






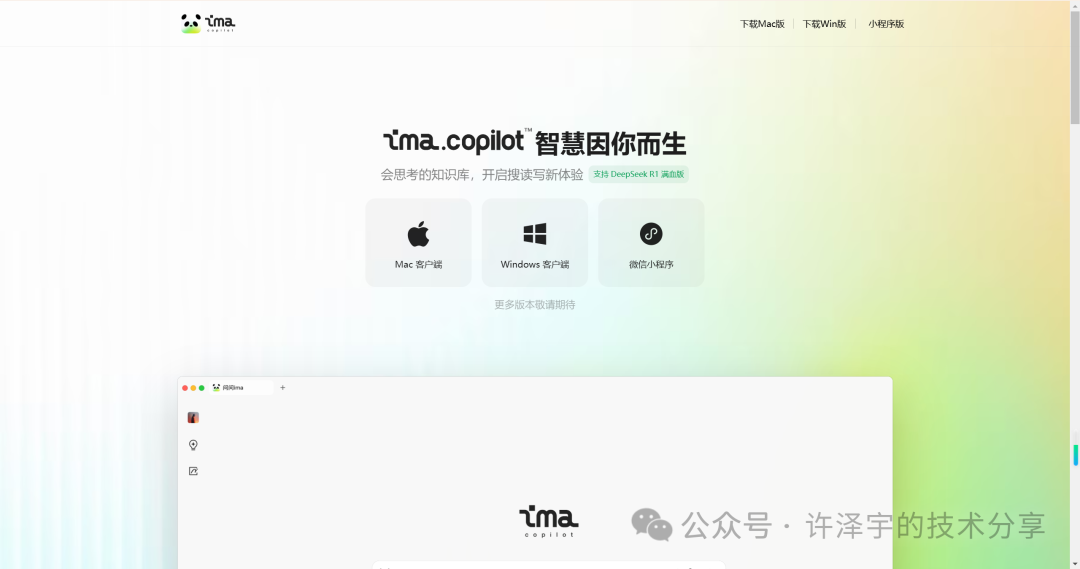
在AI技术井喷式发展的今天,工具类应用正从“通用化”向“个性化”迈进。腾讯近期推出的智能工作台ima.copilot(以下简称ima),凭借其“会思考的知识库”定位,迅速成为职场人、学生党的效率神器。它不仅整合了搜索、阅读、写作三大核心功能,更通过DeepSeek-R1模型的接入和RAG技术(检索增强生成)的深度应用,将个人知识管理推向了“越用越懂你”的智能时代。今天,我们就从技术视角拆解这款产品的创新之处,以及它如何成为你的“第二大脑”。
一、从“工具”到“伙伴”:ima的三大核心能力解析
1. 全网+知识库双引擎搜索:打破信息孤岛

传统搜索引擎的痛点在于信息过载且缺乏个性化筛选。ima的搜索功能分为两种模式:
全网搜索:基于腾讯生态(如微信公众号、专业文章)的优质内容库,结合语义理解生成结构化答案,并附带参考资料和文内引用,支持一键生成思维导图。
知识库搜索:用户可将本地文件、网页链接、笔记等内容导入个人知识库,AI通过向量化存储和动态检索技术,快速调用私有化数据。
这种“双引擎”设计,既能满足泛领域信息获取,又能精准调用个人积累的知识,尤其适合金融、法律等需高频调用专业资料的场景。


