|
| must | 文档必须匹配must选项下的查询条件,相当于逻辑运算的AND |
| should | 文档可以匹配should选项下的查询条件,也可以不匹配,相当于逻辑运算的OR |
| must_not | 与must相反,匹配该选项下的查询条件的文档不会被返回 |
| filter | 和must一样,匹配filter选项下的查询条件的文档才会被返回,但是filter不评分,只起到过滤功能 |
需要注意的是,同一个bool下,只能有一个must、must_not、should和filter。
GET people/_search
{
"query": {
"bool": {
"must": {
"terms": {
"age": [23,24]
}
},
"must_not": {
"match": {
"date": "1996-04-21"
}
}
}
}
}
GET people/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"age":30
}
},
{
"match":{
"date":"1996-04-21"
}
}
]
}
}
}
聚合查询
size不设置为0,除了返回聚合结果外,还会返回其它所有的数据。
#max(最大值)
GET people/_search
{
"size": 0,
"aggs": {
"data": {
"max": {
"field": "age"
}
}
}
}
#min(最小值)
GET people/_search
{
"size": 0,
"aggs": {
"data": {
"min": {
"field": "age"
}
}
}
}
#avg(求平均值)
GET people/_search
{
"size":0,
"aggs":{
"data":{
"avg":{
"field":"age"
}
}
}
}
#count(group by)
GET people/_search
{
"size": 0,
"aggs": {
"count": {
"terms": {
"size":100,
"field": "age"
}
}
}
}
#range+avg(区间内求平均值)
GET people/_search
{
"size":0,
"aggs":{
"data":{
"avg":{
"field":"age"
}
}
},
"query":{
"range":{
"age":{
"gte":25,
"lte":30
}
}
}
}
##分段group by
GET people/_search
{
"size": 0,
"aggs": {
"age_count": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 22
},
{
"from": 23,
"to": 25
},
{
"from": 25,
"to": 30
}
]
}
}
}
}
批量操作
#批量操作数据
#bulk的格式:
#{action:{metadata}}\n
#{requstbody}\n (请求体)
#action:(行为),包含create(文档不存在时创建)、update(更新文档)、index(创建新文档或替换已用文档)、delete(删除一个文档)。
#create和index的区别:如果数据存在,使用create操作失败,会提示文档已存在,使用index则可以成功执行。
#metadata:(行为操作的具体索引信息),需要指明数据的_index、_type、_id。
POST people/_bulk
{"index":{"_id":"1"}}
{"name": "章三","detail": "所以产生希望之心。由于留恋,所以保守;由于希望,所以进取。由于保守,所以永远陈旧;","age": 20,"date": "1996-04-20"}
{"index":{"_id":"2"}}
{"name": "张三","detail": "因为敢于冒险,所以能够创造世界。老年人常常厌事,少年人常常喜欢任事。因为厌于事,所以常常觉得天下一切事情都无可作为;","age":21,"date": "1996-04-20"}
{"index":{"_id":"3"}}
{"name": "莉丝","detail": "少年人如初生的虎犊。老年人如坐僧,少年人如飞侠。老年人如释义的字典,少年人如活泼的戏文。老年人如抽了鸦片洋烟,少年人如喝了白兰地","age":22,"date": "1996-04-20"}
{"index":{"_id":"4"}}
