






 本文介绍了正则表达式的基础概念及语法,包括普通字符、预定义字符、量词、定位符等元素,并提供了实例帮助理解。
本文介绍了正则表达式的基础概念及语法,包括普通字符、预定义字符、量词、定位符等元素,并提供了实例帮助理解。
一、概念
又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。(来自百度百科)
个人理解:regex就是一种描述,我更喜欢理解为自定义公式,满足该公式的字符串能够被筛选出来。
正则表达式练习网站:https://c.runoob.com/front-end/854/
二、正则表达式语法
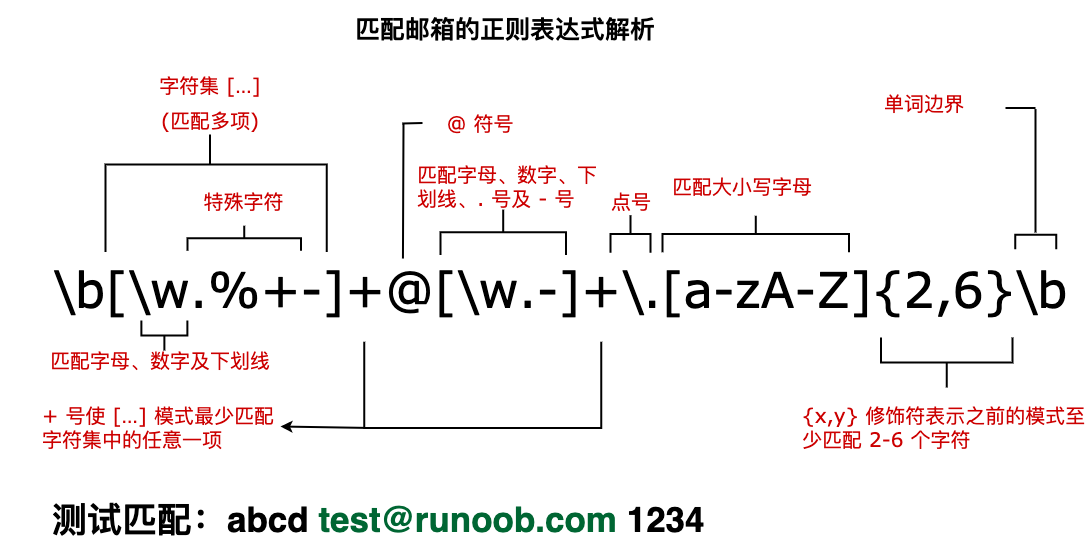
普通字符:包括所有大写和小写字母、所有数字、所有标点符 号和一些其他符号
例子
| 普通字符 | 含义 |
|---|---|
| [… ] | 字符组格式,默认必须从字符组中选一个字符,[]匹配中括号内列举的字符 |
| [ABC] | 表示这个字符可以是A或B或C,只要字符串中有A或B或C都可匹配出来 |
| [a-z] | 这个字符是a到z中任意一个字符 |
| [a-zA-Z0-9] | 这个字符是a到z A到Z 0到9中的任意字符 |
| [^abc] | ^字符在[ ]中括号里面可以理解为排除,意思是除了abc三个字符,可匹配其他任意字符 |
| 预定义字符:匹配单个字符 | 含义 |
|---|---|
| . | 匹配任意字符,除了换行符\n |
| \d | 匹配数字digit |
| \D | 大写的表示取反,匹配非数字 |
| \w | 匹配字母或数字或下划线 |
| \W | 大写表示取反,匹配非字母或数字或下划线 |
| \s | 匹配任意空白符space,包括换行\n |
| \S | 大写表示取反,匹配非空白符,不包括换行\n |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| 量词(限定符) | 含义 |
|---|---|
| ? | 匹配前面的子表达式0次或1次,或指明一个非贪婪限定符 |
| + | 匹配前面的子表达式1次或多次 |
| * | 匹配前面的子表达式0次或多次,即任意次 |
| {n} | 匹配前面的子表达式n次 |
| {n,} | 匹配前面的子表达式至少出现n次 |
| {n,m} | 匹配前面的子表达式出现n到m次 |
| .* .+ | 贪婪模式匹配 |
| .*? .+? | 非贪婪模式匹配 |
| 定位符 | 含义 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配 |
| \b | 匹配一个单词边界,即字与空格间的位置 |
| \B | 非单词边界匹配 |
| 注意 | 1:量词和定位符不可写一块 如 ^* 就是错的 2: ^不要和中括号[]中的 ^ 语法混淆 |
定位符例子
/ter\b/ 表示在单词结尾边界处匹配ter
/\bter/ 表示在单词开头边界处匹配ter
/\Bter/ 表示在单词中间部分匹配ter
| 分组 | 含义 |
|---|---|
| (exp) | 捕获分组,里面exp是正则表达式,系统会分配组号,并可通过组号引用该分组 |
| (?:exp) | 不捕获分组,可匹配,但没有组号,不可引用 |
| (?P<name>exp) | 命名分组,这是python中的写法,js中是 (?<name>) |
| \<name>和\n | 可通过这两个方式引用分组,n是组号1,2…,name是自己命名的组名,注意js中是通过$n来引用分组的 |
正则表达式的先行断言lookhead和后行断言lookbehindd的四种形式
1:(?=pattern) 正向先行断言
2:(?!pattern)负向先行断言
3:(?<=pattern) 正向后行断言
4:(?<!pattern)负向后行断言
个人理解:
1:这里的断言可以理解为位置跟^,$,\b这些定位符的作用有些相似,根据pattern模式找到位置,然后……嗯……我还是举例子吧。
例如字符串 helloworldhello
正则表达式
/hello(?=world)/的意思就是 匹配右侧位置是world的hello,
/hello(?!world)/的意思是 匹配右侧位置不是world的hello,
/(?<=world)hello/的意思是 匹配左侧位置是world的helllo,
/(?<!world)hello/的意思是 匹配左侧位置不是world的hello
2:关于先行和后行概念
可以简单的认为 从左到右的方向就是先行,从右往左的方向就是后行(?<=)和(?<!)中的<意思就是后行,从右往左的方向。
(当然先行和后行实际意思涉及到字符串匹配原理的问题,想弄清楚的可自行百度(手动doge))
正则表达式修饰符(标记)
概念
修饰符也称为标记,正则表达式的修饰符用于指定额外的匹配策略。
修饰符不写在正则表达式里,而是位于表达式之外,格式如下:
/pattern/flags
常用修饰符
| 修饰符 | 含义 |
|---|---|
| i | ignore缩写,意思是忽略大小写的差异,匹配时不区分大小写,A和a一样 |
| g | global缩写,全局匹配,查找所有的匹配项 |
| m | multi line缩写,多行匹配 |
| s | 特殊字符圆点 . 中包含换行符 \n,默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
额外补充
| 字符为替换,“或"操作字符具有高于替换运算符的优先级,使得"m|food"匹配"m"或"food”。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。

















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









