






作者按:本文节选自我在SDCon 2024全球软件研发技术大会上的主题演讲,因篇幅有限,有所删减。

自从大模型吹响新一轮技术革命的号角后,整个行业各个层次都面临大模型带来的范式转换。我今年在4月份上海举办的全球机器学习技术大会上演讲时曾提出,大模型为计算产业带来了计算范式、开发范式、交互范式的三大范式改变。今天是软件研发技术大会,我想和大家来重点谈谈这一年来对软件开发智能化范式改变的思考与探索。
我曾在23年4月份全球软件研发技术大会上提出《五级“自动软件开发”参考框架》,借鉴了自动驾驶行业的五级划分方法,将智能化软件开发的水平分为L1~L5级。

这一参考框架也在这一年多的研发实践、和众多客户合作、海内外专家研讨的过程中,不断得到完善和丰富。在软件开发智能化的实践和探索中,我也发现业界存在以下几个比较突出的误区。

第一个误区,Github Copilot等代码大模型工具出来之后,大家会发现它在日常比较简单的代码上确实不错,但一旦到真实的企业级项目里表现可能就没有期望的那么好,为什么?目前的大模型主要都以Github等开源代码为主在训练。这些代码我称之为结果数据,是经过编译、运行、以及正确性验证的代码。但是它的过程数据基本没有得到训练。这既不是人类生物神经网络(ANN)学习的方式,也不是大模型这种数字神经网络(BNN)正确的学习方式。
第二个误区,目前的代码大模型,主要基于软件系统的静态特征来进行训练。但是如果我们看ChatGPT和Sora等在自然语言上和视觉上的训练,它们的表现显然效果要好于代码领域,为什么?其实在自然语言领域和视觉领域的训练,具有相当的动态性,语言的上下文、前因后果、故事线,视频的时间轴……这些动态信息蕴含了丰富的知识和逻辑,但软件开发领域把动态性的特质数据引入模型训练还是比较少的。
第三个误区,大模型出来之后,可以说通过了图灵测试,在某些方面也超过了普通人类的水平。这很容易给我们一个希望,去追求一个一步到位一劳永逸的智能方式。我记得去年4月份我们在上海举办SDCon 2023全球软件研发技术大会的时候,很多业界朋友都特别期待说我能不能把我的需求一股脑的告诉大模型,大模型就能给我生成真正跑起来的项目?经过一年多之后,我们越来越发现这是不现实的,我今天想讲的是这个期望长期来看也是不现实的,因为没有一劳永逸、一步到位的智能。
第四个误区,Scaling Law被业界奉为圭皋之后,很多人都在想去追求一个一超多能的超级智能。希望用一个超级模型,把软件开发项目中各种复杂的问题都一股脑的解决,这个也是相当不现实的。正如复杂的人类世界不可能靠一个超人来解决,复杂的软件领域也不可能靠一个超级模型来解决。
针对以上几个误区,我想谈一些实践和探索的观点和思考。

大模型出来之后,我们一部分人老是觉得上个时代的东西都应该彻底丢掉了,大模型给我们带来了一个全新的世界。我想强调的是我们在上个时代积累的宝贵经验和智慧,不是被废弃了,而是被AI压缩和加速了。因为这些经验和智慧也是人类知识的一部分。
接下来我们来看看,在大模型时代,有哪些宝贵的经验和智慧可以帮助我们在软件领域做得更好?我们说软件系统有四个复杂的特征,分别是:复杂性、动态性、协作性、混沌性。

首先来看复杂性。在软件系统中解决复杂性有两个常用的手段,第一个是分解,第二个是抽象。

分解是我们在面向过程编程中就有的一个非常有效的手段。包括后来的分层架构、组件化设计、微服务架构等都源自分解思想。但很快,我们发现光有分解是不够的,必须使用抽象,这就发展出来面向对象、泛型编程、领域驱动设计、概念驱动设计等方法。如果我们看大模型,它在“分解”上做得还是不错的,但是在“抽象”上就有点差强人意。