2. 文档解读:从“读不完”到“秒懂”
面对数十页的论文或财报,ima的文档解读功能堪称“降维打击”:
智能提炼:自动生成摘要、提取核心观点,甚至标注关键数据。
深度问答:用户可直接针对文档内容提问(如“第三季度的毛利率变化原因是什么?”),AI结合上下文生成答案,并支持溯源至原文段落。
多模态支持:支持PDF、Word、网页链接等多种格式,甚至可对截图中的文字进行识别分析。
3. 智能写作:从“憋字”到“协作共创” 46
无论是学术论文还是小红书文案,ima的写作辅助功能覆盖全场景:
模板化创作:内置论文、作文、营销文案等模板,用户只需输入主题,AI自动生成大纲并填充内容。
参考文档融合:写作时可调用本地文件或知识库内容作为参考,AI基于此生成符合用户风格的文本。
动态交互:输入“/”可随时唤起AI,完成扩写、缩写、翻译等操作,实现“人机协同”的流畅体验。
二、技术底座:RAG+多模型融合,如何让知识库“活起来”?
1. RAG技术:赋予大模型“长期记忆”
通用大模型(如GPT-4)的短板在于缺乏个性化数据,而ima通过RAG技术将用户知识库向量化存储,形成私有化索引。当用户发起请求时,系统先检索知识库中的高相关性内容,再将其作为上下文输入大模型生成答案。这种“检索-生成”的协同机制,既保证了答案的准确性,又避免了大模型的“幻觉”问题。
2. DeepSeek-R1模型:垂直领域的“超强外挂”
2025年2月,ima宣布接入深度求索(DeepSeek)的R1模型。与通用模型相比,R1在长文本理解和逻辑推理上表现突出:
长上下文窗口:可处理超过10万token的文本,适合分析财报、法律条文等复杂文档。
领域微调优化:针对金融、医疗等场景进行定向训练,例如在腾讯医典的急救知识库中,R1能精准输出符合医学规范的操作指南。
用户可在ima中自由切换腾讯混元大模型和DeepSeek-R1,兼顾通用性与专业性。
3. 动态知识图谱:让知识“自我生长”
每一次搜索、写作或文档导入,都会触发知识库的自动更新:
语义关联:AI自动为内容添加标签,并建立跨文档的关联关系(如“2024年财报”与“行业趋势分析”)。
主动推荐:基于用户行为,推荐相关知识卡片或未读文档,实现“越用越懂你”的个性化体验。
三、场景革命:从学生到职场人,ima如何成为效率倍增器?
1. 学术研究:论文写作的全周期助手
选题阶段:通过全网搜索快速锁定前沿方向,生成研究背景综述。
资料整理:自动归类参考文献,提炼核心论点并生成对比表格。
写作阶段:调用知识库中的实验数据,辅助完成方法论描述和结果分析。
2. 职场办公:秒变行业专家
竞品分析:上传多家公司的财报,AI自动提取关键指标并生成可视化对比。
法律合规:导入合同文本后,AI可标记风险条款并提供修改建议。
会议效率:录音文件转文字后,自动生成纪要并提取待办事项。
碎片化整合:微信文章、网页链接、会议笔记一键存入知识库,避免信息散落。
跨领域连接:AI自动发现不同领域知识的关联(如“心理学原理在用户增长中的应用”)。
知识传承:支持将知识库分享给团队或新人,减少信息传递损耗。
四、未来展望:从“效率工具”到“认知伙伴”
ima的推出,标志着AI应用从“功能导向”转向“认知协作”。随着多模态交互和自适应学习技术的成熟,未来的知识库可能进一步实现:
跨设备无缝同步:手机、PC、AR眼镜的多端实时联动。
主动式知识推送:基于用户日程自动推荐相关材料(如会议前推送客户背景报告)。
个性化模型微调:用户可训练专属的小模型,与通用大模型协同工作。
结语:你准备好拥抱“第二大脑”了吗?
腾讯ima.copilot的爆火并非偶然。它精准抓住了信息过载时代的两大痛点——知识碎片化与创作效率低下,并通过AI技术将其转化为“越用越智能”的解决方案。无论是学生、研究者,还是职场人,只要善用这款工具,就能将有限的精力聚焦于真正的价值创造。正如网友所言:“以前是我在找信息,现在是信息在找我。”
立即访问ima.qq.com,开启你的智能进化之旅。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