{"name": "王守信","detail": "少年人如西伯利亚不断延伸的大铁路。老年人如秋后的柳树,少年人如春前的青草。老年人如死海已聚水成大泽,少年人如长江涓涓初发源。","age":22,"date": "1996-04-20"}
{"index":{"_id":"5"}}
{"name": "李四十","detail": "回想当年在长安繁华的红尘中对春花赏秋月的美好意趣。清冷的长安太极、兴庆宫内,满头白发的宫娥,在结花如穗的灯下,三三五五相对而坐","age":24,"date": "1996-04-21"}
{"index":{"_id":"6"}}
{"name": "王六","detail": "与三两个看守的狱吏,或者前来拜访的好事的人,谈当年佩着短刀独自骑马驰骋中原,席卷欧洲大地,浴血奋战在海港、大楼,一声怒喝,令万国震惊恐惧的丰功伟业","age":25,"date": "1996-04-21"}
{"index":{"_id":"7"}}
{"name": "王五","detail": "起初高兴得拍桌子,继而拍大腿感叹,最后持镜自照。真可叹啊,满脸皱纹、牙齿落尽,白发正堪一把,已颓然衰老了!象这些人","age":26,"date": "1996-04-21"}
{"index":{"_id":"8"}}
{"name": "李深爱","detail": "日常起居饮食,依赖于别人。今日得过且过,匆匆哪知他日如何?今年得过且过,哪里有闲暇去考虑明年?普天之下令人灰心丧气的事","age":26,"date": "1996-04-21"}
{"index":{"_id":"9"}}
{"name": "wali","detail": "我是个性格开dao朗对生活充满du信心的人,喜欢zhi帮助dao别人内,在帮助别人的时候才是能够体容现自我价值的时候。","age":28,"date": "1996-04-21"}
{"index":{"_id":"10"}}
{"name": "张阳山","detail": "具有丰富项目经验,良好的变成习惯以及有较强的学习适应能力","age":29,"date": "1996-04-21"}
{"index":{"_id":"11"}}
{"name": "陈奥里","detail": "我是一个爱学习,知上进,善沟通,重细节,懂感恩的人","age":30,"date": "1996-04-21"}
分词器
#查询分词结果
POST /_analyze
{
"analyzer": "standard",
"text": "少年人如初生"
}
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "lsp是风向标"
}
POST /_analyze
{
"analyzer": "ik_smart",
"text": "少年人如初生"
}
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "少年人如初生"
}
#设定分词器
PUT /people
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_smart"
}
}
}
Elasticsearch为什么可以这么快
倒排索引
都说倒排索引提升了搜索的速度,那么具体采用了哪些架构或者数据结构来达成这一目标?
这里我们先来模拟一下倒排索引,假设有个user索引,拥有如下数据,那么根据这个索引我们可以建立如下的倒排索引
| id | name | age | detail |
|---|---|---|---|
| 1 | 张三 | 21 | 浙江省杭州市 |
| 2 | 李四 | 22 | 浙江省宁波市 |
| 3 | 王五 | 21 | 江苏省南京市 |
name字段
| term | posting List |
|---|---|
| 张三 | 1 |
| 李四 | 2 |
| 王五 | 3 |
age字段
| term | posting List |
|---|---|
| 21 | 1,3 |
| 22 | 2 |
detail字段
| term | posting List |
|---|---|
| 浙江省 | 1,2 |
| 杭州市 | 1 |
| 宁波市 | 2 |
| 江苏省 | 3 |
| 南京市 | 3 |
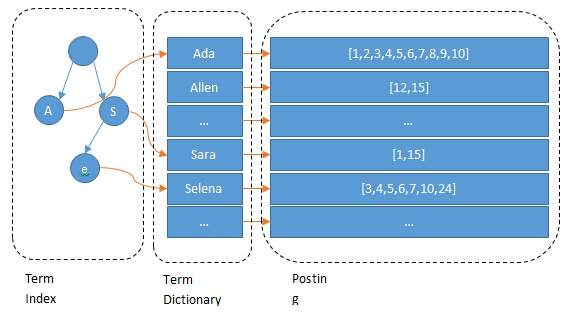
Term Dictionary