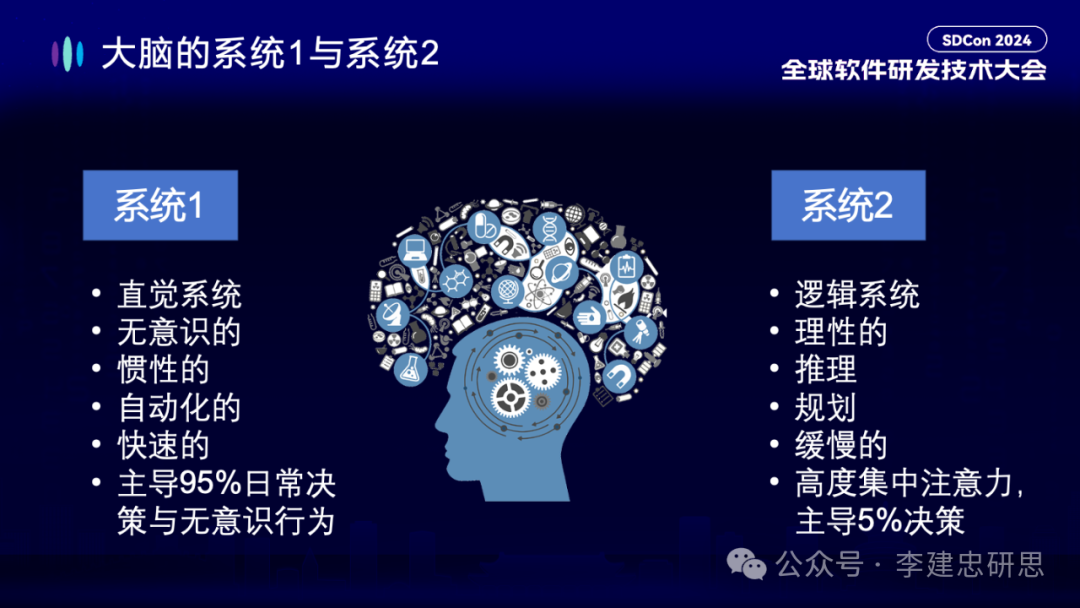
就目前的大模型辅助软件研发的能力来看,它比较擅长什么?类型实现、函数实现、算法实现等低抽象任务;但一旦遇到设计模式、架构设计、系统设计等“高抽象任务”,就发现它往往表现的不够好。在这方面,我们的建议是要向大模型导入我们在“高抽象任务”方面积累的宝贵的方法论、原则和最佳实践等。它们未必是代码,还包括设计图、设计文档等。这某种程度上,也是在提升大模型“System 2”的能力。
System 1和System 2是诺贝尔经济学奖得主丹尼尔·卡尼曼在《思考快与慢》中提出的人类的两种思考模式。系统一是直觉的、快速的、无意识的,主导我们日常95%的决策。系统二是基于逻辑的、理性的、规划的、缓慢的,需要高度集中注意力,主导我们日常5%的决策。System 2的能力对于大模型在软件开发领域的“抽象能力”至关重要。
第二个部分,我想谈谈软件的动态性。所谓动态性本质是我们的软件系统一直在动态的演化。我们知道软件开发领域最早一直想追求top-down的瀑布模型,但后来业界越来越发现在很多领域瀑布模型很难work。究其根本,是软件开发过程有一个“时间”变量,软件的需求、所处环境、开发组织等无时无刻不在变化。
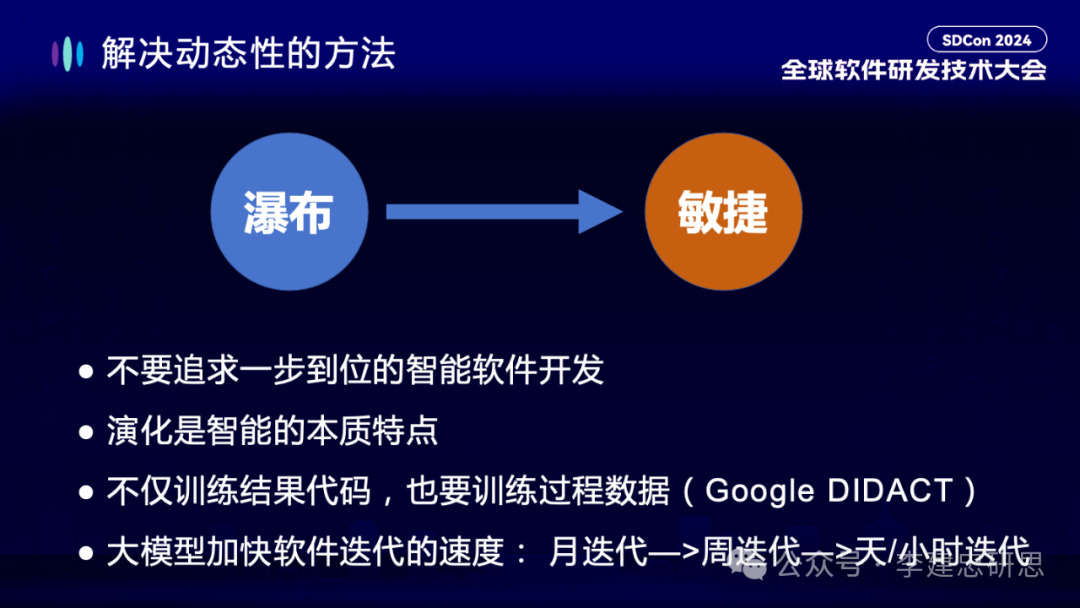
这种“动态性”在大模型时代会改变吗?我想大概率不会。所以我们也不能追求一步到位的智能软件开发。
