






理想很丰满,现实也还行,实测了一下腾讯的IMA的知识库功能,投喂影刀RPA开发文档后,让它帮我写点代码,初看错误率不算大,当然要稳定运行,肯定还要作一些调整,这足以走向提升效率的路上。
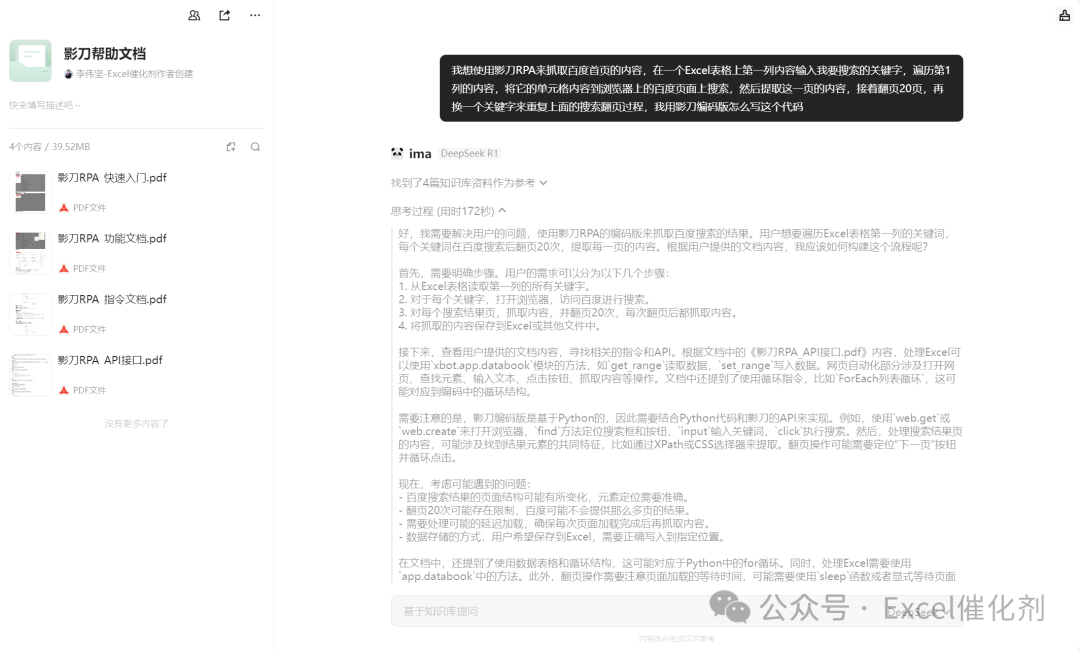