假设我们有很多个 term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的 term 一定很慢,因为 term 没有排序,需要全部过滤一遍才能找出特定的 term。排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的 term。这个就是 term dictionary。有了 term dictionary 之后,可以用 logN 次磁盘查找得到目标。
term Index
但是磁盘的随机读操作仍然是非常昂贵的(一次 random access 大概需要 10ms 的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 term dictionary 本身又太大了,无法完整地放到内存里。于是就有了 term index。term index 有点像一本字典的大的章节表。比如:
A 开头的 term ……………. Xxx 页
C 开头的 term ……………. Yyy 页
E 开头的 term ……………. Zzz 页
如果所有的 term 都是英文字符的话,可能这个 term index 就真的是 26 个英文字符表构成的了。但是实际的情况是,term 未必都是英文字符,term 可以是任意的 byte 数组。而且 26 个英文字符也未必是每一个字符都有均等的 term,比如 x 字符开头的 term 可能一个都没有,而 s 开头的 term 又特别多。实际的 term index 是一棵 trie 树:
例子是一个包含 “A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 的 trie 树。这棵树不会包含所有的 term,它包含的是 term 的一些前缀。通过 term index 可以快速地定位到 term dictionary 的某个 offset,然后从这个位置再往后顺序查找。
FST(finite-state transducer)
es也就是lucene索引的底层数据结构是trie树的一个变种,也就是FST,对于FST的详细解释我们可以看下以下这篇文章
FST
现在我们可以回答“为什么 Elasticsearch/Lucene 检索可以比 mysql 快了。Mysql 只有 term dictionary 这一层,是以 b-tree 排序的方式存储在磁盘上的。检索一个 term 需要若干次的 random access 的磁盘操作。而 Lucene 在 term dictionary 的基础上添加了 term index 来加速检索,term index 以树的形式缓存在内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的 random access 次数。
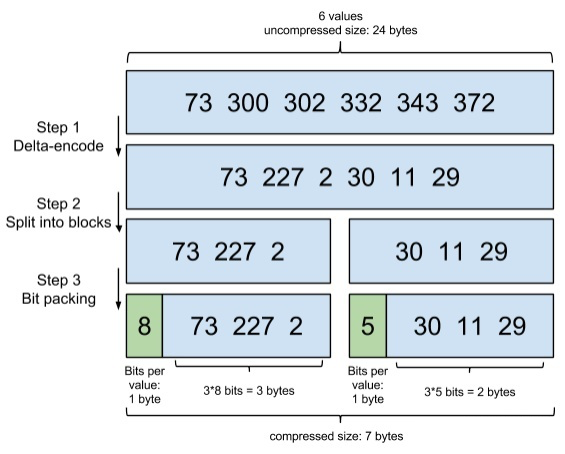
posting list的优化
当我们找到指定的term时,展现给我们的是一个posting list列表,但是这个posting list可能会特别的庞大,(例如这个字段为性别)那么我们需要对posting list继续进行优化。
例如有如下一个数组
[73, 300, 302, 332, 343, 372]
step1:
我们将数组变成增量的
[73, 227, 2, 30, 11, 29]
step2:
将数组分隔为块
[73, 227, 2], [30, 11, 29]
step3:
按需分配空间
第一个块,[73, 227, 2],最大元素是227,需要 8 bits,那么这个块的每个元素,都分配 8 bits的空间。
第二个块,[30, 11, 29],最大的元素才30,只需要 5 bits,那么这个块的每个元素就只分配 5 bits 的空间。
Roaring bitmaps
说到Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有某个posting list:[1,3,4,7,10],那么对应的bitmap就是:[1,0,1,1,0,0,1,0,0,1]。
非常直观,用0和1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性:
将posting list按照65535为界限分块,比如第一块所包含的文档id范围在065535之间,第二块的id范围是65536131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。
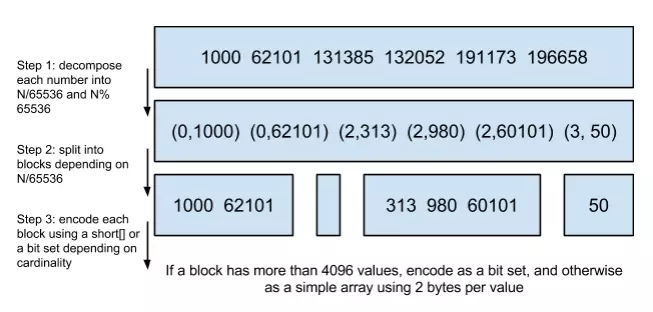
为什么是以65535为界限?”