演化是智能的本质特点。智能从来都不是一步到位的,智能就是在迭代试错反复中不断成长的。我认为在大模型时代,敏捷软件开发并不会被丢弃,而是从“组织的敏捷”变为“模型的敏捷”,而且会加速敏捷。在敏捷开发之前,软件开发的周期是以年为单位迭代,比如Windows 95、Windows 98。在敏捷开发之后,软件行业进入以月为单位迭代或者以周为单位迭代。在大模型时代,软件开发将进入以天或者小时为单位进行迭代。
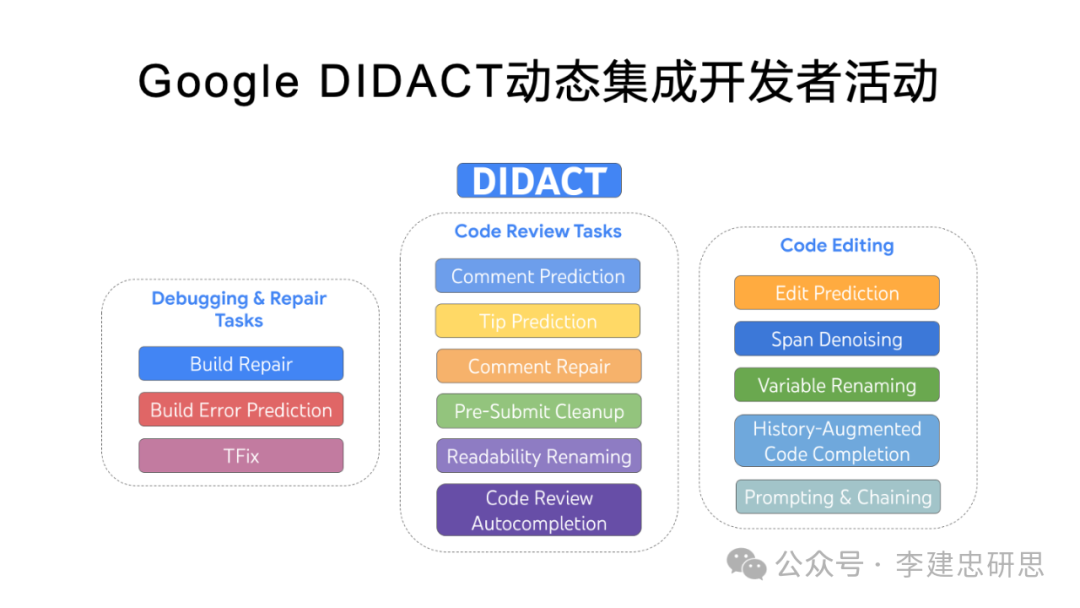
除了提升迭代速度外,我们也需要对更多的软件开发过程数据进行训练,来帮助模型更好地理解软件开发的“动态性”。这里可以参考一下Google最近发布DIDACT(Dynamic Integrated Developer ACTivity 动态集成开发者活动),参考:https://research.google/blog/large-sequence-models-for-software-development-activities/
从根本上来说,软件开发并非孤立的过程,而是在人类开发者、代码审查者、错误报告者、软件架构师和工具(如编译器、单元测试、代码检查工具和静态分析器等)之间进行的对话。DIDACT使用软件开发过程作为训练数据来源,而不仅是最终的完成代码。通过让模型接触开发者在工作中看到的上下文,结合他们的响应行为,模型可以学习软件开发的动态性。

