







一、添加Redis Connector依赖
具体版本根据实际情况确定
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
</dependency>
二、启动redis
三、编写代码
package com.lyh.flink06;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
public class SinkRedis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Integer> dataStreamSource = env.fromElements(1, 2, 3, 4, 5, 6);
KeyedStream<Integer, Integer> keyedStream = dataStreamSource.keyBy(new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer key) throws Exception {
return key.intValue();
}
});
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder()
.setHost("hadoop100")
.setPort(6379)
.setMaxTotal(100)
.setMaxIdle(10)
.setMinIdle(2)
.setTimeout(10*1000)
.setDatabase(0)
.setPassword("redis")
.build();
keyedStream.addSink(new RedisSink<>(conf, new RedisMapper<Integer>() {
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.SET);
}
@Override
public String getKeyFromData(Integer integer) {
return integer.toString();
}
@Override
public String getValueFromData(Integer integer) {
return integer.toString();
}
}));
env.execute();
}
}
可以根据要写入的redis的不同数据类型进行调整
四、查询结果
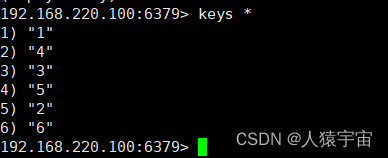
















 2684
2684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