程序员的世界里除了1024外,65535也是一个经典值,因为它=2^16-1,正好是用2个字节能表示的最大数,一个short的存储单位,注意到上图里的最后一行“If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”,如果是大块,用节省点用bitset存,小块就用一个short[]存着方便。
那为什么用4096来区分采用数组还是bitmap的阀值呢?
这个是从内存大小考虑的,当block块里元素超过4096后,用bitmap更剩空间: 采用bitmap需要的空间是恒定的: 65536/8 = 8192bytes 而如果采用short[],所需的空间是: 2xN(N为数组元素个数) 2x4096=8192。
es是如何写数据的
写数据过程
1.客户端选择一个node发送请求,这个node被称做coordinating node(协调节点)。
2.协调节点对docmount进行路由,将请求转发给到对应的primary shard
3.primary shard 处理请求,将数据同步到所有的replica shard
4.此时协调节点,发现primary shard 和所有的replica shard都处理完之后,就反馈给客户端。
写数据原理
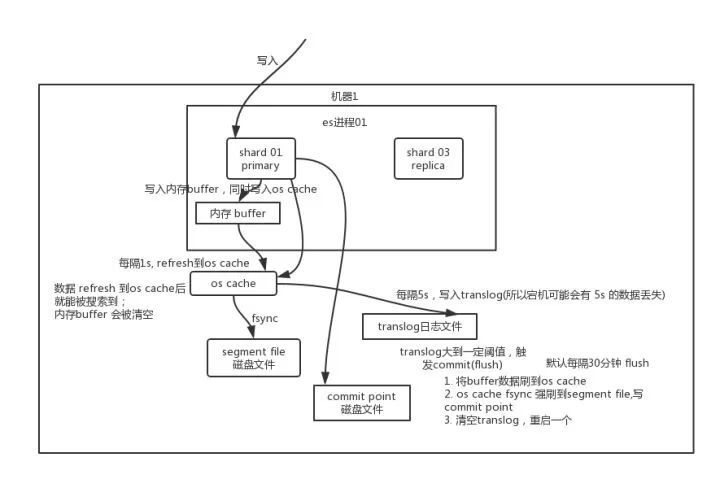
1、先写入内存buffer,在buffer里的时候数据是搜索不到的;同时将数据写入translog日志文件。
如果buffer快满了,或者到一定时间,就会将内存buffer数据refresh 到一个新的segment file中,但是此时数据不是直接进入segment file磁盘文件,而是先进入os cache。这个过程就是 refresh。
每隔1秒钟,es将buffer中的数据写入一个新的segment file,每秒钟会写入一个新的segment file,这个segment file中就存储最近1秒内 buffer中写入的数据。
2、但是如果buffer里面此时没有数据,那当然不会执行refresh操作,如果buffer里面有数据,默认1秒钟执行一次refresh操作,刷入一个新的segment file中。操作系统里面,磁盘文件其实都有一个东西,叫做os cache,即操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去。只要buffer中的数据被refresh 操作刷入os cache中,这个数据就可以被搜索到了。
3、为什么叫es是准实时的?NRT,全称 near real-time。默认是每隔1秒refresh一次的,所以es是准实时的,因为写入的数据1s之后才能被看到。可以通过es的restful api或者 java api,手动执行一次 refresh操作,就是手动将buffer中的数据刷入os cache中,让数据立马就可以被搜索到。只要数据被输入os cache中,buffer 就会被清空了,因为不需要保留buffer了,数据在translog里面已经持久化到磁盘去一份了。
4、重复上面的步骤,新的数据不断进入buffer和translog,不断将buffer数据写入一个又一个新的segment file中去,每次refresh完buffer清空,translog保留。随着这个过程的推进,translog会变得越来越大。当translog达到一定长度的时候,就会触发commit操作。
5、commit操作发生的第一步,就是将buffer中现有的数据refresh到os cache中去,清空buffer。然后将一个commit point写入磁盘文件,里面标识者这个commit
point 对应的所有segment file,同时强行将os cache中目前所有的数据都fsync到磁盘文件中去。最后清空现有 translog日志文件,重启一个translog,此时commit操作完成。
6、这个commit操作叫做flush。默认30分钟自动执行一次flush,但如果translog过大,也会触发flush。flush操作就对应着commit的全过程,我们可以通过es api,手动执行flush操作,手动将os cache中数据fsync强刷到磁盘上去。
7、translog日志文件的作用是什么?