Google DIDACT的研发也发现在学习过程数据之后,模型生成软件项目的过程,非常类似人类开发团队,先编写比较粗粒度的接口和框架代码,然后一点一点把它们细化实现,包括也有反复和试错的过程。而不是大家最开始想象的那种从上到下一行一行写的过程,整个项目一气呵成。真实的软件开发不是这样,人类开发团队不是这样,大模型驱动的智能软件开发也不会是这样。
接下来我想谈谈架构设计领域的协作性。我们知道当软件系统越来越复杂时,组件与组件之间的协作,服务与服务之间的协作,会变成非常重要的课题。早在1967年计算机科学家Melvin Conway就提出了著名的“康威定律”。
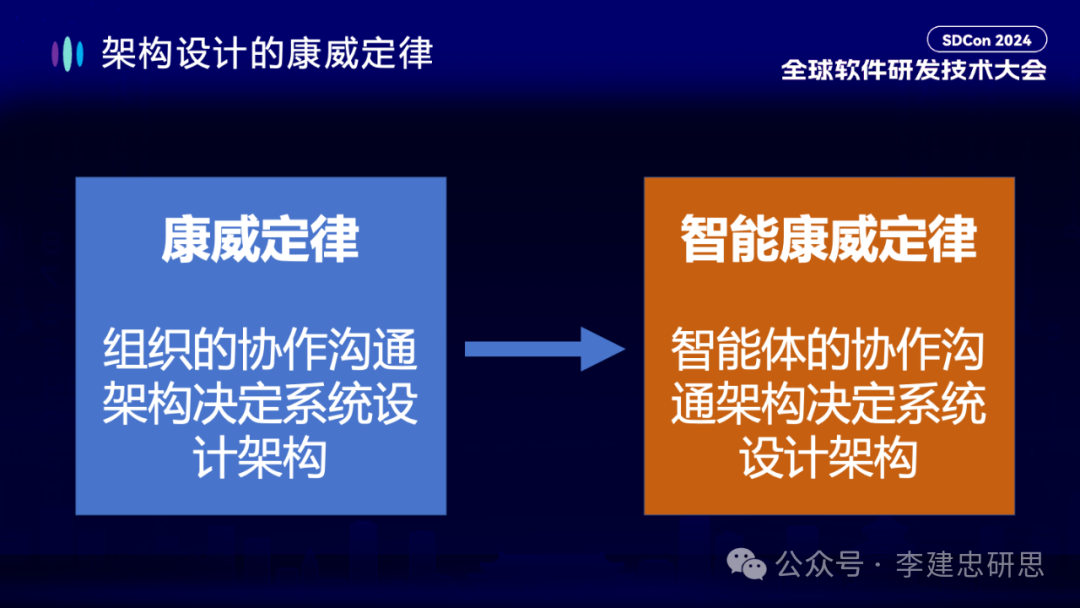
康威定律指出“组织的协作沟通架构,决定了我们的系统设计架构”,这在架构设计领域被奉为第一定律。那么在大模型时代,软件内部需不需要协作?显然是需要的,我们仍然需要许许多多的组件或服务进行协作。只是这时候的组件或服务的构建者,不见得是软件团队,而是一个一个智能体(Agent)。那么这些智能体之间当然也需要协作。它们的协作也要遵循康威定律。我称之为“智能康威定律”:智能体的协作沟通架构,决定系统设计架构。
我们再来谈一下软件开发中的工具,来实现在所谓混沌系统中寻求确定性的部分。我们知道现在大模型很多时候做的是一些非确定性的计算(或者叫概率性计算),但这并不意味着我们所有的任务都要用非确定性计算。我们在大模型之前积累了很多确定性计算的工具,它们在大模型时代也不会被丢弃,而是与大模型进行很好的融合。融合方式就是通过Agent(工具)来实现工具调用。
简单总结一下。针对前面提到的软件系统的四大特性:复杂性、动态性、协作性、混沌性,在大模型时代智能软件开发范式下,我们需要特别关注以下四大核心能力建设:

第一个抽象能力 怎么训练、怎么提升大模型的抽象能力,也就是System 2的能力,是一个很重要的课题。
第二个演化能力 如何支持大模型在整个软件开发过程中加速我们的迭代周期,它不仅能快速发布高质量的软件,同时对模型能力也是一个快速的提升。
第三个协作能力 我们需要仔细设计智能体的协作架构,来支持我们的系统设计架构。
第四个工具能力 使用工具来解决混沌系统中的确定性问题。
最后我想谈一下,提升软件开发的智能化水平是一个系统工程,前面讲的这四大核心能力,它背后需要很多基础建设,包括模型方面的建设、和数据方面的建设。我列了10个主要的方面:

第一:扩展定律 Scaling Law并没有停止,仍然在发挥着重要作用,这个是我们对基础模型方面继续要期待的。
第二:提高上下文窗口 上下文窗口是大模型的“内存”,它对最大化发挥模型能力有着关键影响。这一块国内外都进展飞速。
第三:长期记忆能力 大型软件项目蕴含的信息量浩瀚纷繁,大模型的长期记忆也很重要,虽然有RAG等外部检索技术的快速发展,但基础架构方面的创新也值得期待。
第四:System 2的提升 目前的大模型普遍被认为是一个高中生的水平。如何提升大模型系统2的能力,关系到大模型是否能够成为一个深思熟虑的专家级学者,从而来胜任软件开发这样具有较高智慧要求的工作。
第五:降低模型幻觉 降低模型幻觉仍然是业界需要克服的一个问题,虽然我们也不要期望彻底消除幻觉。某种程度上可以说,幻觉也是智能的一部分,如果没有幻觉,智能也将失去创造力。
第六:研发全流程数字化 如何把研发流程里尽可能多的开发者活动按时间顺序记录下来,比如:文档、设计图、代码、测试代码、运维脚本、会议记录、甚至设计决策中的争论等等各种数据,然后变成数字化的语料,喂给我们的大模型。
第七:多模态数据训练 软件开发领域不只是代码和文本,还有很多设计图比如UML、表格、甚至视频等数据。
第八:将模型做“小”软件开发中很多细分任务都不见得需要所谓的“大模型”,而是在高质量垂类数据训练下的“小模型”,比如bug修复,比如开发者测试,比如clean code。
第九:模型合成数据 通过模型生成代码、设计、注释等,作为语料供给另外的模型进行训练,也是在软件开发中一个非常活跃的发展方向。
第十:多智能体协同 针对复杂的软件工程任务,未来一定是众多不同角色、不同模型、不同任务的智能体的群策群力。
最后,软件开发智能化范式转换的大幕才刚刚开启,中间还有很多曲折等待我们去探索,希望今天的分享能给大家带来启发,谢谢大家!















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