经过思考后,真的开始给我写代码了
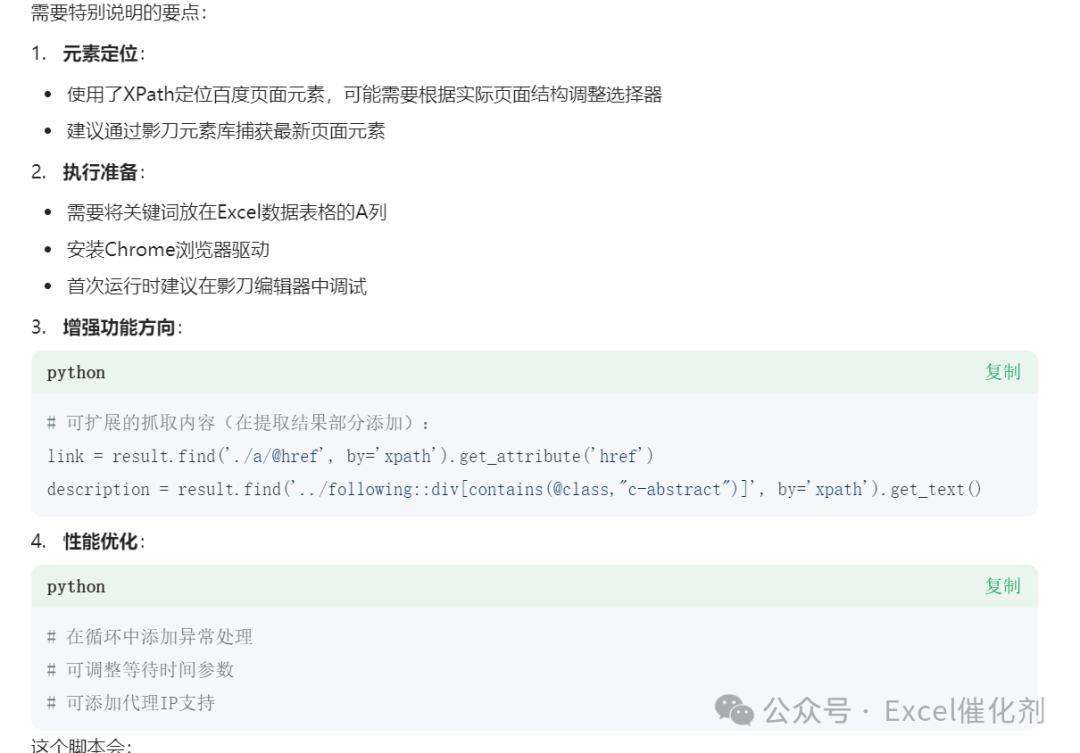
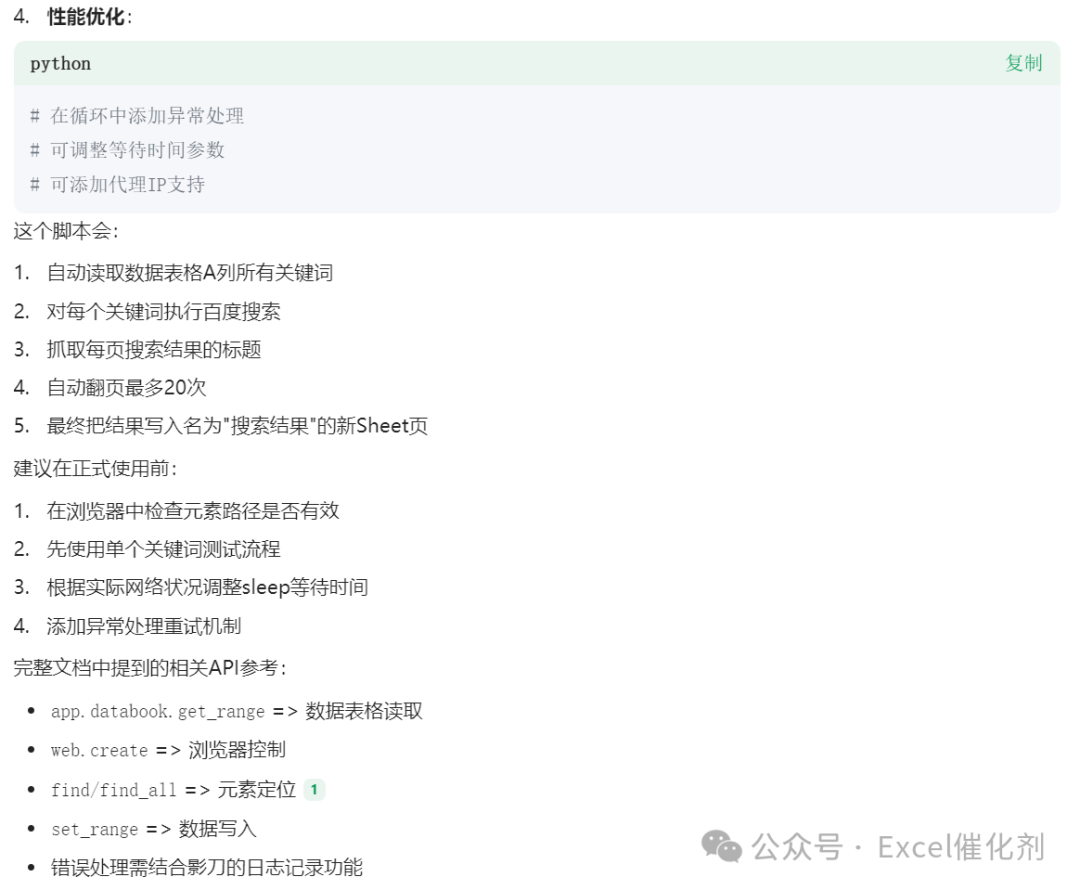
from xbot import web, appfrom xbot import sleepimport xbotdef main(args): # 1.读取Excel中的关键词(假设数据在A列) keywords = app.databook.get_range(1, 'A', 0, 'A') # end_row=0表示读取到最后 # 创建结果存储列表 all_results = [] # 2.遍历每个关键词 for keyword_row in keywords: keyword = keyword_row[0] # 取A列单元格内容 try: # 3.打开浏览器访问百度 browser = web.create("https://www.baidu.com", "chrome") # 4.输入关键词并搜索 search_input = browser.find('//input[@id="kw"]', by='xpath') # 百度搜索框[2](@ref) search_input.input(keyword) search_btn = browser.find('//input[@id="su"]', by='xpath') # 百度一下按钮 search_btn.click() sleep(2) # 等待搜索结果加载[1](@ref) current_page = 1 while current_page <= 20: # 控制翻页20次 # 5.提取本页搜索结果(示例:获取所有结果标题) results = browser.find_all('//h3[@class="t"]', by='xpath') # 标题元素 page_data = [] for result in results: try: title = result.get_text().strip() page_data.append([keyword, current_page, title]) except: continue # 存储到总结果 all_results.extend(page_data) # 6.翻页操作 try: next_btn = browser.find('//a[@class="n"]', by='xpath') # 下一页按钮[1](@ref) next_btn.click() sleep(3) # 等待新页面加载[1](@ref) current_page += 1 except: break # 翻页失败则终止当前关键词 # 关闭浏览器 browser.close() except Exception as e: print(f"处理关键词【{keyword}】时出错:{str(e)}") continue # 7.将结果写入Excel(写入新的Sheet) if len(all_results) > 0: app.databook.set_range( row_num=1, col_name='A', values=all_results, sheet_name='搜索结果' )if __name__ == '__main__': main(None)当然AI也给我贴心指导下注意事项
最后,为什么这么波折去用影刀编码版,设计器版不是很好用吗?
1、对于会写代码的人来说,设计器只是一时爽,不能一直爽,指令长了,各种修改参数很繁琐,虽然很多步骤打开设计器指令界面才能修改上。
2、调试也麻烦,很多参数在设计器界面看不到。
3、AI永远不能给我们做设计器的工作,但编码版就很擅长。
4、要想免费用好影刀RPA,编码版必须得上,最长30条指令的免费分享,使用设计器方式开发应用,想分享自己做的应用给其他人使用,几乎不可行。
有想使用本篇影刀RPA知识来玩玩AI写影刀代码的,可加我微信 19062897 过来体验一下。

















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