执行commit 操作之前,数据要么是停留在buffer中,要么是停留在os cache中,无论是buffer 还是os cache都是内存,一旦这台机器死了,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件translog中,一旦此时机器宕机了,再次重启的时候,es会自动读取translog日志文件中的数据,恢复到内存buffer和os cache中去。
8、translog其实也是先写入os cache的,默认每隔5秒刷一次到磁盘中去,所以默认情况下,可能有5s的数据会仅仅停留在buffer或者translog文件的os cache中,如果此时机器挂了,会丢失5秒钟的数据。但是这样性能比较好,最多丢5秒的数据。也可以将translog设置成每次写操作必须是直接fsync到磁盘,但是性能会差很多。
9、es是近实时的,数据写入1秒后就可以搜索到:可能会丢失数据的。有5秒的数据,停留在buffer、translog os cache 、segment file os cache中,而不在磁盘上,此时如果宕机,会导致5秒的数据丢失。
总结:
(1).数据先写入内存buffer,然后每隔1s,将数据refresh到 os cache,到了 os cache数据就能被搜索到(所以我们才说es从写入到能被搜索到,中间有1s的延迟)。
每隔5s,将数据写入到translog文件(这样如果机器宕机,内存数据全没,最多会有5s的数据丢失),translog达到一定程度,或者默认每隔30min,会触发commit操作,将缓冲区的数据都flush到segment file磁盘文件中。数据写入 segment file之后,同时就建立好了倒排索引。
(2)如果是删除操作,commit的时候会生成一个 .del文件,里面将某个doc标识为 deleted状态,那么搜索的时候根据 .del文件就知道这个doc是否被删除了。
(3)如果是更新操作,就是将原来的doc标识为deleted状态,然后重新写入一条数据。
总结
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
1.不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
2.不需要analysis的字段我们采用keyword
附
常用字典数据结构
很多数据结构均能完成字典功能,总结如下。
| 数据结构 | 优缺点 |
|---|---|
| 排序列表Array/List | 使用二分法查找,不平衡 |
| HashMap/TreeMap | 性能高,内存消耗大,几乎是原始数据的三倍 |
| Skip List | 跳跃表,可快速查找词语,在lucene、redis、Hbase等均有实现。相对于TreeMap等结构,特别适合高并发场景 |
| Trie | 适合英文词典,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存 |
| Double Array Trie | 适合做中文词典,内存占用小,很多分词工具均采用此种算法 |
| Ternary Search Tree | 三叉树,每一个node有3个节点,兼具省空间和查询快的优点 |
| Finite State Transducers (FST) | 一种有限状态转移机,Lucene 4有开源实现,并大量使用 |
自定义词典
ik分词器是基于词典进行分词的,对于一些热点词汇比如最近比较火的”耗汁尾汁“我们希望es能够识别出来,那么我们就需要定义自己的扩展词典。
在安装完ik分词器后我们可以修改ik插件下config目录中的IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">gyy.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
这里一定要注意一定要从第二行开始写入词语或短语,ik不读第一行的词语
gyy.dic文件
lsp是风向标
yk很帅
zfh是巨人
耗汁尾汁
重启es服务之后,可以发现自定义词典已经生效了
测试地址
es6.5.4
kibana: http://kibana.nps.fuguicun.com/app/kibana#/dev_tools/console?_g=()
es: http://es.nps.fuguicun.com/
es7.6.2
kibana:http://kibana7.nps.fuguicun.com/app/kibana#/dev_tools/console
es:http://es7.nps.fuguicun.com/















 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









